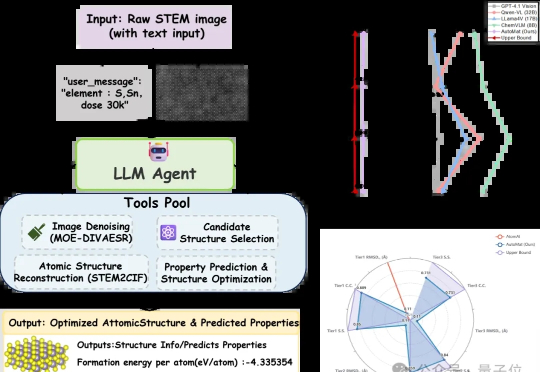
清华给电子显微镜加上Agent,DeepSeek V3全程调度,数天流程缩短至几分钟
清华给电子显微镜加上Agent,DeepSeek V3全程调度,数天流程缩短至几分钟AI Agent又解锁了一个领域!清华大学牵头,与西北工业大学以及上海AI lab等机构推出了电镜领域的AI agent——AutoMat。
来自主题: AI技术研报
8752 点击 2025-06-06 15:14
 搜索
搜索
AI Agent又解锁了一个领域!清华大学牵头,与西北工业大学以及上海AI lab等机构推出了电镜领域的AI agent——AutoMat。
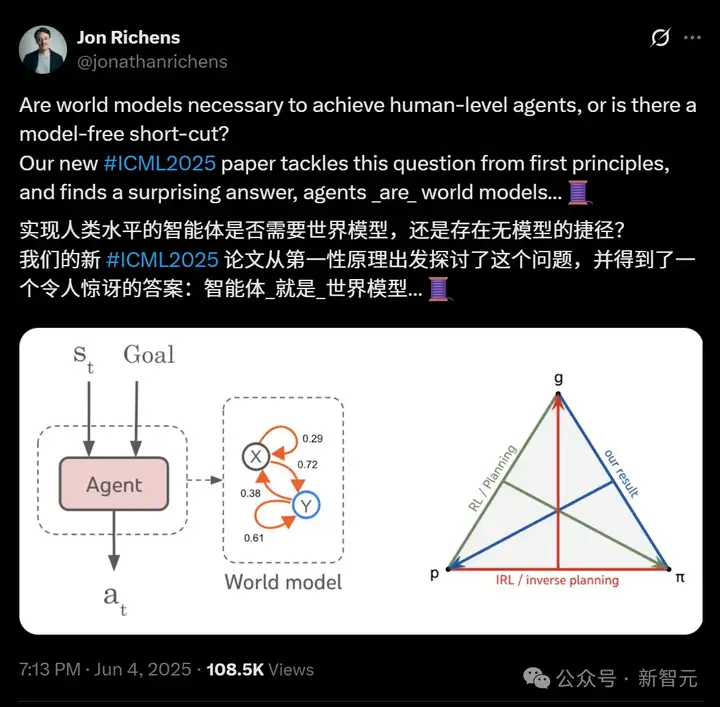
就在刚刚,DeepMind科学家Jon Richens表示,自己的一篇ICML 2025论文发现,智能体就是世界模型!总之,如果要实现AGI,是绝对不存在无模型的捷径的。而这个说法,恰巧跟Ilya 23年的预言不谋而合了。

从国际象棋神童到诺贝尔奖得主,Hassabis正带领谷歌DeepMind追逐AGI梦想。AI正在颠覆职场,但Hassabis乐观地认为,AI不仅能提高生产力,创造新工作,还可能让人类不再自私!

如果要问近期最火热的AI硬件品类是什么,AI眼镜一定榜上有名。
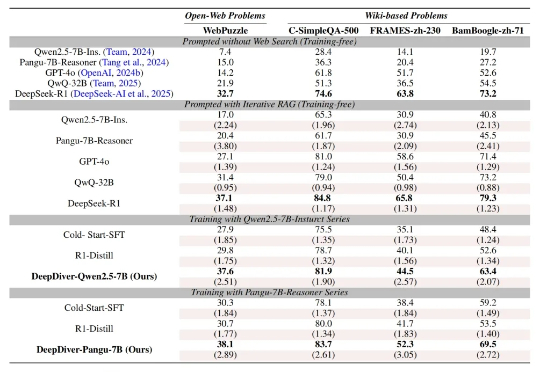
大型语言模型 (LLM) 的发展日新月异,但实时「内化」与时俱进的知识仍然是一项挑战。如何让模型在面对复杂的知识密集型问题时,能够自主决策获取外部知识的策略?

数学家出手反击AI!对AlphaEvolve在“集合和差问题”上的成果进一步改进。
上图本次发布直播的页面:ChatGPT for business。所以这是一个商业导向的更新,跟普通用户没啥大关系。本次共有两个更新,下面一个一个介绍它们。(别抱有太大希望)更新 1:Deep Research Connector

如今的新浪,已经被DeepSeek全面重塑了!新浪新闻推出AI辅助工具「智慧小浪」帮我们看新闻,更高效、更深度。同时,微博的「评论罗伯特」的人味也是噌噌up,爆梗频出、妙语连珠。
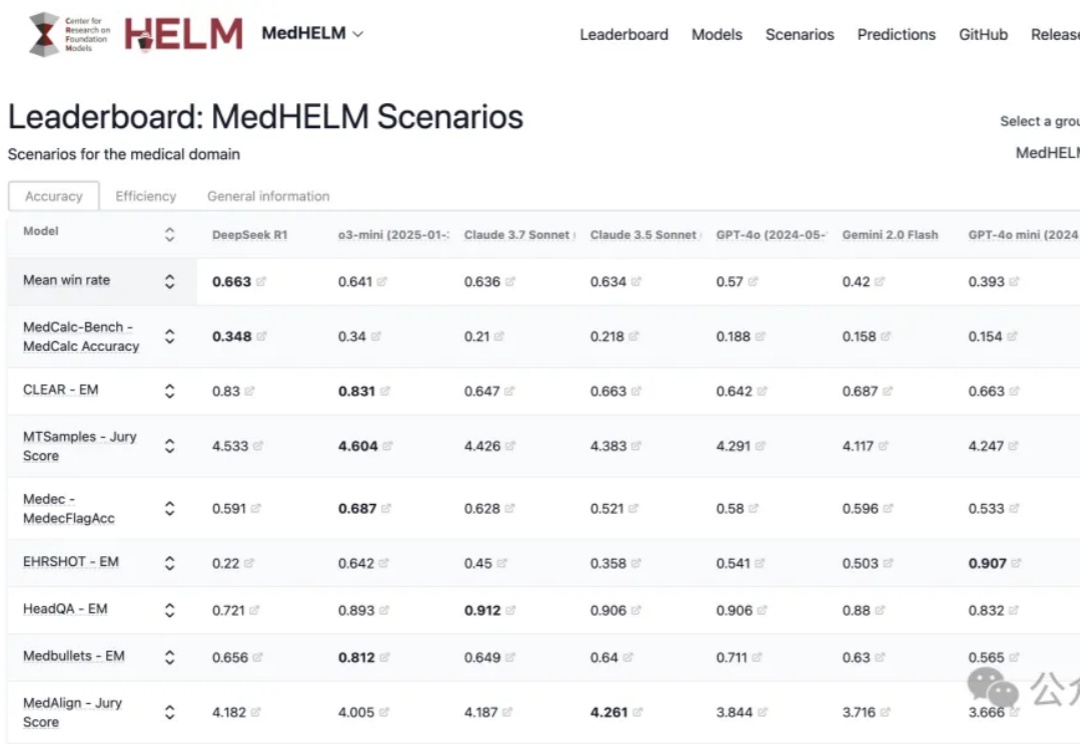
斯坦福最新大模型医疗任务全面评测,DeepSeek R1以66%胜率拿下第一!
最近AI圈子里有两个特别有意思的项目,一个是谷歌DeepMind的AlphaEvolve,另一个是UBC大学的Darwin Gödel Machine(简称DGM)。