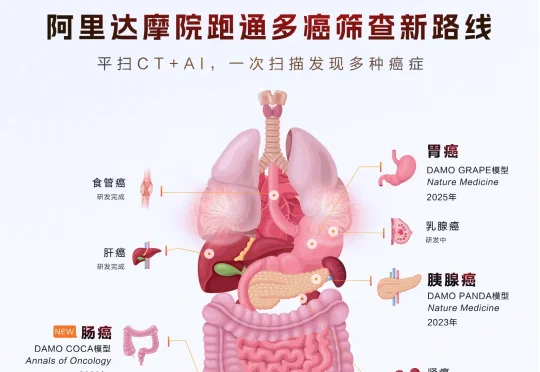
三年连下三癌,阿里AI模型DAMO COCA跑通了多癌筛查
三年连下三癌,阿里AI模型DAMO COCA跑通了多癌筛查医生说平扫CT上看不见癌——AI找到了。 2021年5月,一位患者因突发腹痛被推进急诊,拍了一张平扫CT。 影像报告出来了——没有提及肠道有问题。 两年后,这位患者做了肠镜。确诊肠癌。肿瘤已经明显增大
来自主题: AI资讯
9422 点击 2026-04-28 13:18
 搜索
搜索
医生说平扫CT上看不见癌——AI找到了。 2021年5月,一位患者因突发腹痛被推进急诊,拍了一张平扫CT。 影像报告出来了——没有提及肠道有问题。 两年后,这位患者做了肠镜。确诊肠癌。肿瘤已经明显增大
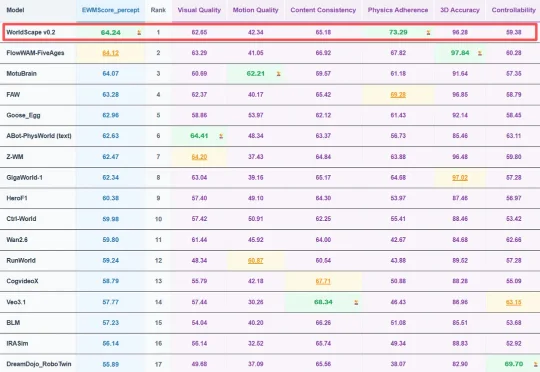
近日,全球具身世界模型权威基准评测 WorldArena 正式更新最新榜单。Manifold AI 流形空间研发的世界模型 WorldScape 0.2,凭借其在物理规律遵循与多源交互理解上的突破取得 WorldArena 榜单全球第一,充分展现了国产世界模型在复杂动态场景生成与具身控制中的高精度、强泛化与物理可信度。与其同场竞技的包括英伟达、谷歌等国外巨头和星动纪元、极佳视界等国内具身智能公司。

机器之心编辑部 ICLR 2026 获奖论文已经公布。 今年共有 2 篇论文获得「杰出论文奖」(Outstanding Paper),另有 1 篇论文获得「荣誉提名」(Honorable Mention);此外,还有 2 篇 ICLR 2016 论文获得「时间检验奖」(Test of Time Award)。
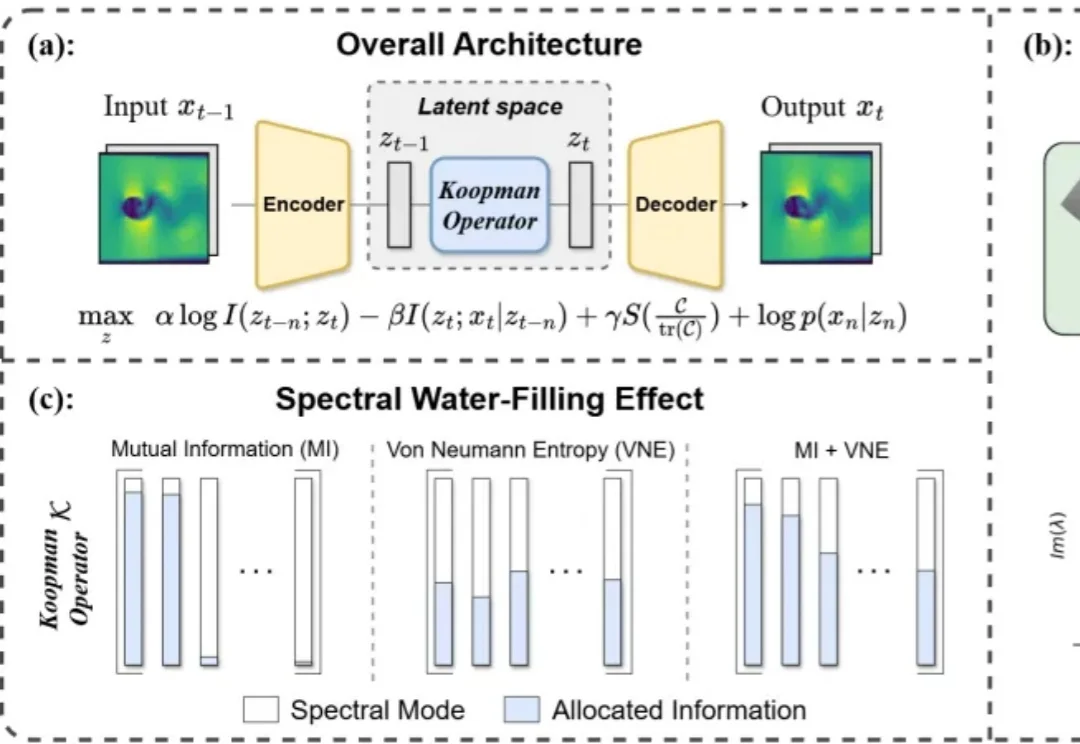
大多数世界模型工作默认:只要学到一个好的 latent dynamics,问题就解决了。 但这个假设本身是可疑的——什么样的信息,才足以支撑一个可预测、可传播的动力学? 本文从信息论出发,重新审视这一前提。

前几天,Anthropic 开源了 claude-desktop-buddy,用一块小屏幕显示 Claude Code 里 Buddy 的状态。结果做着做着,它变成了一个完全不同的东西:M5 Paper Buddy (https://github.com/op7418/m5-paper-buddy)。

4 月初,LM Arena 评测平台上出现了三个匿名图像模型,代号分别是 maskingtape-alpha、packingtape-alpha、gaffertape-alpha。几小时后它们消失了。OpenAI 官方还没有正式宣布这个模型,但根据 API 返回的元数据和用户侧的测试记录,它已经有了一个被广泛接受的名字:GPT Image 2。

试想一下,如果把当下大火的大模型技术带回 1970 年,会发生什么?
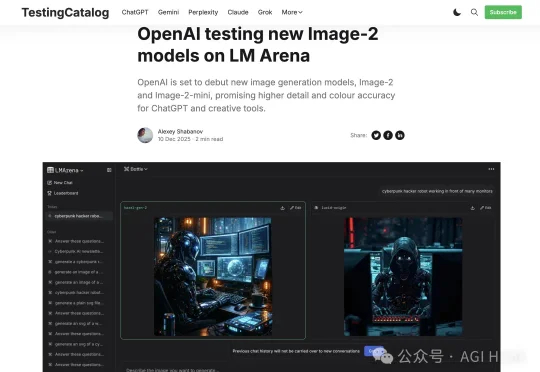
OpenAI 的下一代图像模型 GPT-Image-2,今天在 Chatbot Arena 上被人发现了。独立开发者 levelsio 率先爆料,这个模型以三个代号悄悄上线了 Arena:maskingtape-alpha、gaffertape-alpha、packingtape-alpha。
通用世界模型评测榜单 WorldScore 登顶、建立具身世界模型评测榜单 WorldArena 、发布通用世界模型 WorldScape 、发布世界-动作模型 WorldScape Policy,这家低调的世界模型创业公司 Manifold AI(流形空间)近期走出隐身模式频频出手,开始领跑世界-动作模型具身新路线。

如果把科研流程整体交给智能体执行,会发生什么?