为什么Google Ventures砸5200万赌这家AI-Native的CRM公司能干掉Salesforce?
为什么Google Ventures砸5200万赌这家AI-Native的CRM公司能干掉Salesforce?Attio 刚刚完成了 5200 万美元的 B 轮融资,由 Google Ventures 领投,他们的使命很简单也很激进:彻底重新发明 CRM,让它真正为 AI 时代而生。
来自主题: AI资讯
8500 点击 2025-09-01 11:47
 搜索
搜索
Attio 刚刚完成了 5200 万美元的 B 轮融资,由 Google Ventures 领投,他们的使命很简单也很激进:彻底重新发明 CRM,让它真正为 AI 时代而生。
两年半股价暴涨25倍,Palantir仍是企业级AI无出其右的领导者,甚至目前都找不出一家竞品。我们频道聚集了很多关注Palantir的朋友,大家问的最多的问题是:国内有没有真能对标Palantir的公司?

从Llama 4「作弊刷分」丑闻,到143亿美元收购Scale AI,扎克伯格疯狂挖角,却换来团队内讧;上亿美元年薪,没能留住顶尖人才。Meta的超级智能实验室(MSL),到底是未来引擎,还是人心崩盘的深坑?
当大多数人还在抱怨传统工单系统的笨重时,一家叫做 Pylon 的公司却在短短18个月内完成了从种子轮到B轮总计5100万美元的融资,估值飙升至8亿美元。更令人震惊的是,他们已经吸引了780多家快速增长的公司,包括 Together AI、Cognition 和 Temporal,其中超过150家公司主动从 Zendesk、Intercom 等老牌平台迁移过来。
他曾是Ilya的亲信,因揭露OpenAI安全隐患被解雇,却在短短6个月内以47%回报打造出管理规模15亿美元的基金。作为AI安全激进派,他在165页论文《Situational Awareness》中预测2027年将迎来AGI,并呼吁建立「AI版曼哈顿计划」。
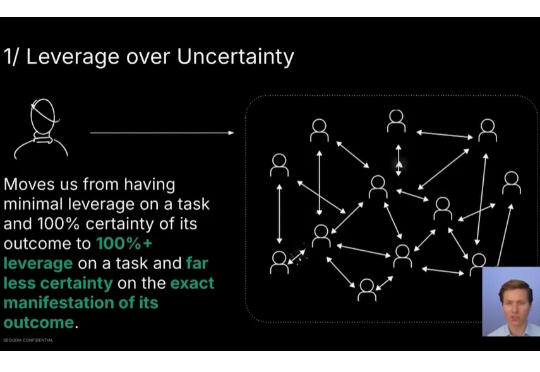
红杉资本(Sequoia Capital)最近分享了他们未来对 AI 领域的投资判断。 在他们看来,AI 革命将是一场堪比工业革命的变革。我们正处在一场深刻的「认知革命」 (Cognitive Revolution) 的重要发展阶段,这其中蕴含着高达 10 万亿美元的机遇。

这位乒乓球场上的机器人高手,出自清华姚班本科生苏智(师从吴翼教授)的最新论文——《HITTER: A HumanoId Table TEnnis Robot via Hierarchical Planning and Learning》。

OpenAI凌晨发布最新生产级别语音模型和API。Realtime API实现语音直接处理,支持图像输入、远程MCP服务器与SIP打电话,极大简化语音智能体构建;而新一代语音到语音模型gpt-realtime,在音质、理解力、指令遵循和函数调用上全面提升,语音几乎媲美真人,还能多语种切换与细腻表达。

本月初,AI 圈翘首以盼的 GPT-5 终于问世,在数学、实际编程、多模态理解、推理等多个领域实现了新的 SOTA。今日,国产 AI 厂商元石科技重磅推出「All in One」旗舰模型 —— 问小白 5,成为其迄今为止最智能、最快捷、最实用的 AI 系统。尤其值得强调的是:问小白 5 的各项基准测试榜单成绩最接近 GPT-5,这使其成为当前国产大模型中最具代表性的对标者。

亏也AI,盈也AI。 港股运动科技第一股,在今年2月决定“All in AI”后,终于等来了自己关乎方向的胜利—— 全国最大健身平台Keep,最近发布了今年上半年的财报,宣布公司已经扭亏为盈,实现经调整净利润为1035万元。