
DeepSeek-V4 预览版:迈入百万上下文普惠时代
DeepSeek-V4 预览版:迈入百万上下文普惠时代今天,我们全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:
来自主题: AI资讯
9991 点击 2026-04-24 11:20
 搜索
搜索
今天,我们全新系列模型 DeepSeek-V4 的预览版本正式上线并同步开源。DeepSeek-V4 拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。模型按大小分为两个版本:
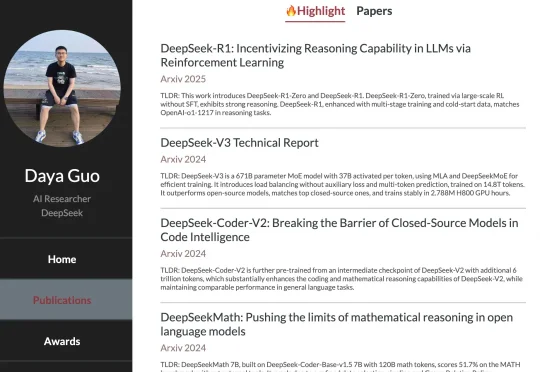
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。
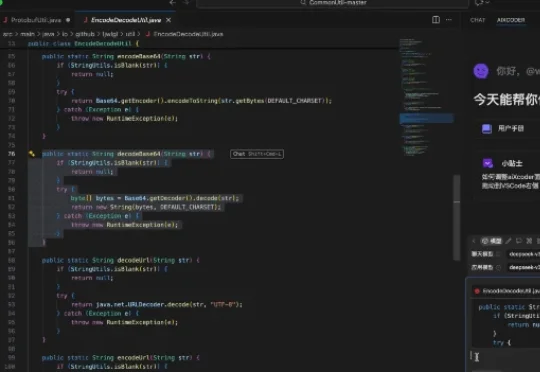
硅心科技(aiXcoder)发布了一款专为「代码变更应用」场景设计的高性能、轻量级模型 aiX-apply-4B。基准测试结果显示,在 20 多种主流编程语言及 Markdown 等多类型文件格式的测试中,aiX-apply-4B 的平均准确率达到 93.8%,超越 Qwen3-4B 基座模型 62.6% 的准确度

我们独家获悉,外界千呼万唤的DeepSeek-V4将于4月正式上线。作为梁文锋打磨已久的多模态大模型,DeepSeek-V4除了在Coding能力上跃升之外,还将在LTM(long term memory长期记忆)上取得突破。
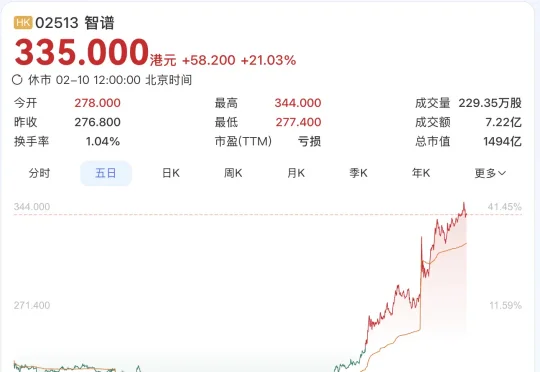
不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。
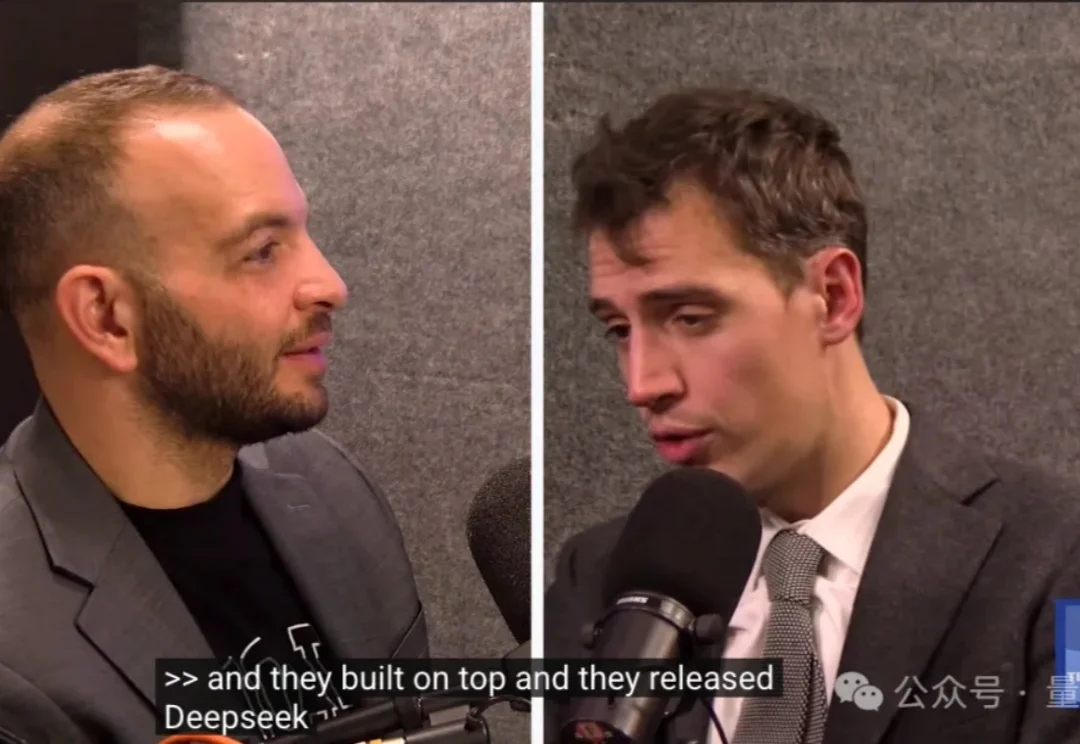
“DeepSeek-V3是在Mistral提出的架构上构建的。”

面对《the Big Technology Podcast》抛出的问题,Mistral AI的 CEO Arthur Mensch 表示:大模型肯定会走向商品化,当模型表现越来越接近,那么竞争就不在于模型本身,而在于如何让客户用起来。

机器之心发布 随着 ChatGPT、Gemini、DeepSeek-V3、Kimi-K2 等主流大模型纷纷采用混合专家架构(Mixture-of-Experts, MoE)及专家并行策略(Expert

开源模型再次迎来一位重磅选手,就在刚刚,小米正式发布并开源新模型 MiMo-V2-Flash。