
独家|做过两个百万DAU AI Native产品,字节又一位产品负责人离职创业
独家|做过两个百万DAU AI Native产品,字节又一位产品负责人离职创业据多方信息交叉显示,字节Flow部门AI产品负责人西原已于近期离职,在上海开始AI创业,据信创业方向仍聚焦AI内容/社交领域。
来自主题: AI资讯
7721 点击 2026-06-11 10:46
 搜索
搜索
据多方信息交叉显示,字节Flow部门AI产品负责人西原已于近期离职,在上海开始AI创业,据信创业方向仍聚焦AI内容/社交领域。
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。
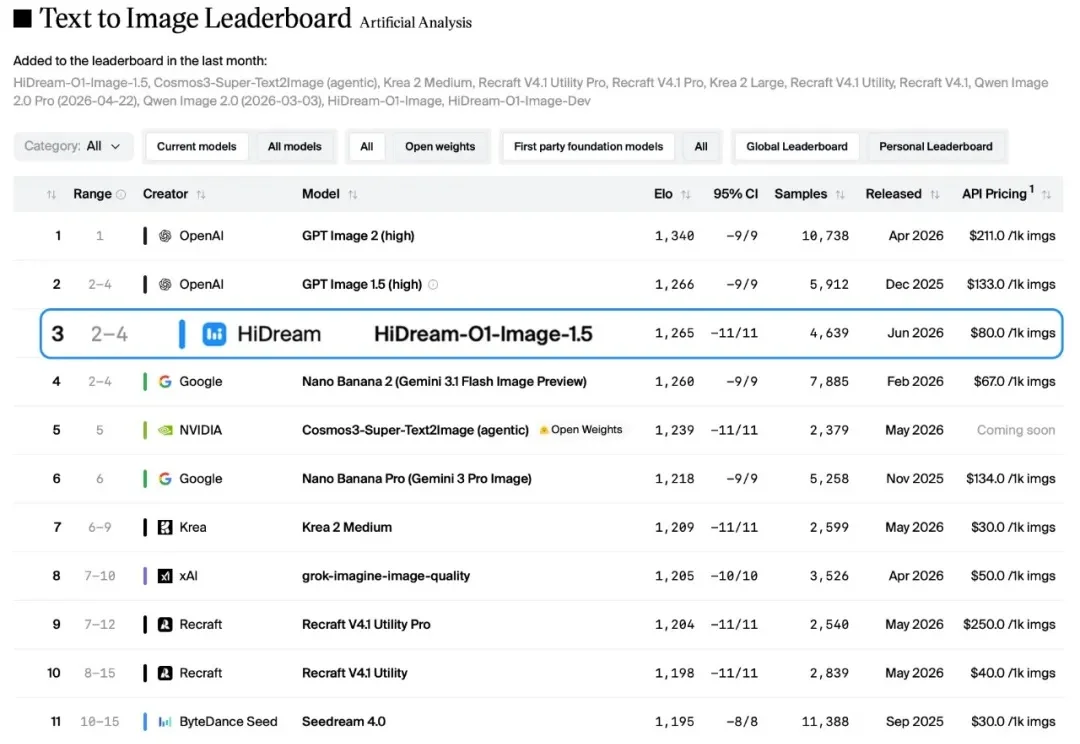
文生图的"慢思考",到底有没有用?

今年春节后,一位消失许久的西班牙客户突然回来找老班。

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。
不聊概念,4 个真实工作场景跑一圈
想象一下,你问 AI 要一个饮食记录工具,它不再是回你一段文字建议,而是直接给你一个可以点击添加、统计热量的完整应用。人和 AI 的交互,正在从「读文字」走向「用应用」。

2007 年,乔布斯用一块 3.5 英寸的屏幕,将人类的信息交互折叠进了一个发光的二维平面。

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一

硬氪获悉,广州市题渊网络科技有限公司(以下简称“题渊科技”)已于近日完成近千万元天使轮融资,投资方为宏泰智慧谷,本轮资金将主要用于市场推广和教育 agent 平台的持续技术研发。