
Java 三十周年重磅发声:James Gosling 怒斥 AI 是“一场骗局”,是科技高管“疯狂压榨”程序员的新工具
Java 三十周年重磅发声:James Gosling 怒斥 AI 是“一场骗局”,是科技高管“疯狂压榨”程序员的新工具“科技行业里骗子和炒作者的数量之多,令人难以置信。”面对当下火热的 AI 浪潮,Java 之父直言不讳地对背后推波助澜的炒作者们发出尖锐批评。
来自主题: AI资讯
5673 点击 2025-05-26 14:48
 搜索
搜索
“科技行业里骗子和炒作者的数量之多,令人难以置信。”面对当下火热的 AI 浪潮,Java 之父直言不讳地对背后推波助澜的炒作者们发出尖锐批评。

AI是否真正在「思考」乃至产生意识,正成为科学和哲学交汇的核心议题。前OpenAI负责人翁荔认为,增加模型的「思考时间」有助突破复杂推理瓶颈;哈佛等机构则指出思维链可能导致「降智」;而生物学家Mallavarapu断言数字计算机永不可能拥有意识。
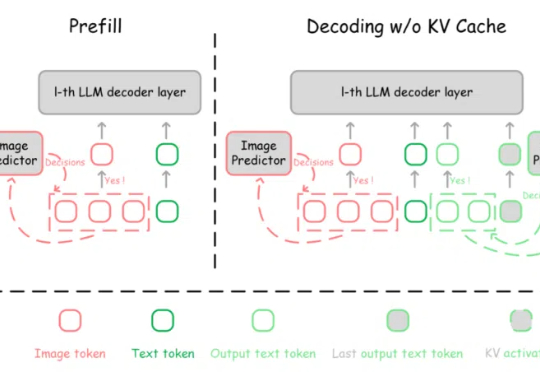
多模态大模型(MLLMs)在视觉理解与推理等领域取得了显著成就。然而,随着解码(decoding)阶段不断生成新的 token,推理过程的计算复杂度和 GPU 显存占用逐渐增加,这导致了多模态大模型推理效率的降低。
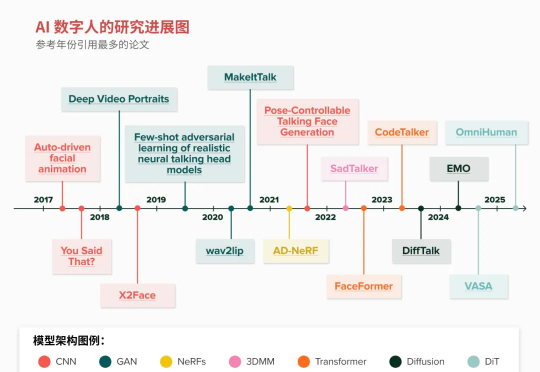
过去几年,AI 已经能生成逼真的图片、视频和声音,悄然通过视觉和听觉的图灵测试。但 2025 年最令人激动的突破之一,毫无疑问将是把这些方案集于一体的 AI 数字人(Al Avatar)。

这个号称世界上第一个AI天使投资人的No Cap,由Jeff wilson、Alexander Nevedovsky 和 Slava Solonitsyn打造,并在最近拿到了YC的投资。No Cap号称是通过一个“No Cap Mafia”社区训练出来的。在这个社区里,No Cap会接受很多公司创始人的指导,目前已经有超过60位创始人(他们都是YC的校友)参与其中。
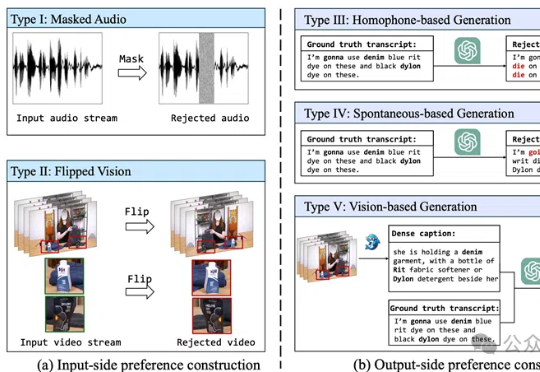
视觉+语音=更强的语音识别!BPO-AVASR通过优化音视频输入和输出偏好,提升语音识别在真实场景中的准确性,解决了传统方法在噪声、口语化和视觉信息利用不足的问题。
几年前,由于元宇宙的热潮,几家专注于数字虚拟人的初创公司应运而生。虽然这股热潮已经消退,但生成式人工智能为虚拟人注入了新的活力,因为创建不同的虚拟身份变得更加容易。
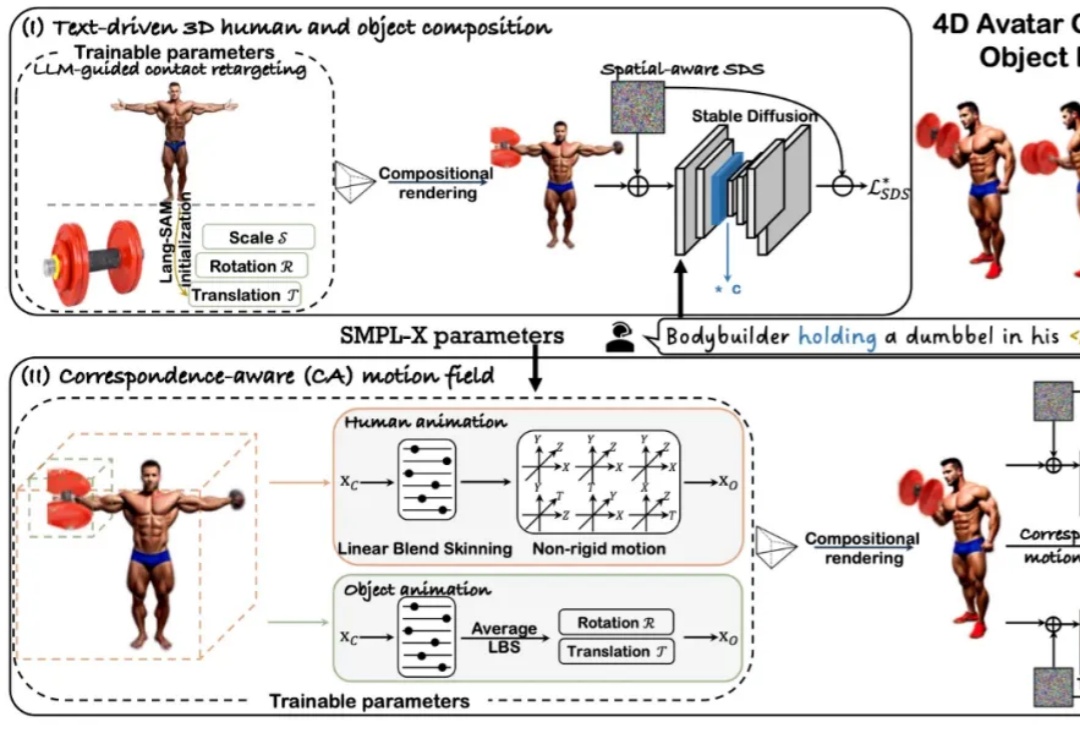
近年来,随着扩散模型和 Transformer 技术的快速发展,4D 人体 - 物体交互(HOI)的生成与驱动效果取得了显著进展。然而,当前主流方法仍依赖 SMPL [1] 这一人体先验模型来生成动作。

Java,这头在企业应用领域深耕 30 年的“猛兽”,如今正虎视眈眈地瞄准 AI 这块 Python 的“固有领地”。尤其是在企业级 AI 应用方面,Python 的优势似乎正在逐渐减弱。一家大型 Java 平台公司的技术负责人甚至预测,2025 年将是 Python 在 AI 领域占据主导地位的最后一年。
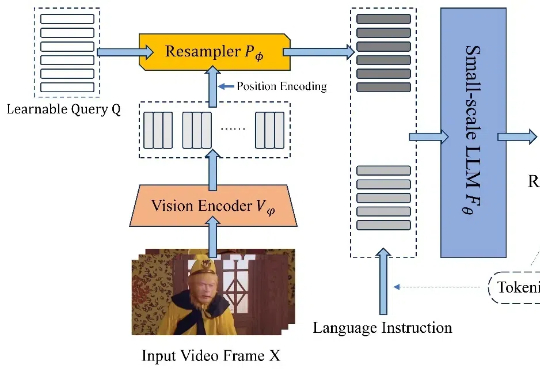
近日,北京航空航天大学的研究团队基于 TinyLLaVA_Factory 的原项目,推出小尺寸简易视频理解框架 TinyLLaVA-Video,其模型,代码以及训练数据全部开源。在计算资源需求显著降低的前提下,训练出的整体参数量不超过 4B 的模型在多个视频理解 benchmark 上优于现有的 7B + 模型。