
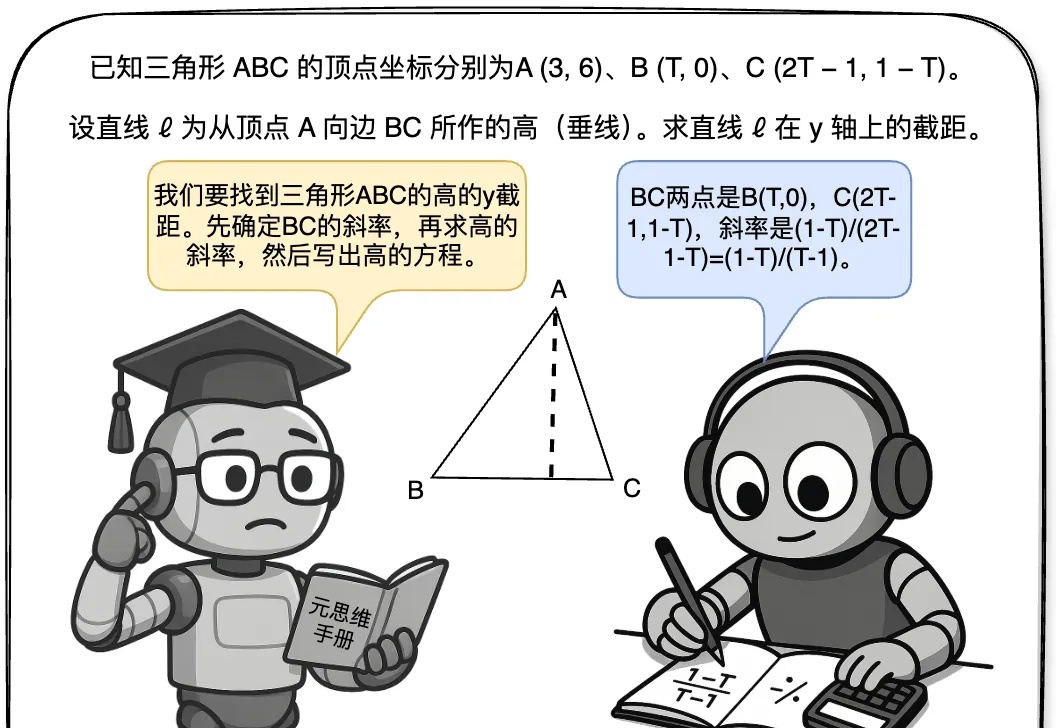
数学题干带猫AI就不会了!错误率翻300%,DeepSeek、o1都不能幸免
数学题干带猫AI就不会了!错误率翻300%,DeepSeek、o1都不能幸免大模型数学能力骤降,“罪魁祸首”是猫猫?只需在问题后加一句:有趣的事实是,猫一生绝大多数时间都在睡觉。
来自主题: AI资讯
7819 点击 2025-07-05 20:35
 搜索
搜索
大模型数学能力骤降,“罪魁祸首”是猫猫?只需在问题后加一句:有趣的事实是,猫一生绝大多数时间都在睡觉。

Jack Clark 是最关注和熟悉中国在芯片、计算和模型上进展的 AI Lab 领导人之一。他毫不吝啬对中国 AI 进展的认可,将 DeepSeek R1 视作“推理模型大范围扩散”的起点,近期又把 HyperHetero 使用的异构集群叫做通过“超级智能进行持续自我训练”的垫脚石。

2025年,AI界风云激荡,DeepSeek-R1横空出世、英伟达市值称霸全球、谷歌AlphaEvolve打破数学神话,中国Qwen3登顶开源王座……智能爆炸的奇点已悄然降临!新智元十周年之际,2025 AI Era & ASI创新大奖报名正式启动,致敬重塑世界的AI先锋!

没等来 DeepSeek 官方的 R2,却迎来了一个速度更快、性能不弱于 R1 的「野生」变体!这两天,一个名为「DeepSeek R1T2」的模型火了!这个模型的速度比 R1-0528 快 200%,比 R1 快 20%。除了速度上的显著优势,它在 GPQA Diamond(专家级推理能力问答基准)和 AIME 24(数学推理基准)上的表现均优于 R1,但未达到 R1-0528 的水平。
DeepSeek-R2,终于要来了?大模型竞技场秘密上线了一个叫steve的神秘模型,在对话中透露自己来自DeepSeek。不过,网友们并不满足于知道steve的厂商,开始讨论起了steve的具体身份。
近日,一则消息在网络上引发热议。有媒体称,“DeepSeek就AI模型违规关联王一博与‘李爱庆腐败案’,作出道歉。”
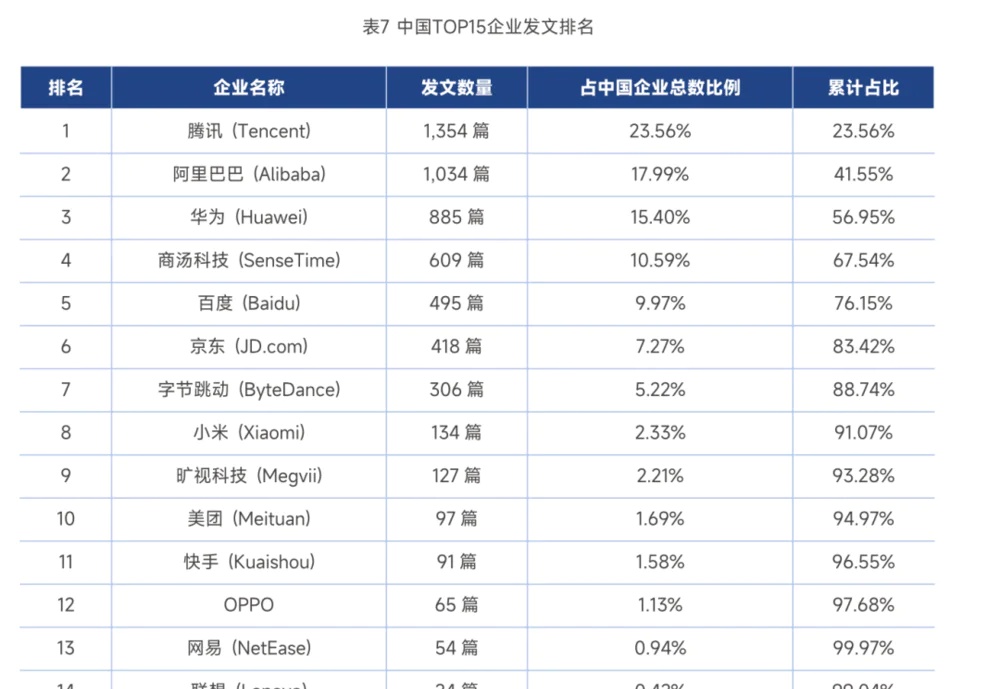
7月3日,2025全球数字经济大会上,一份重磅榜单面向全球首次揭晓。

DeepMind新研究揭示了当与推理无关的想法,被直接注入到模型的推理过程中时,它们却难以恢复,而且越大的模型越难恢复。
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。

AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。