
刚刚,阿里官方认领神秘「欢乐马」,来自ATH郑波团队
刚刚,阿里官方认领神秘「欢乐马」,来自ATH郑波团队刚刚,这只爆火的「欢乐马」被认领了!是来自阿里巴巴 ATH 旗下郑波团队的模型,ATH 也就是不久前阿里刚成立的 AI 核心事业群 Alibaba Token Hub。阿里巴巴 ATH 表示:HappyHorse 是阿里 ATH 旗下创新事业部研发的模型,目前正处于内测中,也会于近期开放 API。
来自主题: AI资讯
9096 点击 2026-04-10 16:02
 搜索
搜索
刚刚,这只爆火的「欢乐马」被认领了!是来自阿里巴巴 ATH 旗下郑波团队的模型,ATH 也就是不久前阿里刚成立的 AI 核心事业群 Alibaba Token Hub。阿里巴巴 ATH 表示:HappyHorse 是阿里 ATH 旗下创新事业部研发的模型,目前正处于内测中,也会于近期开放 API。

最近,计算机视觉领域的顶级会议 CVPR 2026 的 NTIRE 鲁棒性 AIGC 图像检测挑战赛( Robust AI-Generated Image Detection in the Wild Challenge )结果出炉。蚂蚁集团 AI 安全实验室的队伍 MICV 凭借在鲁棒性测试样本上 ROC AUC 达到了惊人的 0.9723,成功摘得「复杂真实场景鲁棒性样本测试」挑战赛的冠军。

超快速 AI 生图领域再破性能天花板!香港科技大学唐靖团队、香港科技大学(深圳分校)胡天阳、小红书 hi-lab 罗维俭提出全新通用强化学习框架 TDM-R1,精准破解超快速扩散生成的核心痛点 —— 仅需 4 步采样(4 NFE),便将组合式生成指标 GenEval 从 61% 飙升至 92%,
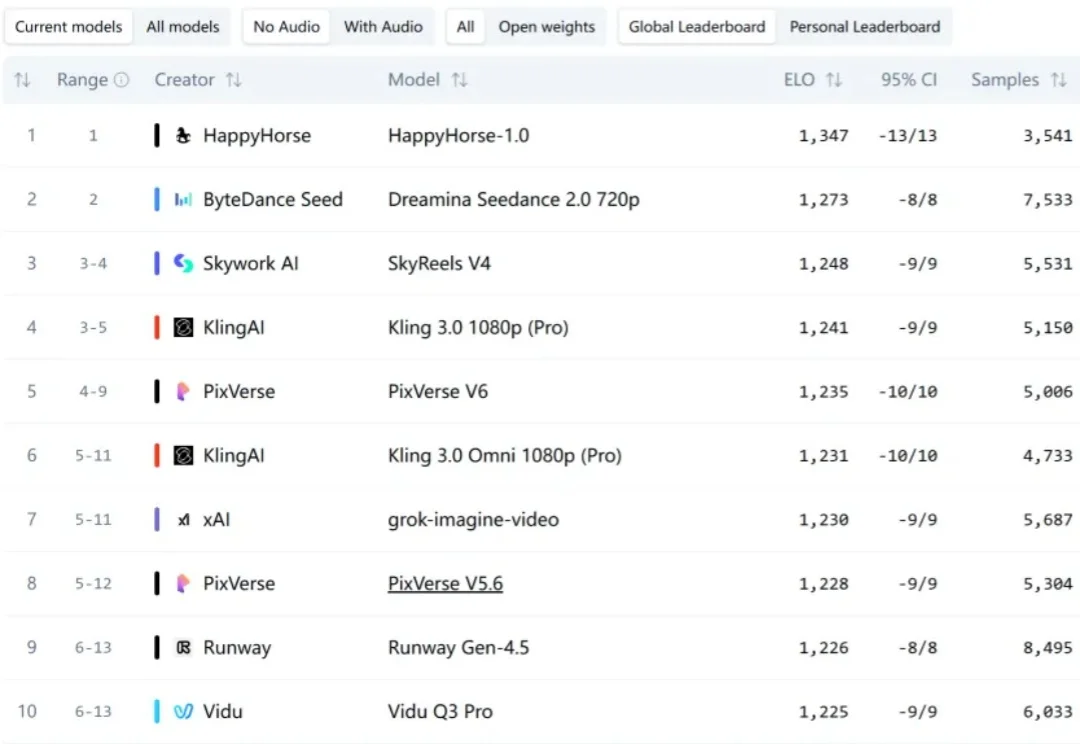
就在 OpenAI 都停了 Sora,所有人以为 Seedance 2.0 要一统天下的时候,没想到不知哪里冒出来一匹马。

Generalist AI的GEN-1热度,仍在发酵。

刚刚,Meta 重金组建的超级智能实验室(SML)交卷!这也是年轻华人 Alexandr Wang 带领该团队后,交出的首份成绩。全新自研模型 Muse Spark 上线。

全网震撼!《生化危机》女主跨界撸码,用Claude造出地表最强AI记忆系统,斩获全球首个满分。一年仅0.7美元,就能让大模型拥有永久记忆。

近日,OpenAI Codex 产品负责人Alexander Embiricos和OpenAI 的开发者体验(Developer Experience)负责人Romain Huet 一起做客播客,聊了不少 Codex 背后的故事。

LangChain 只换了模型外面的基础设施——同一个模型、同一套权重——就从 TerminalBench 2.0 排行榜 30 名开外直接跳到了第 5 名。另一个独立研究项目让大模型自己优化这层基础设施,达到了 76.4% 的通过率,超过了所有人工设计的方案。
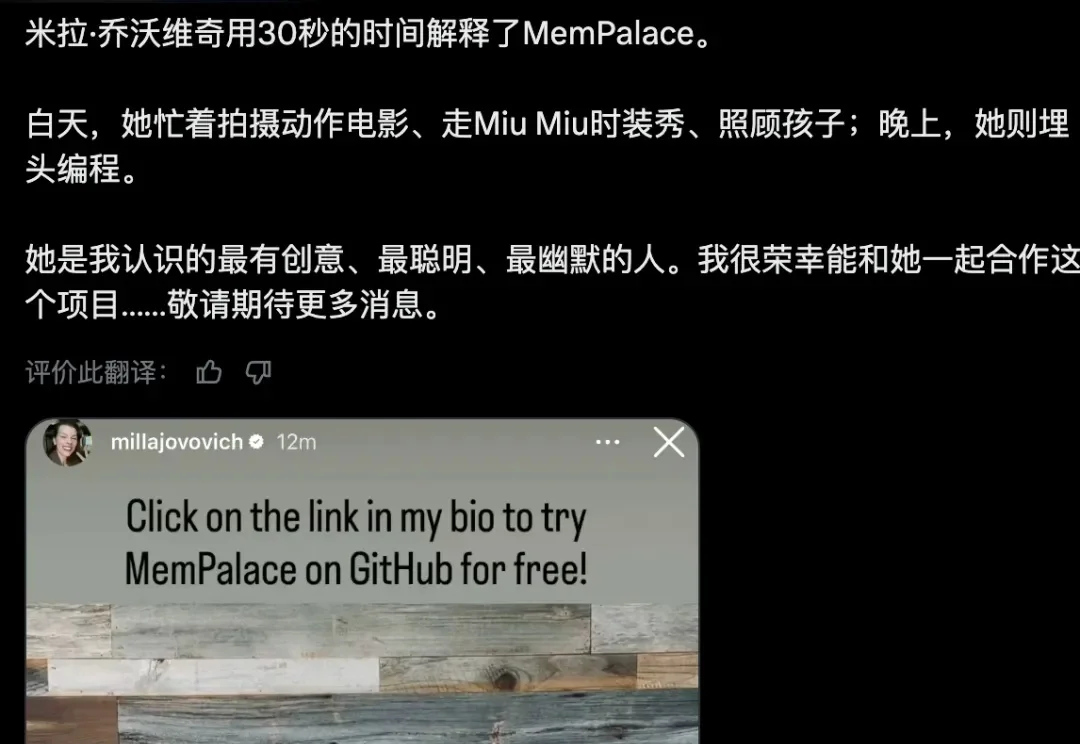
今天在榜单上看到一个项目: