

一文详解:DeepSeek 第五天开源的 3FS 文件系统
一文详解:DeepSeek 第五天开源的 3FS 文件系统DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。
来自主题: AI技术研报
8208 点击 2025-02-28 11:33
DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。

DeepSeek开源周,今日正式收官!内容依旧惊喜且重磅,直接公开了V3和R1训练推理过程中用到的文件系统。Fire-Flyer文件系统(简称3FS,第三个F代表File),一种利用现代SSD和RDMA网络的全部带宽的并行文件系统;

哈尔滨工业大学团队提出HEROS-GAN技术,通过生成式深度学习将低成本加速度计信号转化为高精度信号,突破其精度与量程瓶颈。该技术利用最优传输监督和拉普拉斯能量调制,使0.5美元的传感器达到200美元高端设备的性能,为工业、医疗等领域应用带来变革。
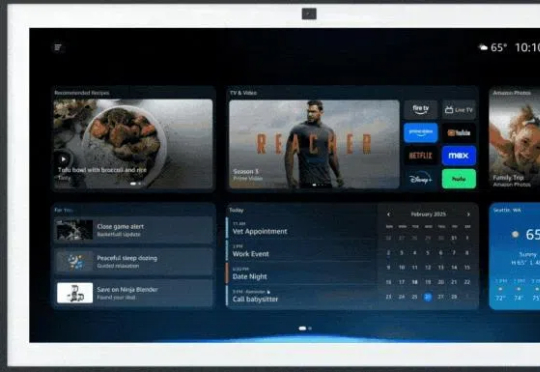
11年来首次重大更新,Alexa要打造终极智能家居体验?升级后的Alexa被叫做Alexa+,可以与用户自然对话,还能记住家庭不同成员的个人习惯提供个性化建议,完成制定旅行计划、提炼邮件重点等各种复杂的任务。彭博社知名记者马克·古尔曼将Alexa+称作“加强版的ChatGPT语音模式”,令人印象深刻。他还提到苹果在这个领域落后了很远。
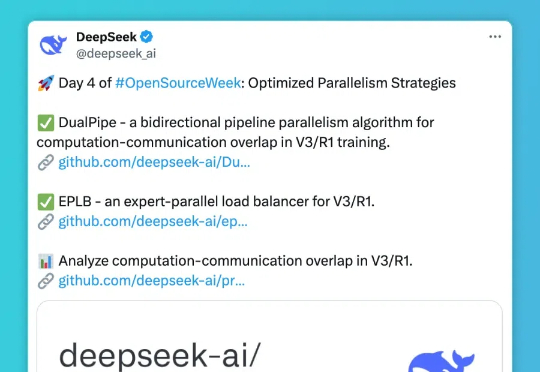
第四天,DeepSee发布包括三个主要项目: DualPipe- 一种用于 V3/R1 训练的双向流水线并行算法,实现计算和通信完全重叠; EPLB(Expert Parallelism Load Balancer) - 专为 V3/R1 设计的专家并行负载均衡器; Profile-data- 分析 V3/R1 中计算与通信重叠的性能数据集。

按时整活!DeepSeek开源周第四天,直接痛快「1日3连发」,且全都围绕一个主题:优化并行策略。

大自然的分形之美,蕴藏着宇宙的设计规则。刚刚,何恺明团队祭出「分形生成模型」,首次实现高分辨率逐像素建模,让计算效率飙升4000倍,开辟AI图像生成新范式。
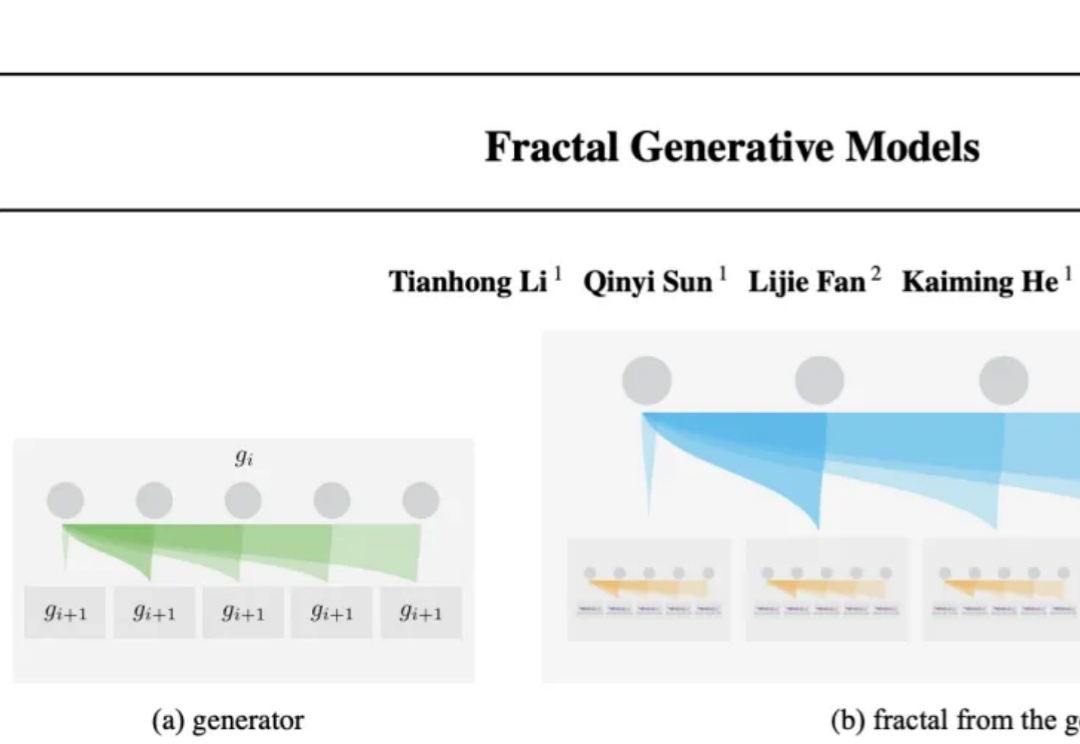
何恺明再次开宗立派!开辟了生成模型的全新范式——

第一个App年入50万,第二个年入500万,第三个月入100万。

当 Scaling Law 在触顶边界徘徊之时,强化学习为构建更强大的大模型开辟出了一条新范式。