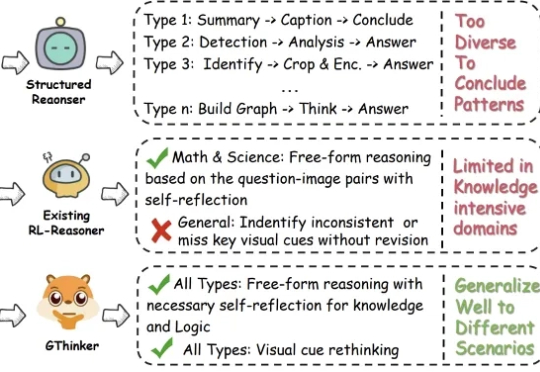
超越O4-mini,多模态大模型终于学会回头「看」:中科院自动化所提出GThinker模型
超越O4-mini,多模态大模型终于学会回头「看」:中科院自动化所提出GThinker模型尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。
来自主题: AI技术研报
8254 点击 2025-07-20 11:50
 搜索
搜索
尽管多模态大模型在数学、科学等结构化任务中取得了长足进步,但在需要灵活解读视觉信息的通用场景下,其性能提升瓶颈依然显著。

难得难得,几大AI巨头不竞争了不抢人了,改联合一起发研究了。
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?
现在几乎所有主流的代码生成工具都在用CoT。但问题来了:这些"思考步骤"真的可靠吗?来自北京航空航天大学的研究者们发现,虽然CoT提升了性能,但关于这些中间推理步骤的质量,学术界竟然没有系统性的研究!

原来,CoT推理竟是假象!Bengio带队最新论文戳穿了CoT神话——我们所看到的推理步骤,并非是真实的。不仅如此,LLM在推理时会悄然纠正错误,却在CoT中只字未提。
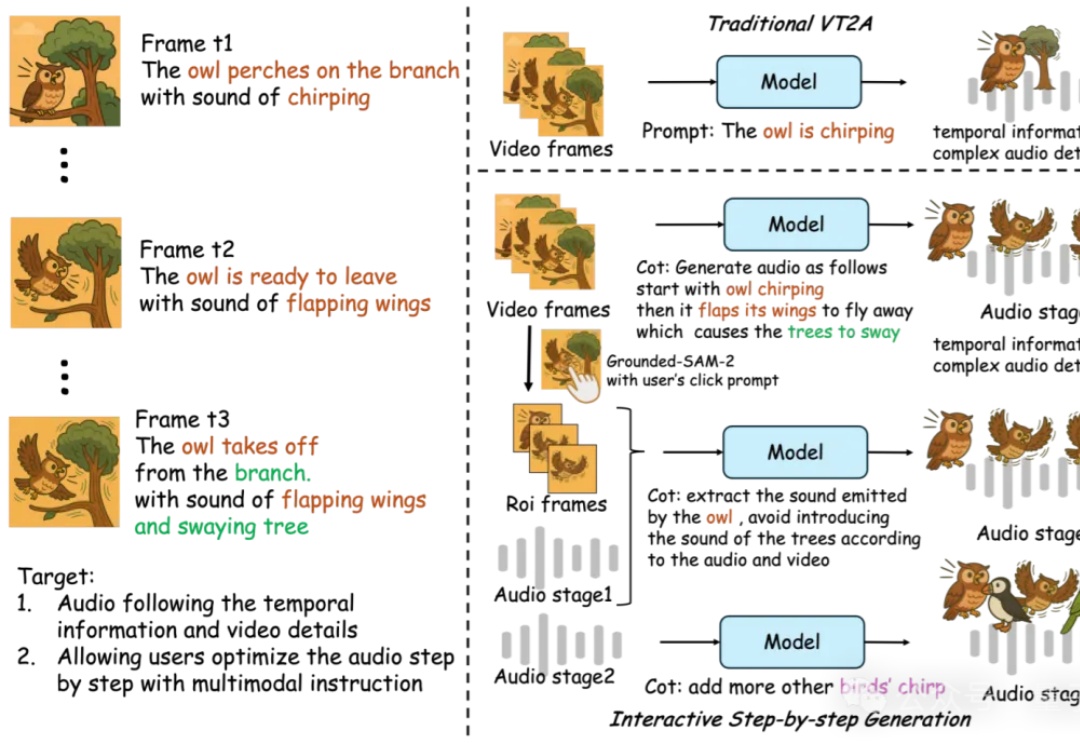
AI音效已经进化成这样了吗??
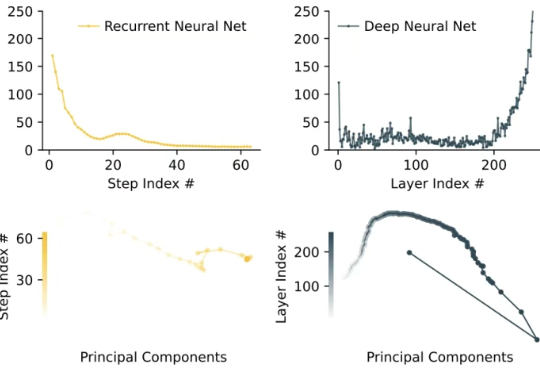
像人一样推理。 大模型的架构,到了需要变革的时候? 在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。

大语言模型(LLMs)在决策场景中常因贪婪性、频率偏差和知行差距表现欠佳。研究者提出强化学习微调(RLFT),通过自我生成的推理链(CoT)优化模型,提升决策能力。实验表明,RLFT可增加模型探索性,缩小知行差距,但探索策略仍有改进空间。
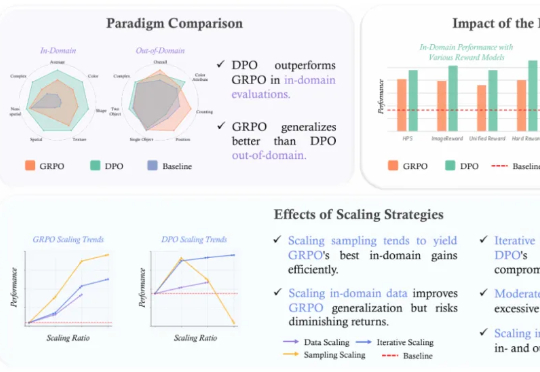
近年来,强化学习 (RL) 在提升大型语言模型 (LLM) 的链式思考 (CoT) 推理能力方面展现出巨大潜力,其中直接偏好优化 (DPO) 和组相对策略优化 (GRPO) 是两大主流算法。

在生成式 AI 迅猛演进的时代浪潮中,Cognition AI 正成为硅谷最受瞩目的技术公司之一。而其背后,是一位横跨数学竞赛、工程实践与系统构建的 90 后创始人——Scott Wu。