
DeepSeek-R2为什么还没发?
DeepSeek-R2为什么还没发?全网翘首以盼的DeepSeek-R2,再次被曝推迟!据The Information报道,由于DeepSeek CEO梁文锋始终对R2的表现不满意,因此R2迟迟未能发布。此外,他们还援引两位国内知情人士的消息称,R2研发进程缓慢可能是由于缺少英伟达H20芯片。
来自主题: AI资讯
10603 点击 2025-06-27 16:46
 搜索
搜索
全网翘首以盼的DeepSeek-R2,再次被曝推迟!据The Information报道,由于DeepSeek CEO梁文锋始终对R2的表现不满意,因此R2迟迟未能发布。此外,他们还援引两位国内知情人士的消息称,R2研发进程缓慢可能是由于缺少英伟达H20芯片。
这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。
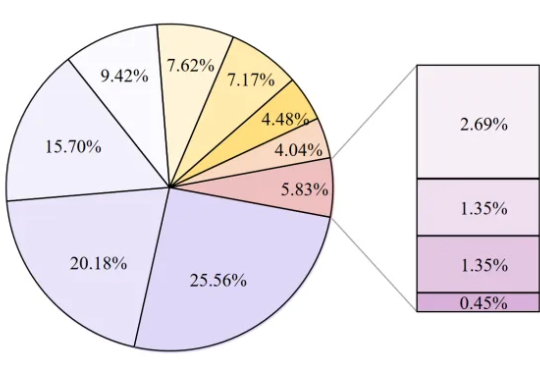
LLMs能当科研助手了? 北大出考题,结果显示:现有模型都不能胜任。
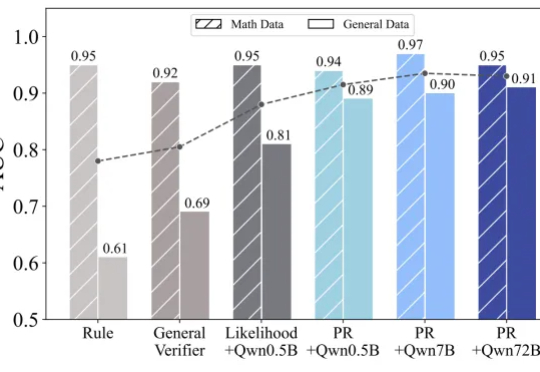
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward

前有AlphaFold破解蛋白质之谜,今有AlphaGenome揭示DNA天书。谷歌DeepMind最新103页力作,用AI成功预测基因突变,一次即可读取100万个DNA碱基,精度无「模」能敌。
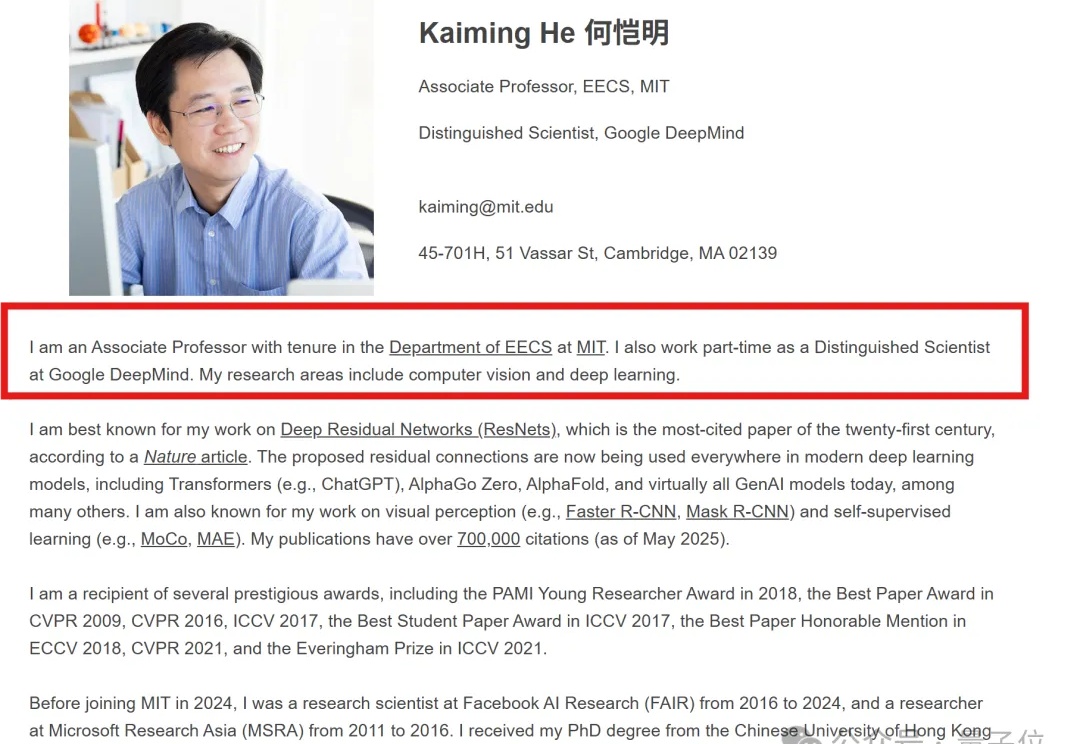
AI大牛何恺明最新动向来了!

AI大神何恺明正式入职谷歌DeepMind,担任杰出科学家,同时保留MIT终身副教授身份。从Meta到MIT,再到如今的谷歌,这位「学界+业界」双修的大牛,将为DeepMind的AGI注入一针强心剂。

6月22日,在 AGI Playground 2025 大会上,主办方靖亚资本、联合主办方 Founder Park、崔牛会一同正式发布了 2025 AI Cloud 100 China 榜单。

这条人机交互的进化之路,出门问问从未真正放弃。今年,大模型基础能力再次实现飞跃,像 ChatGPT、DeepSeek、豆包这样的 AI 工具,正在成为越来越多职场人工作中的常用助手。
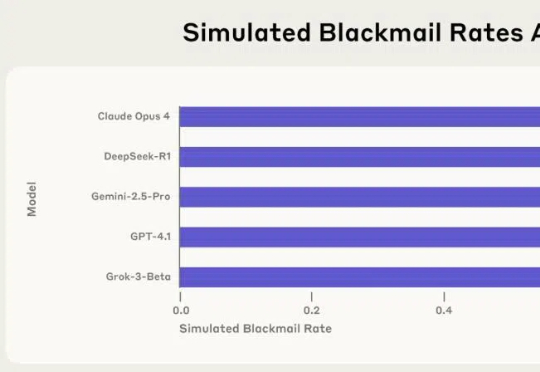
AI不一定是“邪恶”的,但它也远非“中立无害”。 过去几年里,我们习惯了通过 ChatGPT 等 AI 产品提问、聊天、生成代码。