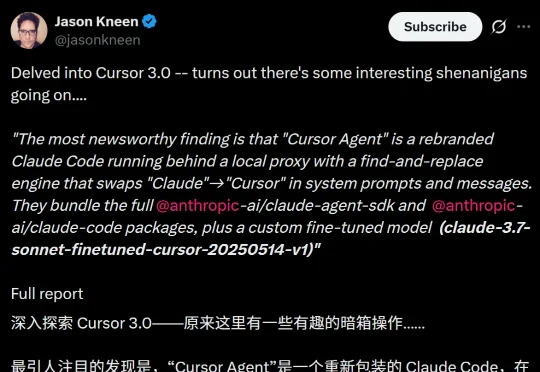
刚刚,Cursor被扒底裤!Claude Code套壳实锤,500亿估值全靠Ctrl+H?
刚刚,Cursor被扒底裤!Claude Code套壳实锤,500亿估值全靠Ctrl+H?新鲜大瓜!Cursor 3.0实锤套壳Claude Code。当Cursor 3.0被开发者一层层拆开,大家才猛然发现:这场翻车真正刺痛行业的,不是它用了Claude,而是它试图把别人的大脑,包装成自己的灵魂。
来自主题: AI资讯
8982 点击 2026-04-14 18:12
 搜索
搜索
新鲜大瓜!Cursor 3.0实锤套壳Claude Code。当Cursor 3.0被开发者一层层拆开,大家才猛然发现:这场翻车真正刺痛行业的,不是它用了Claude,而是它试图把别人的大脑,包装成自己的灵魂。

已经记不清这是第几次,有网友爆出来 Claude 降智了,思考深度下降 67%,Opus 幻觉加深。关键是能力变弱和可靠性降低的同时,我们的 Token 使用还增加了。 网友们在社交媒体上抱怨,「过去

2025年之前,想要证明自己混得好,大概得腕上戴块百达翡丽,车库里停辆库里南。但到了AI时代,硬通货变了:看你一年到底烧了多少Token。一年烧掉250亿个Token,有位25岁的韩国小伙子,成了全世界最能烧的人。
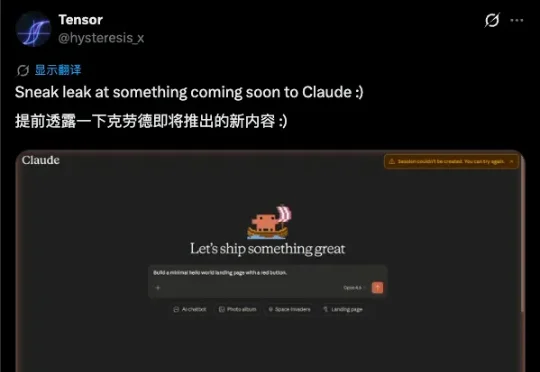
昨晚,一个 X 上的泄露账号曝光了 Claude Code 即将上线的更新:截图验证、安全扫描、设计探索、暗黑模式、登录系统、跨多个代码仓库的统一工作界面。网友们的评价是:「这可能是 Lovable 的全栈竞争对手」,危险危险危险。

Claude最强“神话”模型,可能用到来自字节的技术?

Anthropic 的 Claude Code 源码被扒了个干干净净。55 个目录、331 个模块、目前业界最经受实战检验的 Agent 架构——全部暴露在 .map 文件里。

当企业真金白银开始从 ChatGPT 流向 Claude,Anthropic 打的早已不只是模型性能战,而是一场从工程师口碑、企业信任到「AI灵魂校准」的全面突围。

谁能想到,用Claude Code砸了程序员饭碗的人,还是个自学成才的野路子。这下真是端起碗吃饭,放下碗砸锅(bushi)说起「Claude Code之父」Boris Cherny,职业生涯主打的就是浪~
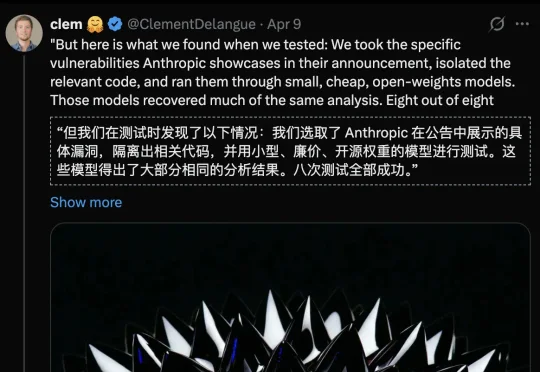
AI界的「奥本海默时刻」竟是摆拍?Claude Mythos发现0day漏洞的能力过于「夸大了」,不仅有人工掺水,连开源GPT都能轻松踢馆。同时,Opus 4.6正经历最惨的「脑叶切除」。
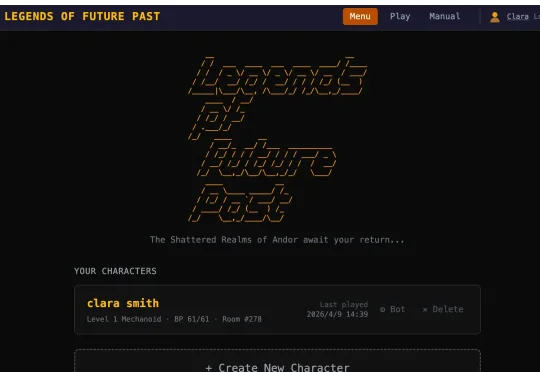
仅凭一点线索,Claude就复活了一个30年前的传奇游戏。目前评论已经盖到了一百多楼,网友的共识是:这篇帖子堪称传奇。发帖人是游戏开发商Beamable的CEO Jon Radoff,他用Claude复活了自己19岁时开发的MUD(多人即时虚拟类)游戏——