

音频秒生全身虚拟人像,AI完美驱动面部肢体动作!UC伯克利Meta提出Audio2Photoreal
音频秒生全身虚拟人像,AI完美驱动面部肢体动作!UC伯克利Meta提出Audio2Photoreal最近,来自Meta和UC伯克利的研究人员,发布了一种最新的音频到人像模型。操作简单,输出极致逼真。
来自主题: AI技术研报
9581 点击 2024-02-05 14:19
最近,来自Meta和UC伯克利的研究人员,发布了一种最新的音频到人像模型。操作简单,输出极致逼真。

在日前召开的第四届中国短视频大会“主流媒体短视频创新传播”分论坛上,中央广播电视总台创新发展研究中心新媒体研究部主任黎斌,带来了《AI技术重塑短视频市场的八大趋势》为题的主旨发言。

视频生成还可以这么玩?来一个“火柴人”做做动作示范,再加文本描述,即可让各种形象惟妙惟肖地跟着动起来。

多模态大模型将是AI下一个爆点。最近,通义千问VLM模型换新升级,超大杯性能堪比GPT-4V。最最重要的是,还能限时免费用。

谷歌一出手,又把AI视频生成卷上了新高度。

爆肝7个月,谷歌祭出了AI视频大模型Lumiere,直接改变了游戏规则!全新架构让视频时长和一致性全面飞升,时长直接碾压Gen-2和Pika。

Pika北大斯坦福联手,开源最新文本-图像生成/编辑框架!

AI 视频生成,是最近最热门的领域之一。各个高校实验室、互联网巨头 AI Lab、创业公司纷纷加入了 AI 视频生成的赛道。Pika、Gen-2、Show-1、VideoCrafter、ModelScope、SEINE、LaVie、VideoLDM 等视频生成模型的发布,更是让人眼前一亮。
Stable Diffusion要王者归来了?
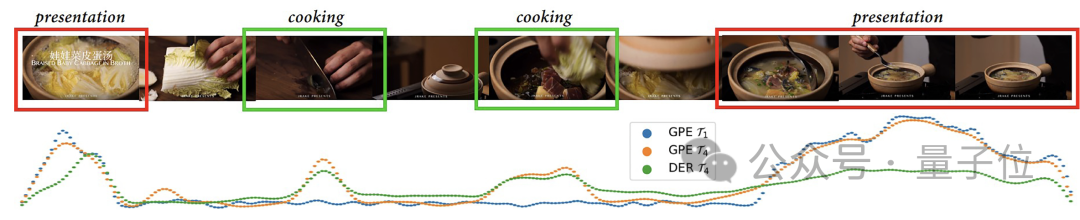
字节跳动联合中科院自动化研究所提出新方法,用AI快速检测出视频中的高光片段,对输入视频的长度以及期望提取的高光长度都具有极高的灵活性,相关论文已被AAAI 2024收录。