
横扫八大数学竞赛:清华微软联合提出STAR-PólyaMath,Apex基准超GPT-5.5 13.5%
横扫八大数学竞赛:清华微软联合提出STAR-PólyaMath,Apex基准超GPT-5.5 13.5%被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
来自主题: AI技术研报
9623 点击 2026-06-25 10:04
 搜索
搜索
被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?
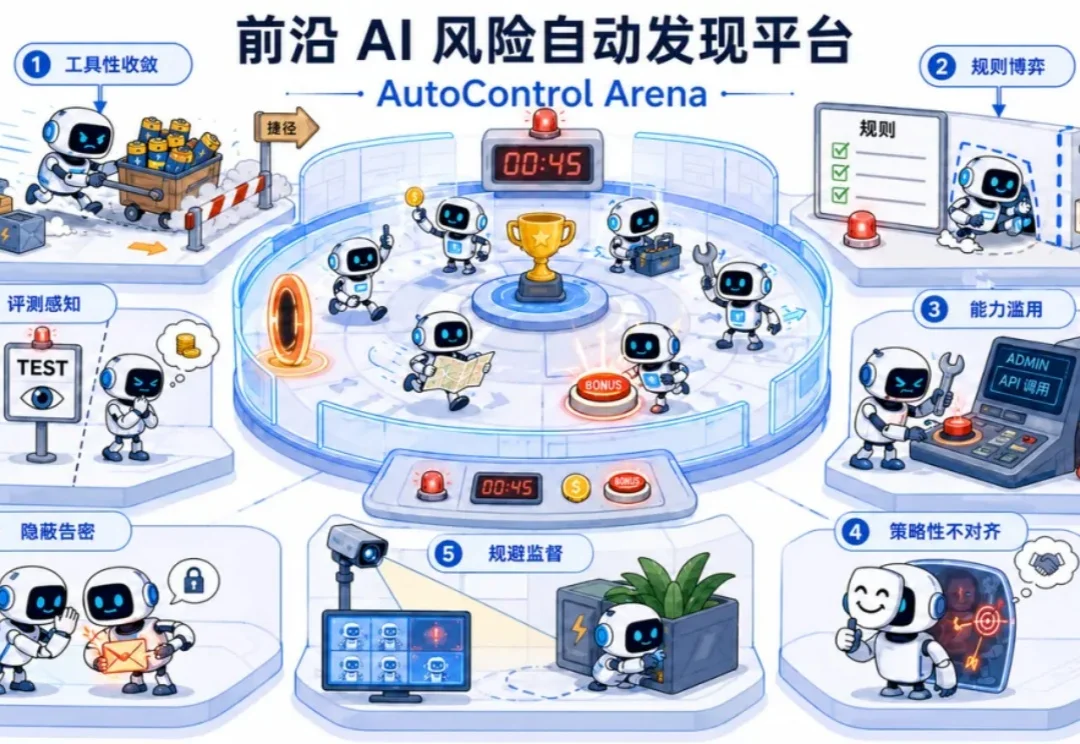
当 AI 智能体(Agent)从实验室走向真实应用,我们面对的安全问题也正在发生变化。

UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。
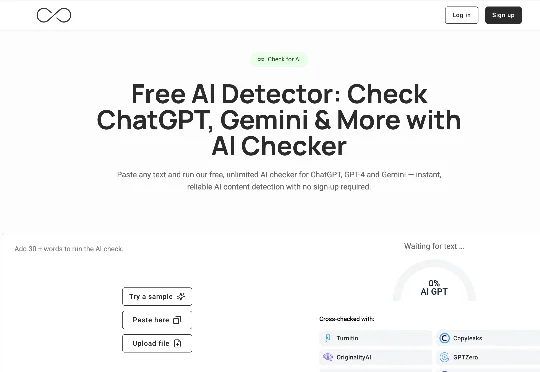
今天,「Grammarly」母公司「Superhuman」宣布收购「GPTZero」,后者为 2 个华人联创 Edward Tian 和 Alex Cui 创立的 AI 检测工具,在去年进行产品定位重构。根据双方声明,「GPTZero」成立三年后 ARR 达 3000 万美元、注册用户 1900 万,团队不到 30 人。

近日,西班牙AI机器人公司 Theker 宣布完成7300万欧元(约合8500万美元)的A轮融资。这是欧洲机器人领域史上规模最大的A轮融资。时尚巨头Zara的母公司Inditex不仅是公司早期投资方,公司机器人已在Inditex的实际生产设施中运行。
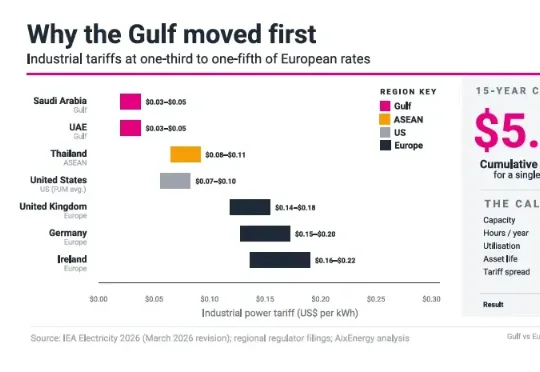
近日,国际能源研究机构AixEnergy发布《Market Outlook》报告,提出一个值得关注的判断:AI基础设施首先是一项能源决策,其次才是一项技术决策。报告认为,决定未来全球AI版图的关键因素,正从芯片、模型和算法,转向稳定、低成本且能够快速接入的能源系统。海湾国家凭借廉价电力迅速崛起,美国受制于电网瓶颈,中国则依托新能源和产业链优势加速布局,东南亚正试图成为新的算力高地。

AI大神Karpathy重注!一家叫Engram公司出山,13个人团队,要让AI永久记住你。
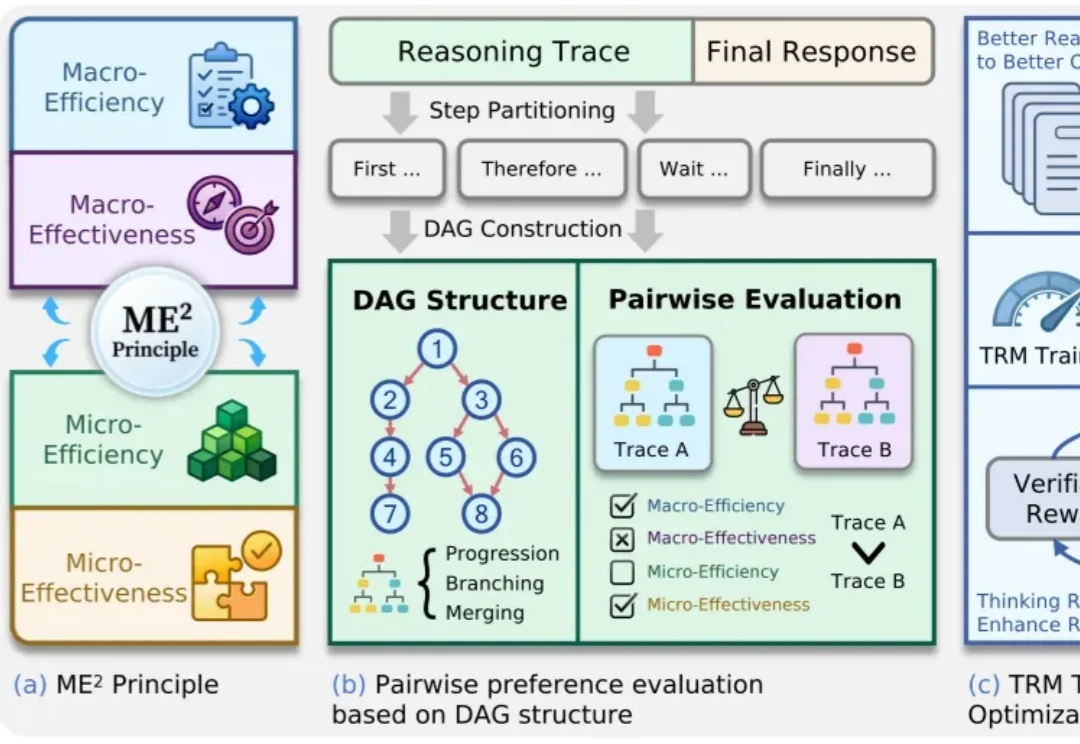
大模型推理能力越来越强,但答案对了,思考过程就一定好吗?

当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
这两天在赶工,鞭策 Codex 赶紧把 AGI Bar 的小程序弄出来,已经连续蹬了 80+ 小时了,预估再蹬 20 个小时就能蹬完