
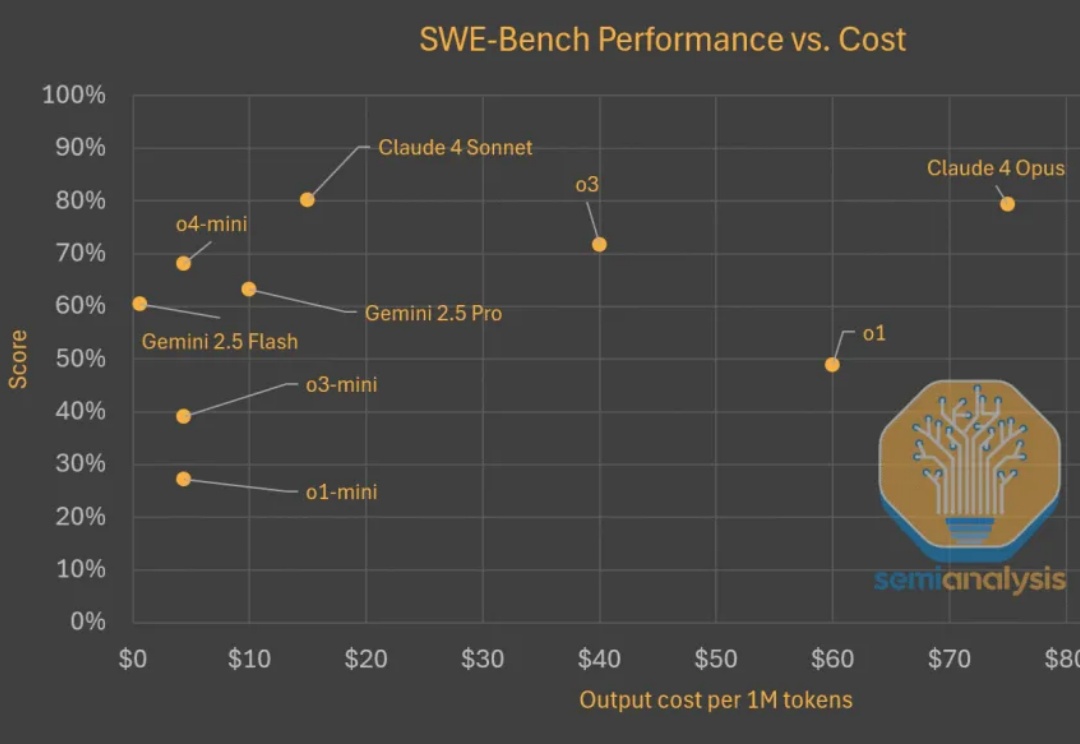
扩展强化学习:环境、奖励黑客、智能体、数据扩展
扩展强化学习:环境、奖励黑客、智能体、数据扩展Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。
来自主题: AI技术研报
7136 点击 2025-06-09 10:25
Test time scaling范式蓬勃发展。推理模型持续快速改进,变得更为高效且价格更为亲民。在评估现实世界软件工程任务(如 SWE-Bench)时,模型以更低的成本取得了更高的分数。以下是显示模型变得更便宜且更优秀的图表。

2025 年 6 月 4 日 ——AI 驱动的金融科技公司 Aibidia 宣布完成 2800 万美元 B 轮融资,资金将用于拓展其在美国的税务科技业务。本轮融资由 Activant Capital 领投,老股东 DN Capital、FPV 和 Icebreaker.vc 跟投。

Decoder是由The Verge 主编 Nilay Patel 主持的深度访谈节目。在这一期中,Decoder邀请到了 Runway 联合创始人兼 CEO Cris Valenzuela,一位既是技术推动者,也是理想主义创作者的创业者

马斯克xAI联合Scale AI训练语音模型,提升自然对话与安全管控。6月6日消息,据媒体获取的文件显示,埃隆·马斯克旗下的人工智能公司xAI正利用一系列问题训练其AI语音模型
能够完成多步信息检索任务,涵盖多轮推理与连续动作执行的智能体来了。通义实验室推出WebWalker(ACL2025)续作自主信息检索智能体WebDancer。
6月5日,微博认证为“ZEALER创始人&CEO”的王自如发文称,“明天我想用15分钟的时间带大家了解我为什么离开 ZEALER 、为什么离开格力,以及我为什么在AI领域选择二次创业,期待明天与大家重新认识。

我对英国创投圈关注不多,但最近注意到一支帝国理工校友创立的AI团队,刚刚获得了英国AI领域迄今规模最大的种子轮融资,觉得有必要研究一下

AI模型用于工业异常检测,再次取得新SOTA!

本周,于旧金山举办的 Snowflake Summit 2025 上,OpenAI CEO Sam Altman 开门见山地指出,对于 2025 年仍在观望的企业领导者,他的建议只有一句:直接开始,别等下一个版本。
从电话录音机到播客,从语音助手到虚拟主播,语音技术在过去几十年里经历了从“工具型服务”向“内容型产品”的演化。大模型的快速崛起让语音技术的发展进入了一个新的跃迁周期,人们对语音产品的期待从听懂”内容“逐渐跃迁到听懂”情绪“。