
万字解读:为何长上下文治不了多模态 AI 的「健忘症」?丨GAIR Live 031
万字解读:为何长上下文治不了多模态 AI 的「健忘症」?丨GAIR Live 031多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。
来自主题: AI资讯
5631 点击 2026-06-12 10:03
 搜索
搜索
多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。

陶哲轩又发成绩单了。

前阵子有张梗图,在 AI Agent 圈子里火了:
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。
GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气:
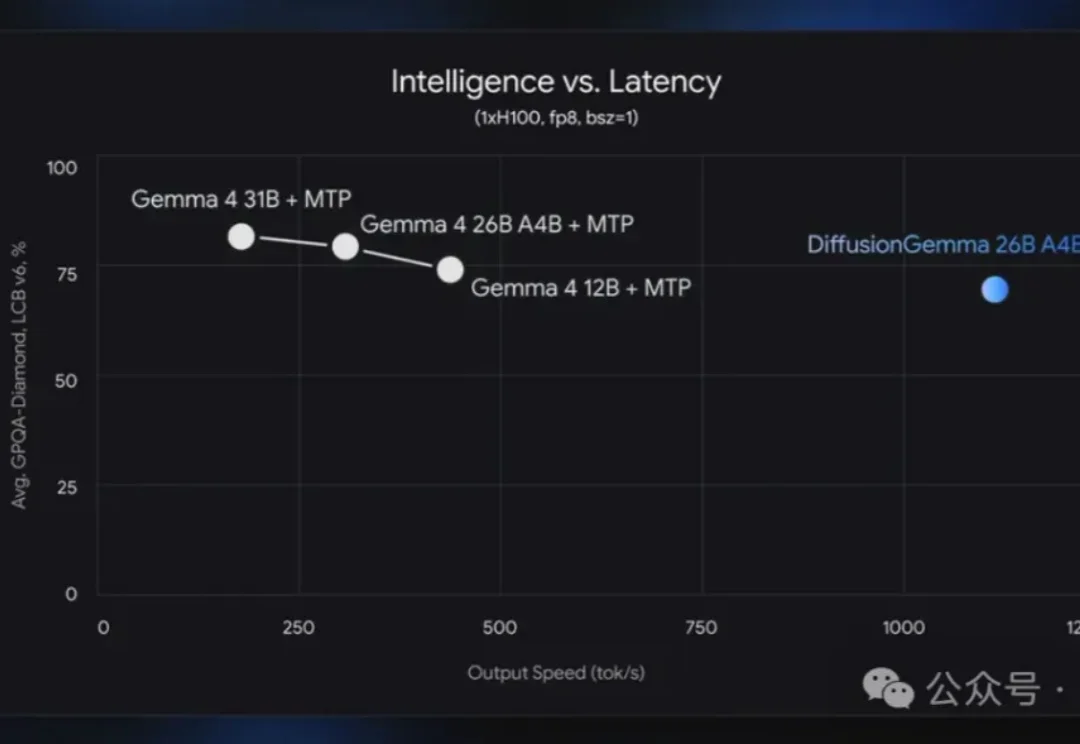
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——

这段时间以来,Codex 在社交媒体上是好评如潮。

在3D创作这个圈子,一直有个心照不宣的扎心真相: 那就是最难的一步从来不是生成,而是让模型变为可用资产。