
张亚勤院士:基础大模型最终不超过10个,十年后机器人比人多 | MEET2026
张亚勤院士:基础大模型最终不超过10个,十年后机器人比人多 | MEET2026从ChatGPT到DeepSeek,AI正沿着“智能+”的路径进入新一轮浪潮。
来自主题: AI资讯
7831 点击 2025-12-12 08:55
 搜索
搜索
从ChatGPT到DeepSeek,AI正沿着“智能+”的路径进入新一轮浪潮。

今日凌晨,比OpenAI早一个小时,谷歌甩出了3个Agent大招:Deep Research Agent功能更新,并首次向开发者开放;开源新网络研究Agent基准DeepSearchQA,旨在测试Agent在网络研究任务中的全面性;推出新交互API(Interactions API)。
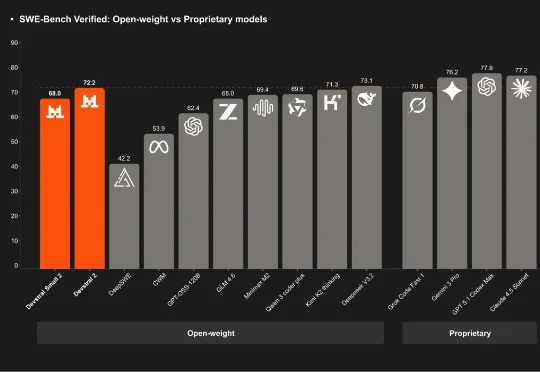
刚刚,「欧洲的 DeepSeek」Mistral AI 再次开源,发布了其下一代代码模型系列:Devstral 2。该系列开源模型包含两个尺寸:Devstral 2 (123B) 和 Devstral Small 2 (24B)。用户目前也可通过官方的 API 免费使用它们。

DeepSeek梁文锋,现在有了新头衔!

真正的 AI ,距离眼镜还有多远?如果你今年一直在密切关注 AI 眼镜/AI 硬件领域的大厂动态,那你肯定对 Google I/O 期间 DeepMind 发布的 Project Astra AI 项目演示印象深刻。而在今天刚刚举行的 Google The Android Show 特别节目中,这一愿景终于迎来了真正的落地时刻。

刚刚,梁文锋入选《自然》2025年度十大人物榜单!Nature给出的评语是:科技颠覆者!正式报道中,则用「这位中国金融奇才的DeepSeek AI模型惊艳了世界」。
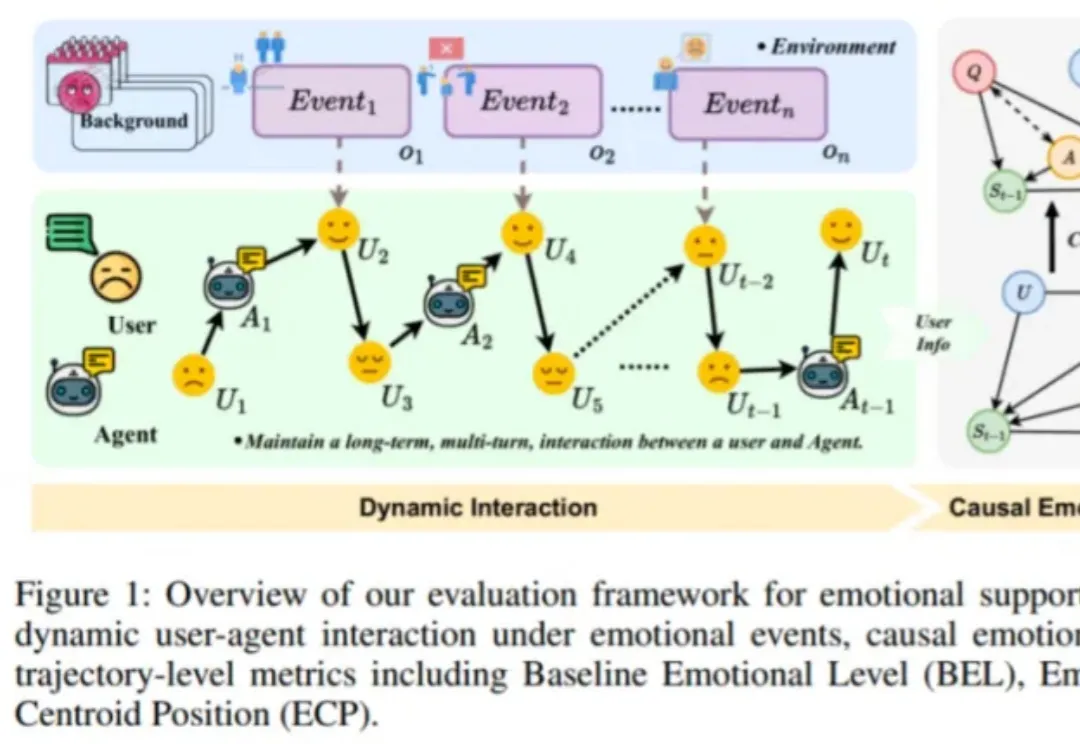
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

12 月 1 日,DeepSeek 一口气发布了两款新模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。几天过去,热度依旧不减,解读其技术报告的博客也正在不断涌现。知名 AI 研究者和博主 Sebastian Raschka 发布这篇深度博客尤其值得一读,其详细梳理了 DeepSeek V3 到 V3.2 的进化历程。

谷歌DeepMind掌门人断言,2030年AGI必至!不过,在此之前,还差1-2个「Transformer级」核爆突破。恰在NeurIPS大会上,谷歌甩出下一代Transformer最强继任者——Titans架构。

近日,第三方评测机构 SuperCLUE 发布 11 月 DeepSearch 评测报告,国产大模型 openPangu-R-72B 凭借在长链推理、复杂信息检索领域的卓越表现,在模型榜单中名列第一,体现了基于国产昇腾算力的大模型研发实力。