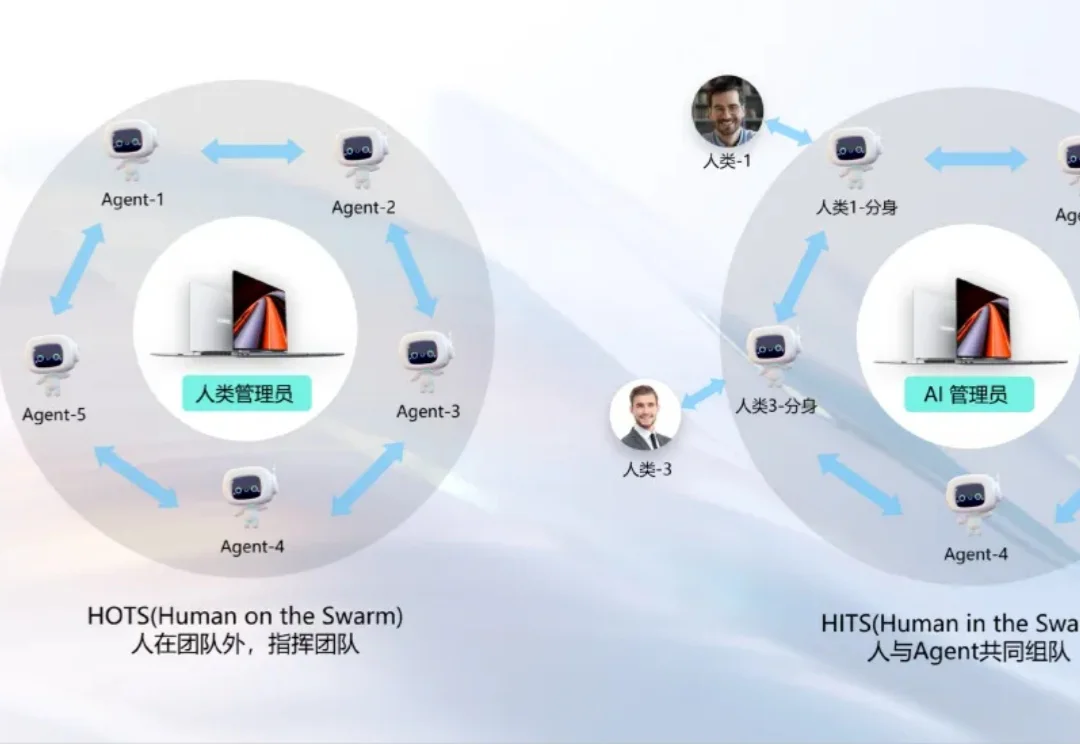
首个鸿蒙PC开源AI统一工作台JiuwenSwarm,办公编程一站式搞定
首个鸿蒙PC开源AI统一工作台JiuwenSwarm,办公编程一站式搞定鸿蒙PC用户终于不用再等。
来自主题: AI技术研报
10156 点击 2026-07-29 14:02
 搜索
搜索
鸿蒙PC用户终于不用再等。

采访中,吴英成把自己正在做的事压缩成一句话:“上一代 AI 蒸馏的是互联网,下一代 AI for Science 应该‘蒸馏地球’。”

是时候讨论一下 AI 的 “第三极”—— 社会智能了。
当 “花钱” 这事儿开始外包给 AI,这个世界将发生什么变化?

大规模视频扩散模型,画面越来越真,却总在“物理定律”上栽跟头。
在真实工业环境中,数据并不是静止不变的。
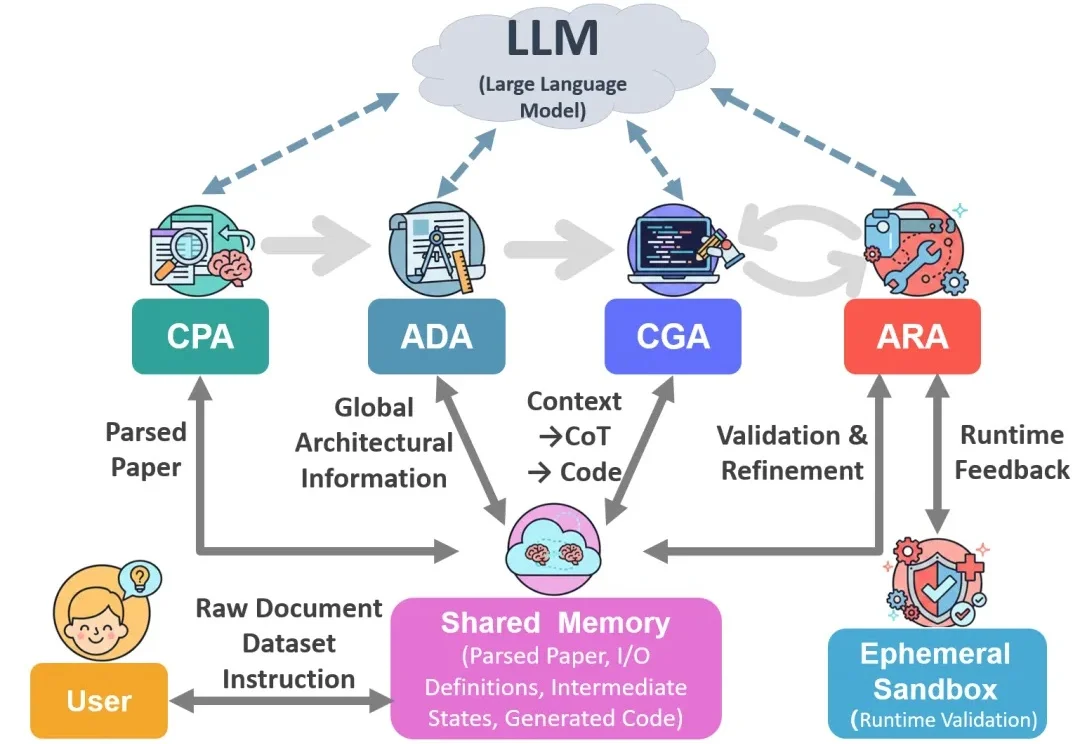
随着网络系统研究复杂度的提升,研究结果复现通常需要研究人员依据论文描述重新实现完整系统。

7月28日,一份来自硅谷名为Pacing the Frontier的公开声明发布。
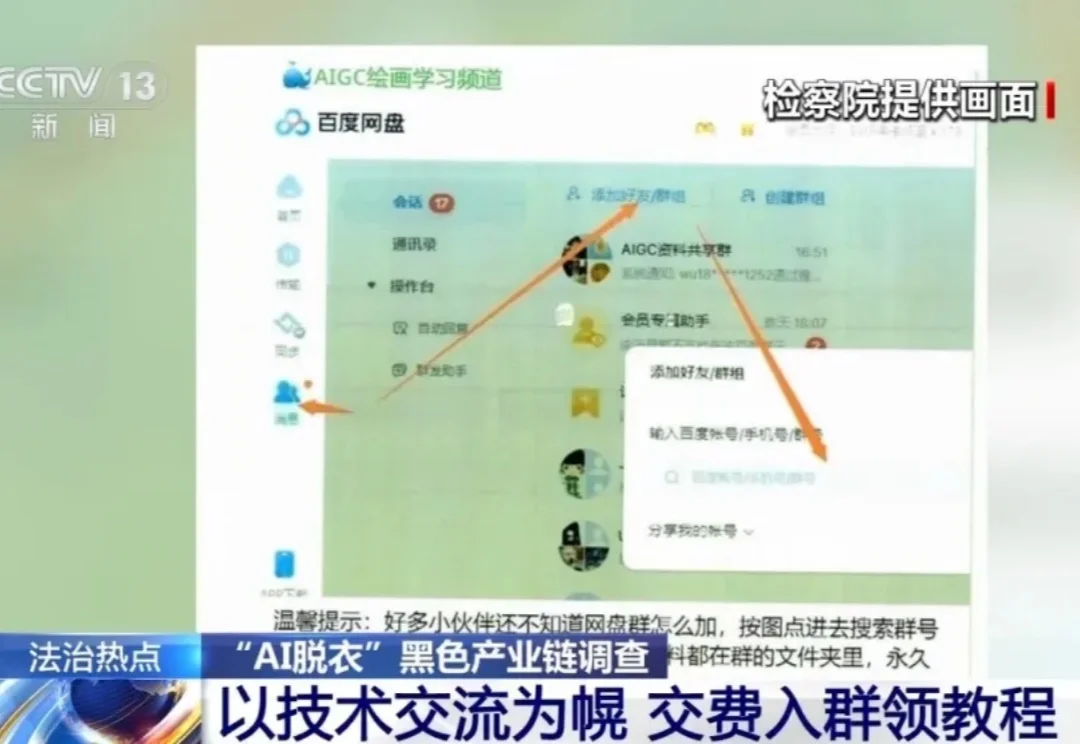
“AI合成”技术现已渗透进我们的网络生活。技术本无罪,但在一些别有用心的人手中,它却沦为新型犯罪的帮凶。

过去两年,光是洛杉矶就蒸发了四万多个影视岗位。美国的报纸采编岗比2008年少了一半。这些消失的媒体人,有一批去了硅谷的大模型公司,用他们的写作经验教AI回答你的问题。每当你感到被大模型的回答击中内心的时候,写出来那句话的,就是之前的记者、编辑和纪录片导演。