10年顽疾ChatGPT一眼识破!AlphaGo时刻震撼全球医疗界
10年顽疾ChatGPT一眼识破!AlphaGo时刻震撼全球医疗界十多年,患者求医无果、束手无策,但将所有病史输入ChatGPT,病因竟被一眼识破:基因突变!微软、OpenAI等巨头的医疗AI已悄然登场,准确率超越专业医生!未来的医疗,或将彻底改写!
来自主题: AI资讯
8816 点击 2025-07-06 16:56
 搜索
搜索
十多年,患者求医无果、束手无策,但将所有病史输入ChatGPT,病因竟被一眼识破:基因突变!微软、OpenAI等巨头的医疗AI已悄然登场,准确率超越专业医生!未来的医疗,或将彻底改写!
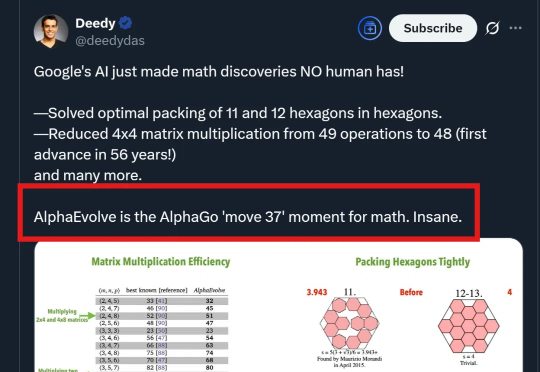
数学能力几乎和AlphaGo的围棋水平一样?!

太疯狂了,AlphaGo的「第37步」时刻,已经来临。谷歌的AlphaEvolve,让我们从此进入AI创造科学的时代,人类科研将彻底颠覆!背后的研究者也首次接受采访,揭秘研究过程中的一些惊人细节。

在全球大模型快速爆发与AIGC应用加速落地的时代,中国的人工智能创业者也在经历从“算法至上”到“产品为王”的重大转变。过去十年,AI行业几度热潮:从2016年AlphaGo引爆的认知革命,到2022年ChatGPT带来的生成式AI浪潮,技术的跃迁正在倒逼产品逻辑重构。而真正决定一家AI公司能否走得远的,从来不是技术demo,而是“有没有真正被用起来”。

他们为ChatGPT/AlphaGo奠定基石
中国版o1刷屏全网。DeepSeek R1成为世界首个能与o1比肩的开源模型,成功秘诀竟是强化学习,不用监督微调。AI大佬们一致认为,这就是AlphaGo时刻。
OpenAI o1 给大模型规模扩展 vs 性能的曲线带来了一次上翘。它在大模型领域重现了当年 AlphaGo 强化学习的成功 —— 给越多算力,就输出越多智能,一直到超越人类水平。

这就是 Google DeepMind 的「DeepMind 部分」——重视它,是保护它的第一步。

自我博弈,很神奇吧?

复刻OpenAI o1推理大模型,开源界传来最新进展: LLaMA版o1项目刚刚发布,来自上海AI Lab团队。