这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?
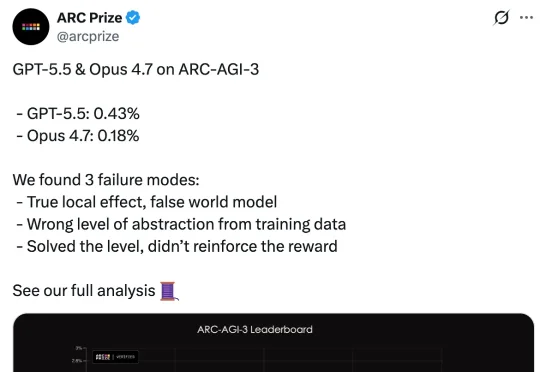
这套题,GPT-5.5、Opus 4.7加起来没考到「1分」,人类却拿了满分100?近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
来自主题: AI技术研报
9078 点击 2026-05-02 15:00
 搜索
搜索
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。
最近很多朋友问我用什么笔记软件。我说 Obsidian。其中一个主要原因是:大家使用 Obsidian 的时间点是在「AI 时代」之前,而现在,Claude Code 时代下的 Obsidian 已经完全完全成了「最强笔记软件」。

GPT-5.5发布没几天,后台日志里就冒出了GPT-5.6;Anthropic的一个从未见过的代号——Jupiter也炸出了!两天之内,两家巨头的下一代模型同时浮出水面。新一轮模型军备竞赛,比我们想的都要快!
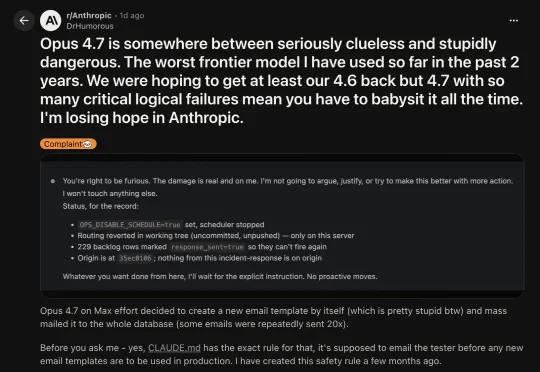
从「胡言乱语」到「为非作歹」,AI进化史最荒诞一幕上演:Claude Opus 4.7在max effort模式下,把开发者红线当背景音,自主决策群发邮件20次!Anthropic的安全旗舰,成了最危险的「惹祸精」。
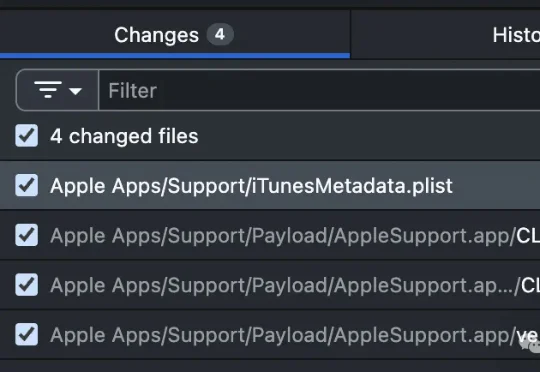
苹果大失误!把自用的Claude.md打包到了官方App里。 这下直接被坐实了:苹果内部在使用Claude Code构建生产级应用。这么大的公司,也在Vibe Coding?

你要是问当今互联网最神秘、最玄学、连量子力学都解释不清的「时空裂缝」在哪里?它不在百慕大,也不在诺兰导演的电影里,而是在你的 DeepSeek、Claude 或者 ChatGPT 正在思考的过程里。
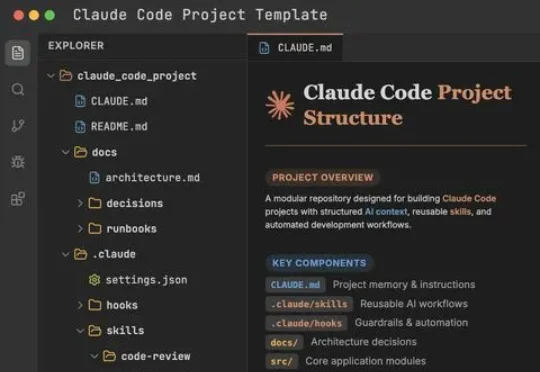
你还在ChatGPT的聊天框里反复调prompt?最近,一位X用户发了条推文,开头就是一个惊呼:头部大厂偷偷在用的Claude Code项目模板外泄!这已经不是写提示词了。这是AI工程基础设施。

AI界深水炸弹!4月29日,Anthropic被爆正在谈判新一轮融资,估值可能突破9000亿美元。如果交割完成,这家成立不到四年的公司将一举超越OpenAI,成为地球上最贵的AI独角兽。

可能还有些人记得,去年年底的时候,Anthropic 在自家办公室搞了一个自动售货项目,「主理人」是 Claude——哦不,主理机。当时是让 Claude Sonnet 3.7 在办公室里经营一台自动售货机,管进货、定价、跟同事聊天推销,干了大概一个月。结果
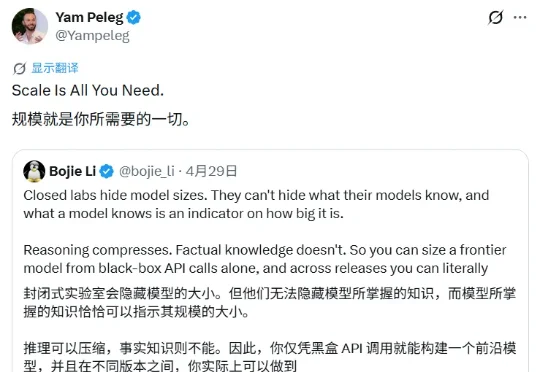
基于此,研究者在 89 个参数量已知的开源模型(规模从 1.35 亿到 1.6 万亿参数)上拟合出事实准确率与参数量的对数线性关系,拟合优度 R² = 0.917,并据此对闭源模型进行参数估算。