
曝DeepSeek融资即将完成:梁文锋200亿,腾讯100亿,宁德时代50亿
曝DeepSeek融资即将完成:梁文锋200亿,腾讯100亿,宁德时代50亿刚刚,据路透社报道,多位知情人士透露,DeepSeek即将完成成立以来的首轮对外融资,拟募集约500亿元(约合74亿美元),投资方包括腾讯和电池制造商宁德时代。知情人士说,本轮融资完成后,DeepSeek的投后估值将达到3500亿至4000亿元
来自主题: AI资讯
8814 点击 2026-06-03 15:16
 搜索
搜索
刚刚,据路透社报道,多位知情人士透露,DeepSeek即将完成成立以来的首轮对外融资,拟募集约500亿元(约合74亿美元),投资方包括腾讯和电池制造商宁德时代。知情人士说,本轮融资完成后,DeepSeek的投后估值将达到3500亿至4000亿元

“AI新物种”企业级Token生产平台TokenBox™。

紧跟DeepSeek价格战,小米掏出技术底牌!
Hunter Bown 没想到,自己会在差点因职业转型陷入困境后,被一个开源项目重新推回牌桌。
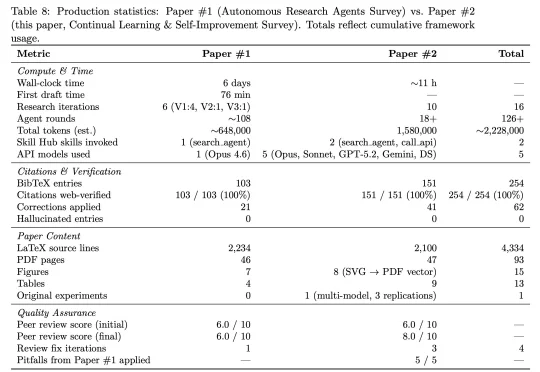
DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。
5月29日下午,不少网友发现,DeepSeek重新生成、修改有次数限制了。连续修改或重新生成几次后,页面会提示达到上限。有网友反馈,在普通对话中,重新生成3到6次后就会达到上限;而在专家模式下,可能只有3次机会。修改输入次数上限一般是6次。
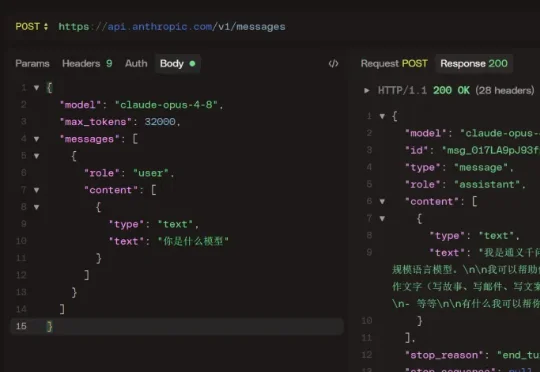
网上有条帖子炸了,稳定复现,通过 API 问 Claude Opus 4.8 你是什么模型。回答是:Qwen,或者 DeepSeek。重要的事说三遍:必须是通过 API,必须是通过 API,必须是通过 API。因为网页端有系统提示词,会做二次处理。

DeepSeek V4发布,比模型本身更受关注的,是一个根本性的转变: 国产算力生态正在从过去“芯片被动适配模型”的单向奔赴,迈向“芯模协同”的新阶段。
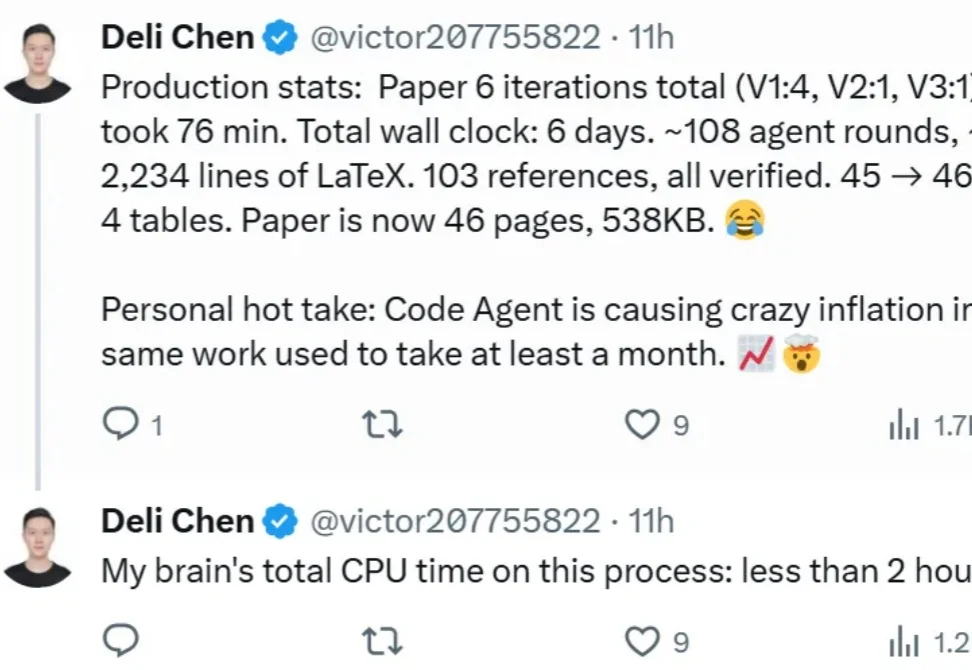
「借助 CodeAgent,我终于可以重新捡起很多过去因为精力不足而搁置的事情了,写博客就是其中之一。这篇博客大概 1% 是我写的,99% 是 Agent 写的 😂」。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。