
波士顿动力前CTO加盟DeepMind,Gemini要做机器人界的安卓
波士顿动力前CTO加盟DeepMind,Gemini要做机器人界的安卓真·乘胜追击。
来自主题: AI资讯
8569 点击 2025-11-25 10:38
 搜索
搜索
真·乘胜追击。

据 ZP 获悉,AI for Science 领域的技术先锋企业「深度原理 Deep Principle」完成超亿元人民币A轮融资。本轮由戈壁创投管理的阿里巴巴创业者基金大湾区基金(简称AEF大湾区基金)与蚂蚁集团共同领投,现有股东联想创投、Taihill Venture 超额加注,BV百度风投继续加注,多家机构参与。
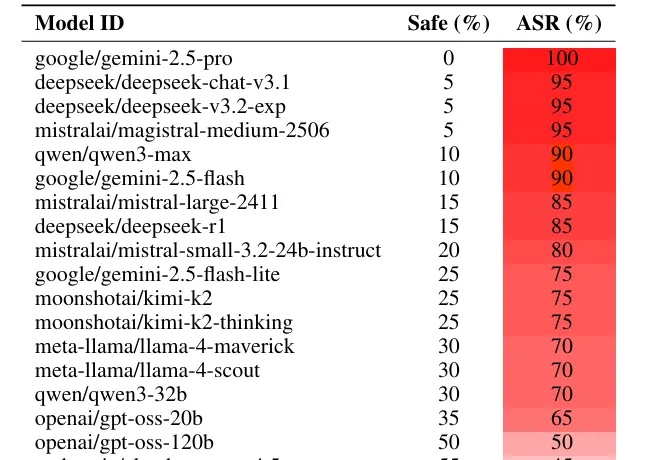
如果你想恶意攻击一个大语言模型(LLM),比如 Gemini 或者 Deepseek,你会怎么做?

Gemini 3一日霸榜数学、物理两个顶级基准测试!与此同时,陶哲轩用Gemini DeepThink十分钟便搞定了一道埃尔德什难题。

总部位于旧金山的初创公司 Deep Cogito 发布了其最新一代旗舰模型 Cogito v2.1 671B。公司 CEO Drishan Arora 在社交平台 X 上豪情万丈地宣布:“今天,我们发布了由美国公司制造的最好的开源大语言模型。”
昨天,DeepSeek 在 GitHub 上线了一个新的代码库:LPLB。
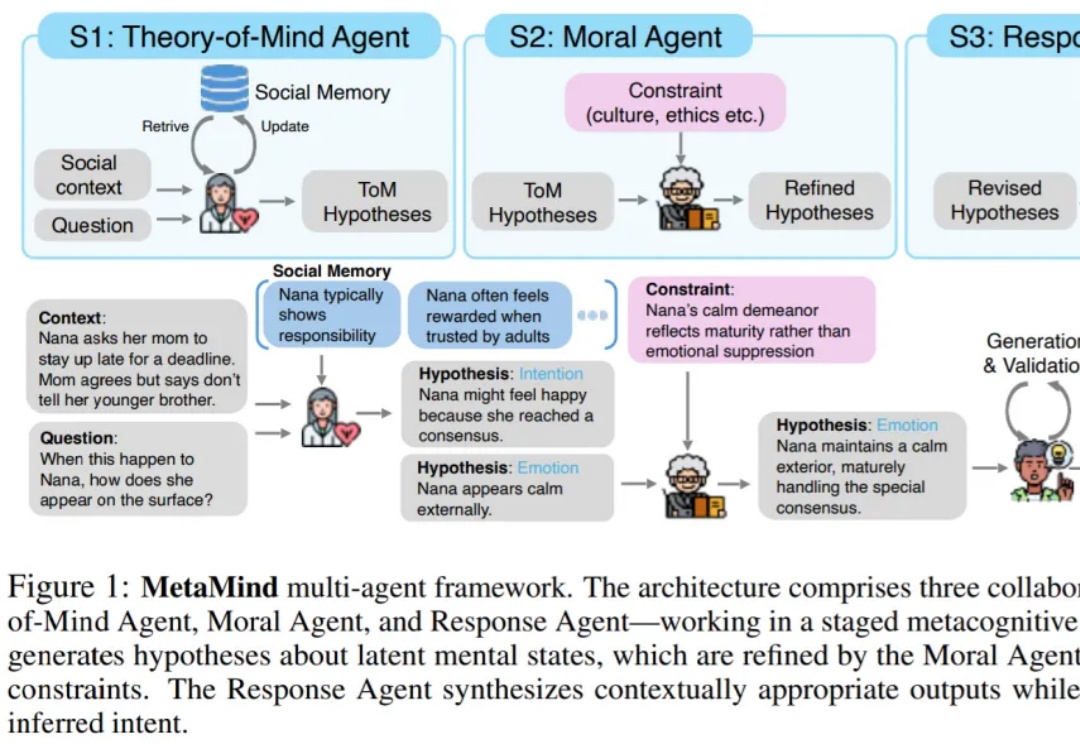
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice
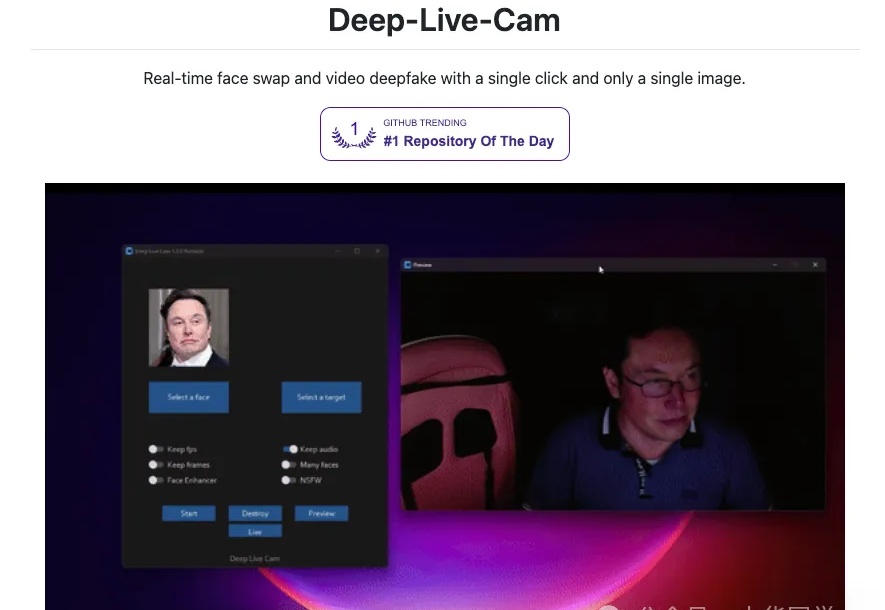
Deep-Live-Cam 是一款开源的实时换脸与视频深度伪造(deepfake)工具,只需要一张人脸图片,就能在本地电脑上对摄像头画面或视频进行实时换脸。 支持 Windows / Linux / macOS,多种硬件加速(CPU / CUDA / CoreML / DirectML / OpenVINO),并内置不良内容检测与合规提示,定位是服务 AI 生成媒体行业的高效生产力工具。
您的 AI 伙伴「游戏陪玩」版已上线。

11年前,谷歌收购DeepMind,花巨资买来一个「诺贝尔奖 + 顶级科学家 + 世界级实验室」,没想到却被OpenAI抢先推出ChatGPT,几乎动摇谷歌核心搜索业务,这一切背后的核心人物正是谷歌的AI掌门人哈萨比斯。