
Meta抄袭DeepSeek大翻车?硅谷大佬爆料亮点满满,AI军备烧钱真相震碎硅谷
Meta抄袭DeepSeek大翻车?硅谷大佬爆料亮点满满,AI军备烧钱真相震碎硅谷谁会第一个到达ASI?SemiAnalysis大佬Dylan Patel脱口而出:OpenAI!最近,这位圈内最懂AI和芯片的大佬,毫不留情地戳穿了GPT-4.5惨败的原因,还揭露了Meta仓促模仿DeepSeek结果大翻车的内幕。
来自主题: AI资讯
8134 点击 2025-07-02 11:17
 搜索
搜索
谁会第一个到达ASI?SemiAnalysis大佬Dylan Patel脱口而出:OpenAI!最近,这位圈内最懂AI和芯片的大佬,毫不留情地戳穿了GPT-4.5惨败的原因,还揭露了Meta仓促模仿DeepSeek结果大翻车的内幕。

超大规模MoE模型(如DeepSeek),到底该怎么推理才能做到又快又稳。现在,这个问题似乎已经有了标准答案——华为一个新项目,直接把推理超大规模MoE背后的架构、技术和代码,统统给开源了!

OpenAI 有个反常规的设定, 他们将我生成的图片整理成一个画廊,但是点开图片并没有跳回到当时对话的选项,只能在这张图的基础上修改。 这也是很多AI目前的交互通病, 我和他们的对话正在丢失。
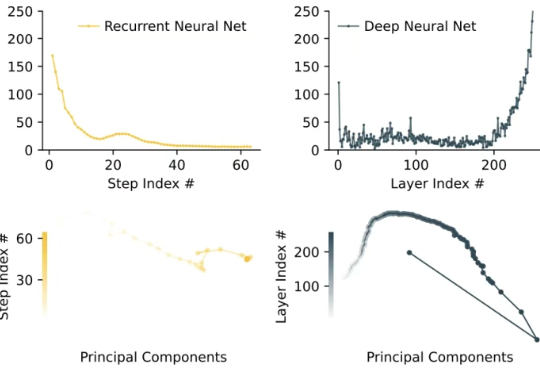
像人一样推理。 大模型的架构,到了需要变革的时候? 在对复杂任务的推理工作上,当前的大语言模型(LLM)主要采用思维链(CoT)技术,但这些技术存在任务分解复杂、数据需求大以及高延迟等问题。

今年2月DeepSeek爆火,震惊国内外。实际上,在此之前,中国信息通信研究院(下称:中国信通院)的大模型评测团队就观察到国内模型性能迅速提升的势头,他们当中就包括中国信通院人工智能研究所所长魏凯。

图像模型开源还得是FLUX!Black Forest Labs刚刚宣布开源旗舰图像模型FLUX.1 Kontext[dev],专为图像编辑打造,还能直接在消费级芯片上运行。


全网翘首以盼的DeepSeek-R2,再次被曝推迟!据The Information报道,由于DeepSeek CEO梁文锋始终对R2的表现不满意,因此R2迟迟未能发布。此外,他们还援引两位国内知情人士的消息称,R2研发进程缓慢可能是由于缺少英伟达H20芯片。
这两天Google推出了Gemini-CLI这个编程工具,功能和Claude Code基本一致,结果根本排不上队,登录一下很快闪退,和下图一样,使用感受令人不愉悦。很多人都在等着体验这个新工具,但现实是您可能要等很久才能轮到。
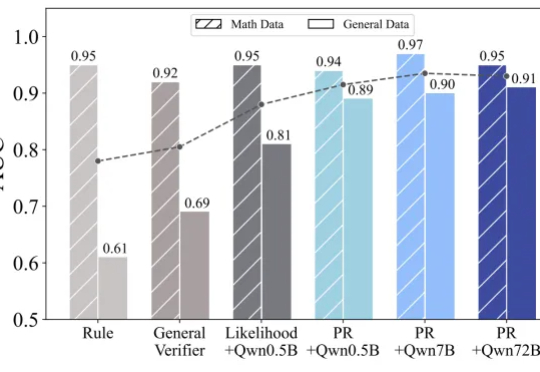
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward