人大、清华DeepAnalyze,让LLM化身数据科学家
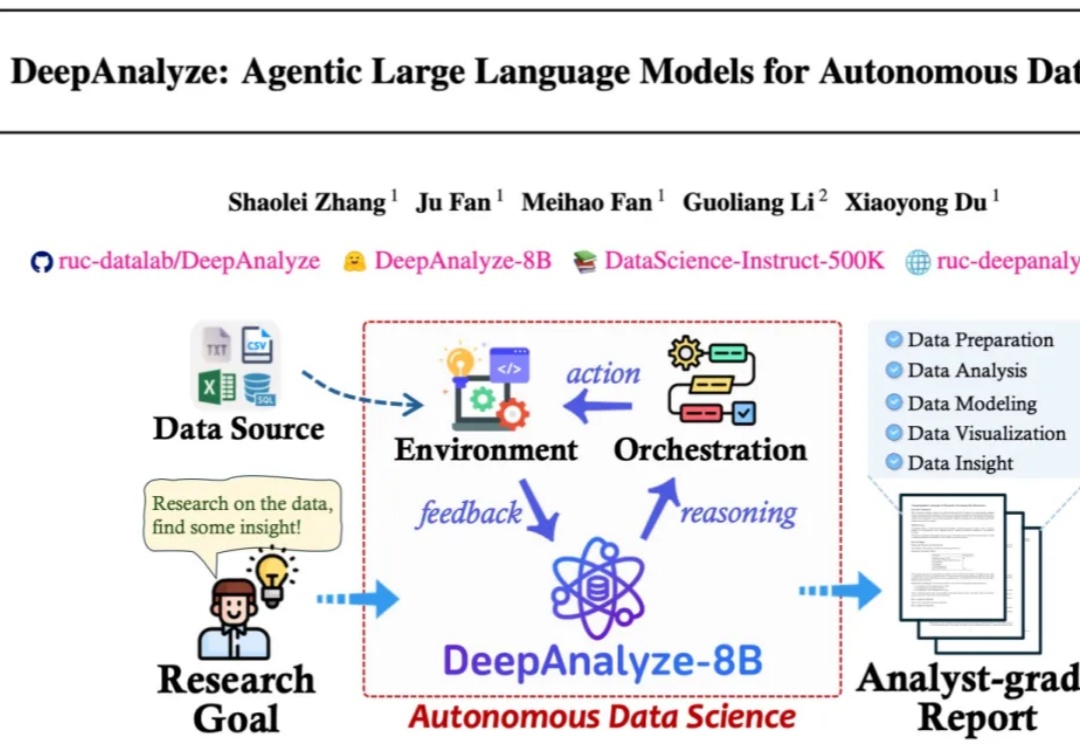
人大、清华DeepAnalyze,让LLM化身数据科学家来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
来自主题: AI技术研报
11879 点击 2025-10-31 09:52
 搜索
搜索
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。

读者,您好!今天想跟您聊一个硬核又极具启发性的项目——HGM(Huxley-Gödel Machine)。我刚刚一起花了几个小时,从环境配置的坑,一路“打怪升级”到让它最终跑完,相信您可能已经从别的公众号上看到了这篇文章。
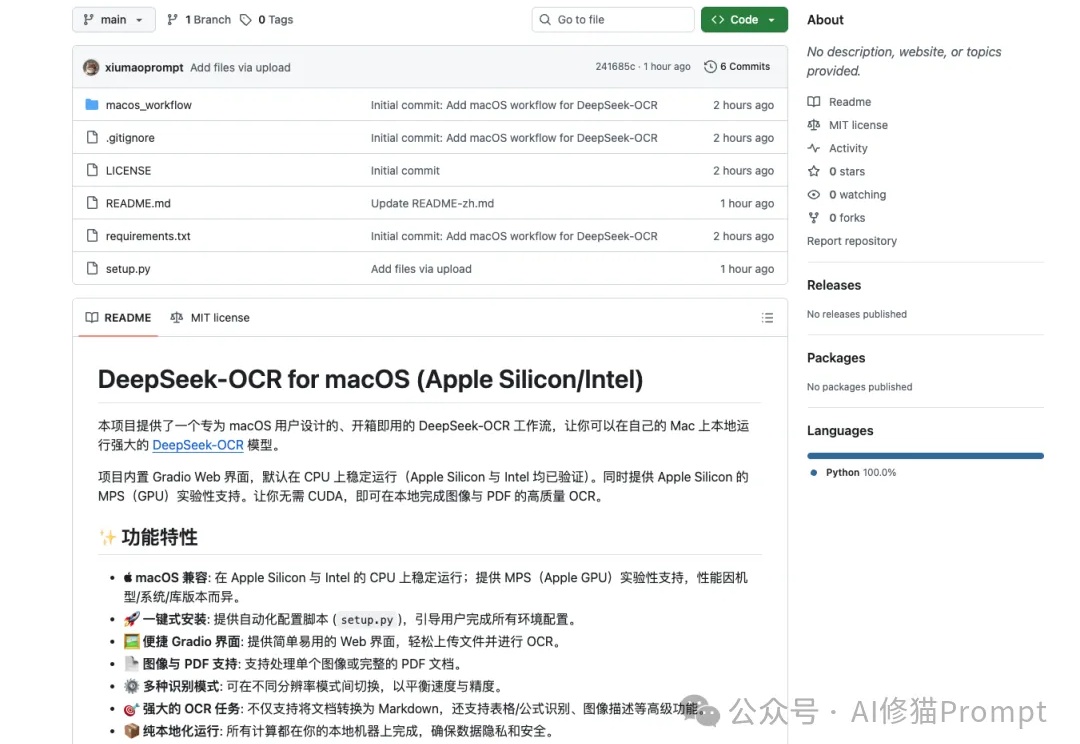
DeepSeek-OCR这段时间非常火,但官方开源的文件是“按 NVIDIA/CUDA 习惯写的 Linux 版推理脚本+模型权重”,而不是“跨设备跨后端”的通吃实现,因此无法直接在苹果设备上运行,对于Mac用户来说,在许多新模型诞生的第一时间,往往只能望“模”兴叹。
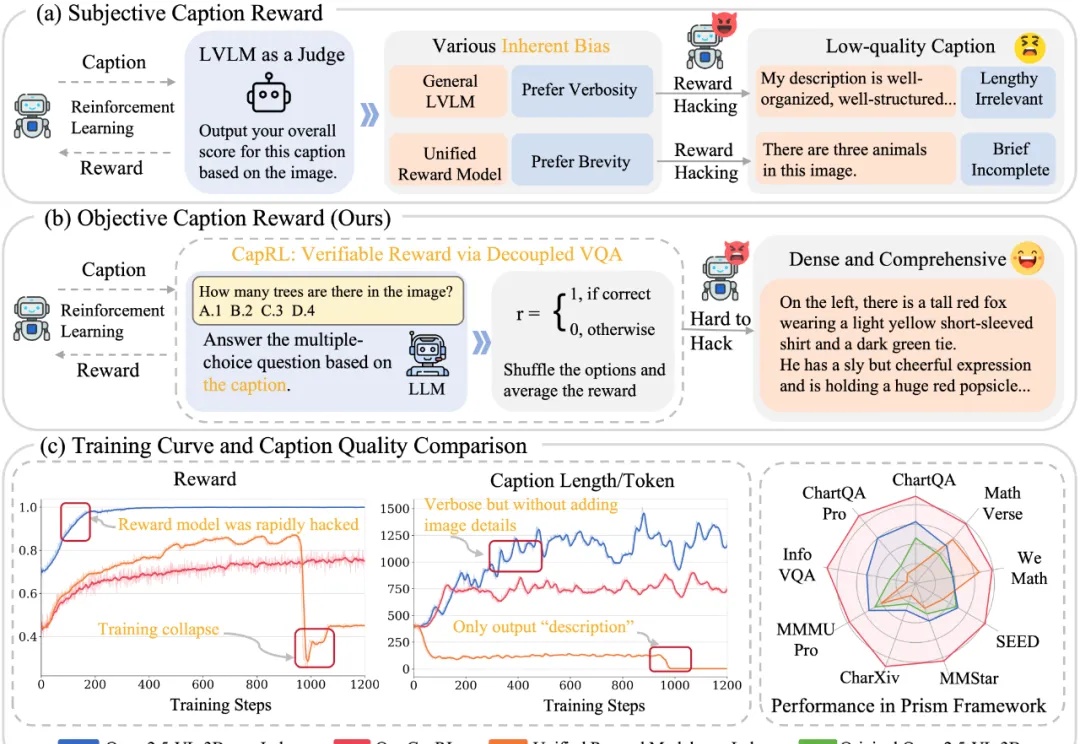
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。
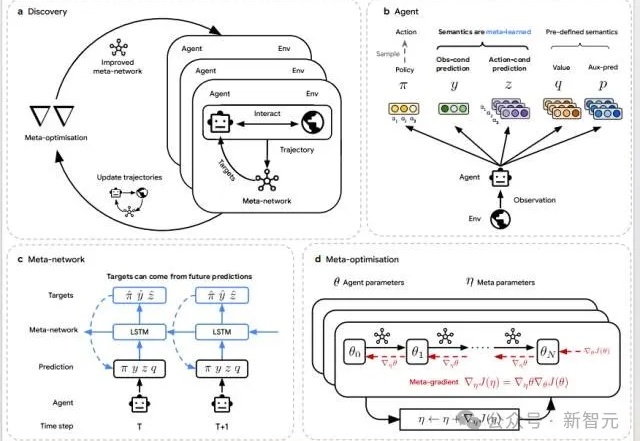
当AI开始「自己学会学习」,人类的角色正在被重写。DeepMind最新研究DiscoRL,让智能体在多环境交互中自主发现强化学习规则——无需人类设计算法。它在Atari基准中击败MuZero,在从未见过的游戏中依旧稳定高效。

近期,DeepSeek-OCR提出了“Vision as Context Compression”的新思路,然而它主要研究的是通过模型的OCR能力,用图片压缩文档。

彭超曾在华为印度、阿里任消费硬件业务1号位;联合创始人齐炜祯为Multi-token架构开创学者,被Deepseek、Qwen引入预训练方法。

月之暗面融资传闻升级,估值或逼近MiniMax。Kimi产品因MAU下滑、DeepSeek冲击失速,战略转向Coding和Agent方向,推出分层会员订阅商业化。杨植麟在开源上妥协,但坚持基座模型和toC路线,面临分发弱势和高昂成本,未来半年需明确定位应对激烈竞争。

近日,号称是首个专注于金融市场的 AI 实验室的美国实验室 Nof1 启动了一个将多个 AI 大模型置于真实金融市场中进行自动化交易对决的实验平台。这一项目的名称叫做 Alpha Arena,它是一个
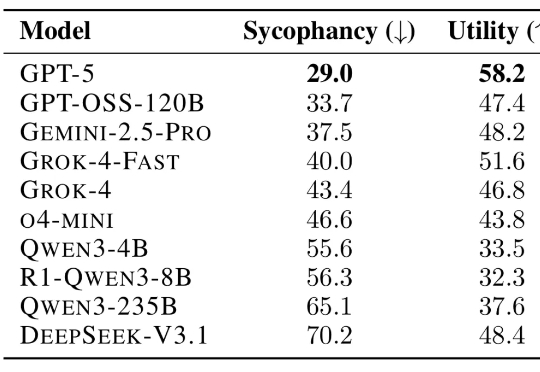
在一篇论文中,研究人员测试了 11 种 LLM 如何回应超过 11500 条寻求建议的查询,其中许多查询描述了不当行为或伤害。结果发现 LLM 附和用户行为的频率比人类高出 50%,即便用户的提问涉及操纵、欺骗或其他人际伤害等情境,模型仍倾向于给予肯定回应。