
忘不了的 Kimi C轮融资
忘不了的 Kimi C轮融资最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。
来自主题: AI资讯
8925 点击 2026-05-26 10:26
 搜索
搜索
最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

前两天,AI 圈子里出了个瓜,关于 DeepSeek TUI 创始人的,各个社媒群里几乎都刷屏了。但我发现一个问题 ——大家都只盯着一张微信群聊的截图在讨论,几乎没人把整件事的来龙去脉理一遍。
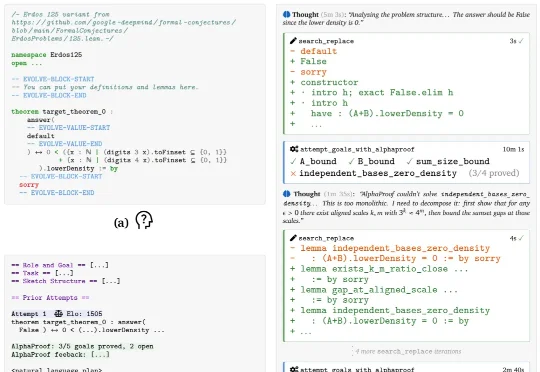
前脚OpenAI刚把Erdős 80年猜想推翻,数学家们的惊呼声还没落地。紧接着,Google DeepMind发布了一个全新AI数学智能体——AlphaProof Nexus。它一出手,就干掉了9道悬而未决几十年的Erdős开放问题。其中最古老的那个,悬了整整56年!
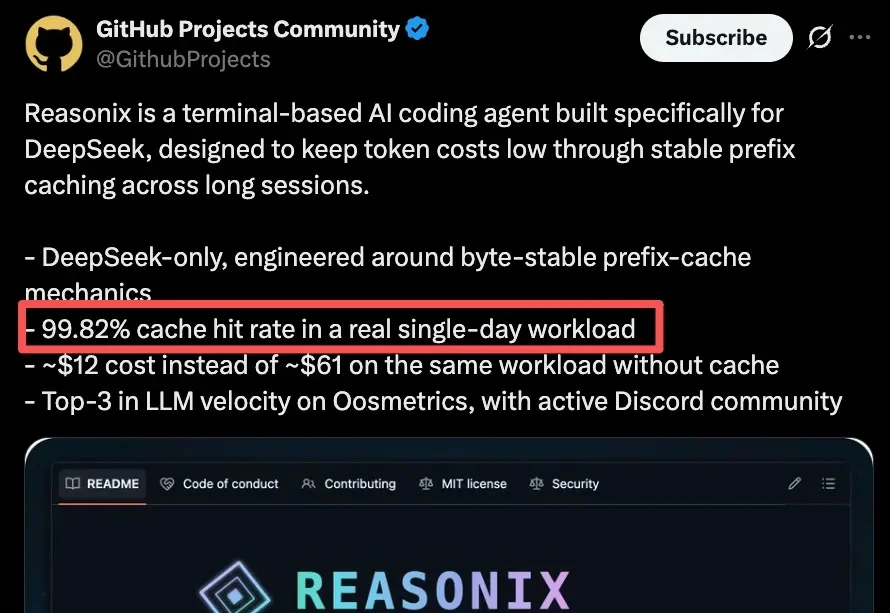
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

前谷歌DeepMind研究员离职并发表长文指出AI行业当前最被低估的瓶颈。他认为,现有的基准测试和安全评估都隐含假设下一代模型只是当前模型的增强版,但如果模型跨入全新能力区间,整个评估基础设施将悄然崩溃。

DeepSeek正用开源、降价和底层架构创新,重画AI硬件生态的成本曲线,把目标指向十万亿美元产业与AGI的星辰大海。

从Atari到AlphaGo,从AlphaStar到SIMA,DeepMind用游戏做AI研究已走过十余年,每换一个战场,研究问题就升一个量级。这一次的战场是EVE Online:一个跑了23年、从未重置的活宇宙。
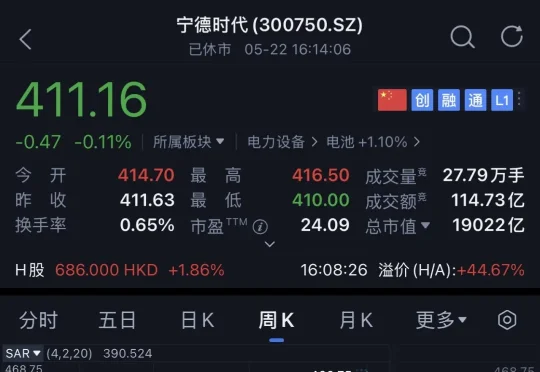
据The Information昨晚报道,全球动力电池市场龙头宁德时代拟入局DeepSeek首轮融资。这是宁德时代在AI领域被曝出的最新布局。就在刚刚过去的一个半月内,宁德时代官宣斥资105亿元加码AI算电协同赛道,电力、算力、储能、AI一体化全产业链布局全面落地。

“这是我见过最激烈的竞争之一,甚至可能是资本主义历史上最激烈的竞争。”这是谷歌 DeepMind CEO Demis Hassabis 在访谈中对这场 AI 竞赛的评论。著名科技作家 Sebastian Mallaby 甚至直接将 AI 类比为现代的曼哈顿计划。