
DeepSeek V4做数学证明,500倍成本优势:智能体系统刷新多项纪录
DeepSeek V4做数学证明,500倍成本优势:智能体系统刷新多项纪录近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
来自主题: AI技术研报
8332 点击 2026-06-07 10:56
 搜索
搜索
近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。
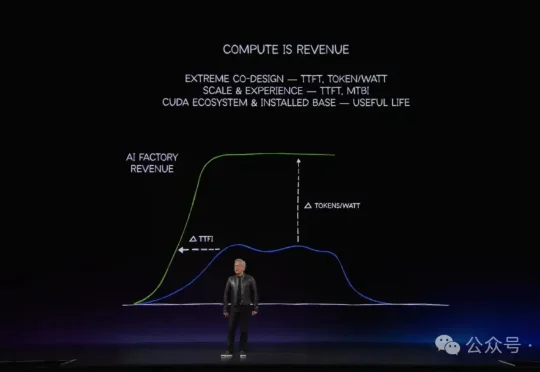
6月1日,在英伟达GTC舞台,黄仁勋聊AI工厂,聊智能体,反复念叨的也是这个Token:算力就是收入,算力就是利润。没有收入和利润,就是亏损。一座AI工厂这辈子能赚多少钱,看的就是它总共产出多少Token,也就是曲线下方的面积。一句话:谁能更快、更省电、更稳定地生产Token,谁就赚得多。
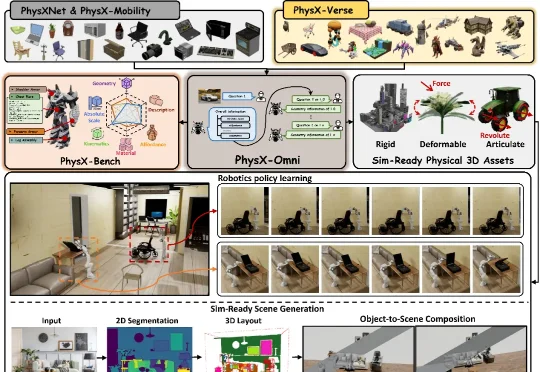
该论文第一作者为曹子昂,研究方向主要聚焦于 3D AIGC、Physical AI 与具身智能。论文主要合作者包括来自南洋理工大学的李海天、姚润茂、洪方舟、陈昭熹,以及大晓机器人的刘英豪和潘亮。通讯作者为南洋理工大学刘子纬教授。
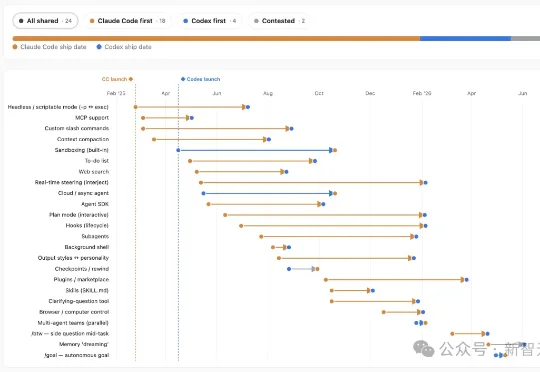
Codex和Claude Code长得越来越像了!最近,开发者Elie Bakouch感到Claude Code和Codex的功能越来越像,他好奇到底哪家在领跑,于是就把两家都有的功能做成了一张时间线。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

它不同于我们认知中传统的「学术机构」or「创业公司」。它要在同一个屋顶下,同时扛住四件事:科学路径是否成立、工程能不能跑通、市场有没有人买单、资本能不能撑到关键节点。硅谷现在有个非正式叫法:Neo Labs。

奥特曼官宣ChatGPT记忆重大升级!全新Dreaming V3架构正式上线:ChatGPT会在后台「做梦」,首次向数亿免费用户开放。这一次升级,「做梦」功能向十亿人免费开放,Plus和Pro记忆容量直接翻倍。

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。

在人工智能与体育产业深度融合的浪潮中,高尔夫这项传统运动正迎来一场由“物理AI”驱动的技术革命。近日,专注于高尔夫运动科技创新的XintLabs宣布完成数千万元天使轮融资,由高瓴创投独家投资。资金将主
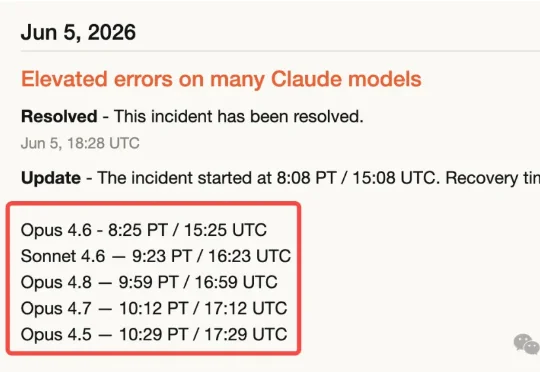
就在昨天,Anthropic 的官方状态页突然挂起一排刺眼的红灯——Claude API、Claude Code、Claude.ai、Claude Cowork……几乎所有核心服务,突然大面积宕机。从 Opus 4.6 到 Opus 4.8,五大模型无一幸免。