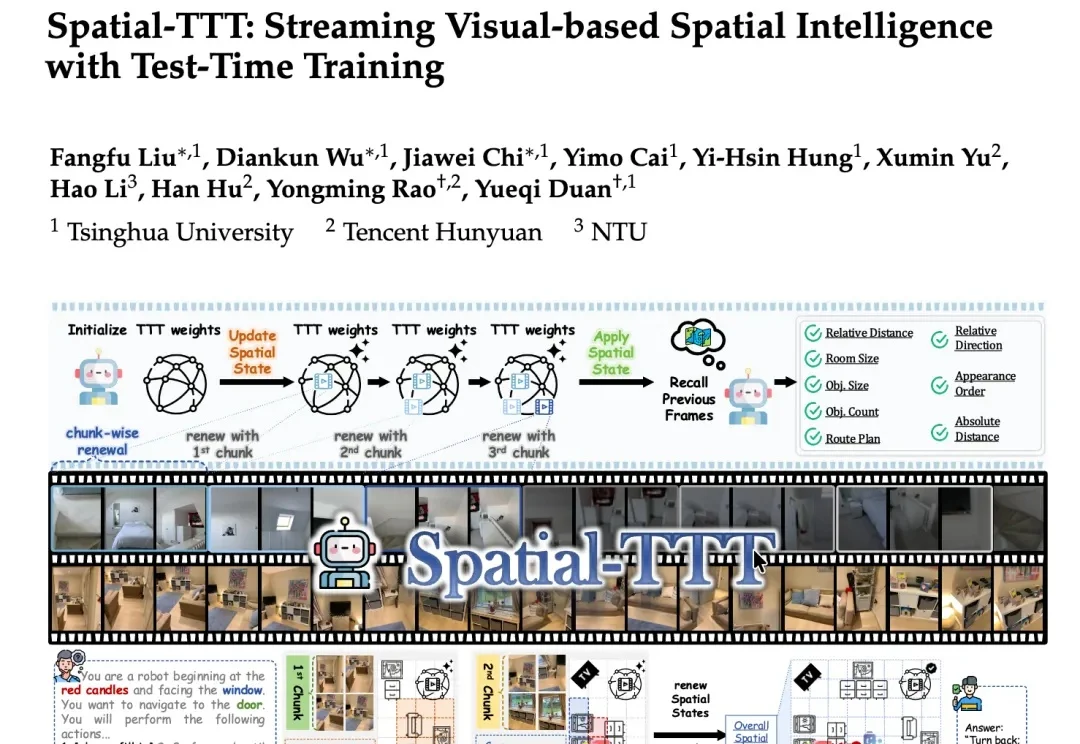
入选ECCV 2026!清华开源空间模型打败Gemini:真正的空间智能是在世界变化中持续学习
入选ECCV 2026!清华开源空间模型打败Gemini:真正的空间智能是在世界变化中持续学习在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。
来自主题: AI技术研报
6137 点击 2026-06-22 15:16
 搜索
搜索
在机器人、自动驾驶、AR等真实场景中,空间理解从来都不是“看一眼图像”就能解决的问题。

2026年的AI视频生成赛道,已经拥挤到连空气都变得稀薄。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。
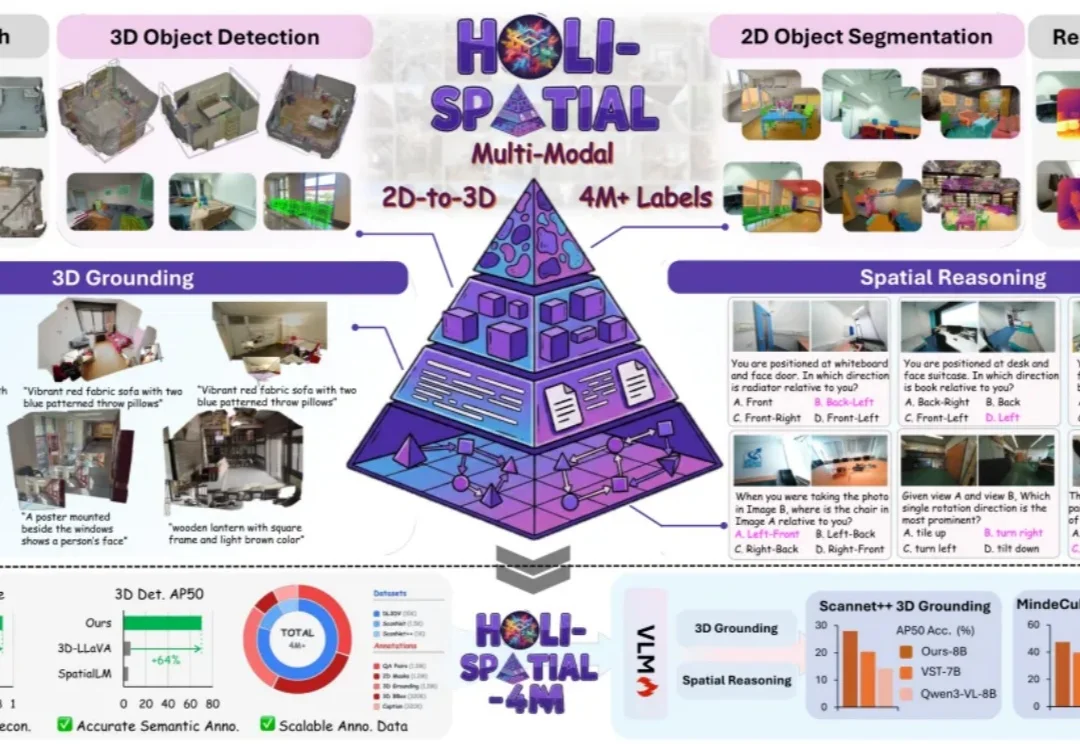
从原始视频出发,无需人工介入,自动生成 3D 重建、深度、2D mask、3D 框、实例描述、3D grounding 和空间问答。Holi-Spatial 试图把「空间智能」的数据生产,推进到自动化、可扩展的新阶段。

刚刚,外媒The Information援引两位知情人士报道,爆款通用Agent产品Manus的早期中国支持者,计划掏出20亿美元(约合人民币135亿元),向Meta回购该公司。
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。

随着大语言模型逐步从「单轮问答」走向「真实环境中的持续交互」,LLM agents 正在被用于越来越复杂的 agentic applications:deep research、coding、computer use、customer service、medical inquiry、troubleshooting 等等。

刚刚,据外媒The Information援引两名知情人士报道,DeepSeek近期已完成成立以来的首轮外部融资,募资总额超500亿元人民币(折合74亿美元),本轮融资采用特殊交易架构。这是中国AI行业迄今规模最大的单轮融资。

前阿里 Qwen 技术负责人林俊旸的创业公司,有了新消息。据外媒 The Information 援引知情人士的消息,在林俊旸完成的首轮融资中,腾讯投资了 2000 万美元。本轮融资总额达数亿美元,投后估值约 20 亿美元。

就在昨天,外媒The Information爆料——前阿里巴巴千问大模型负责人林俊旸创办的AI实验室已经完成首轮融资,融资总额达数亿美元,投后估值达20亿美元!其中,红杉中国、高榕资本各投1亿美元领投,互联网巨头腾讯狂掷2000万美元跟投。