为什么 DeepSeek 大规模部署很便宜,本地很贵
为什么 DeepSeek 大规模部署很便宜,本地很贵为什么 DeepSeek-V3 据说在大规模服务时快速且便宜,但本地运行时却太慢且昂贵?为什么有些 AI 模型响应很慢,但一旦开始运行就变得很快?
来自主题: AI技术研报
10057 点击 2025-07-08 11:14
 搜索
搜索
为什么 DeepSeek-V3 据说在大规模服务时快速且便宜,但本地运行时却太慢且昂贵?为什么有些 AI 模型响应很慢,但一旦开始运行就变得很快?

现在市面上有46种Prompt工程技术,但真正能在软件工程任务中发挥作用的,可能只有那么几种。来自巴西联邦大学、加州大学尔湾分校等顶级院校的研究者们,花了大量时间和计算资源,调研了58种,整理了46种,最终筛选测试了14种主流提示技术在10个软件工程任务上的表现,用了4个不同的大模型(包括咱们的Deepseek-V3),总共跑了2000多次实验。
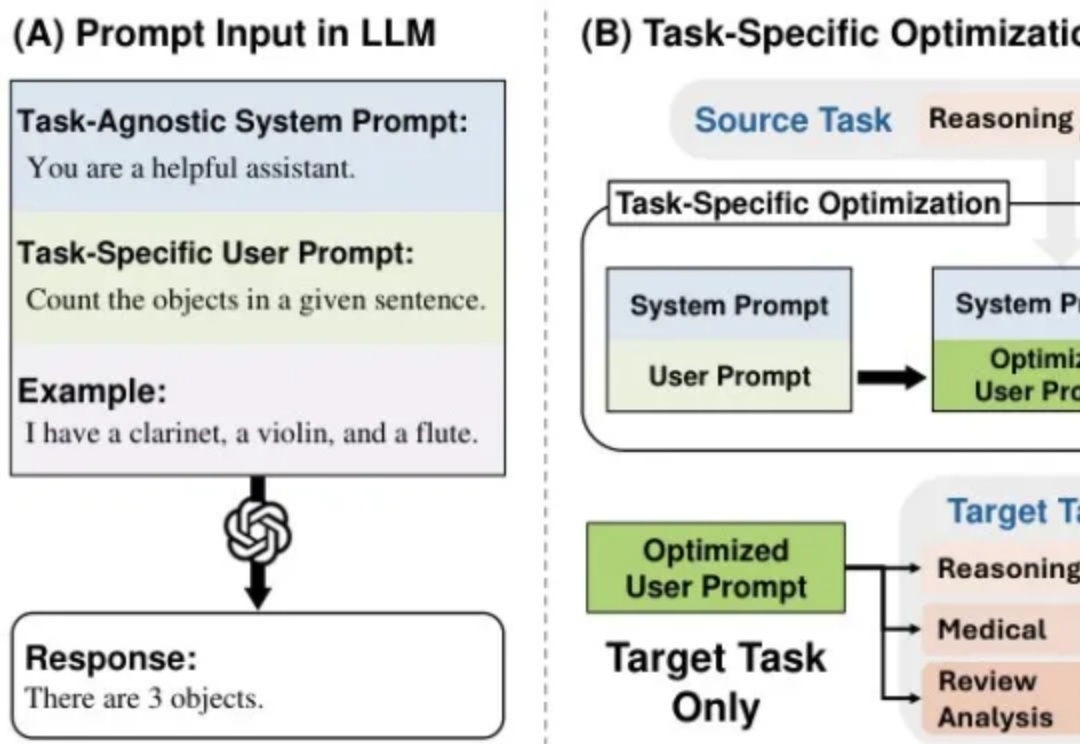
每次更换语言模型就要重新优化提示词?资源浪费且效率低下!本文介绍MetaSPO框架,首个专注模型迁移系统提示优化的元学习方法,让一次优化的提示可跨模型通用。我在儿童教育场景的实验验证了效果:框架自动生成了五种不同教育范式的系统提示,最优的"苏格拉底式"提示成功由DeepSeek-V3迁移到通义千问模型,评分从0.3920提升至0.4362。

就在刚刚,DeepSeek 在全球最大 AI 开源社区 Hugging Face 发布了一个名为 DeepSeek-Prover-V2-671B 的新模型。
借助新版DeepSeek-V3,任何人现在可以一次性创建任何应用或游戏了——
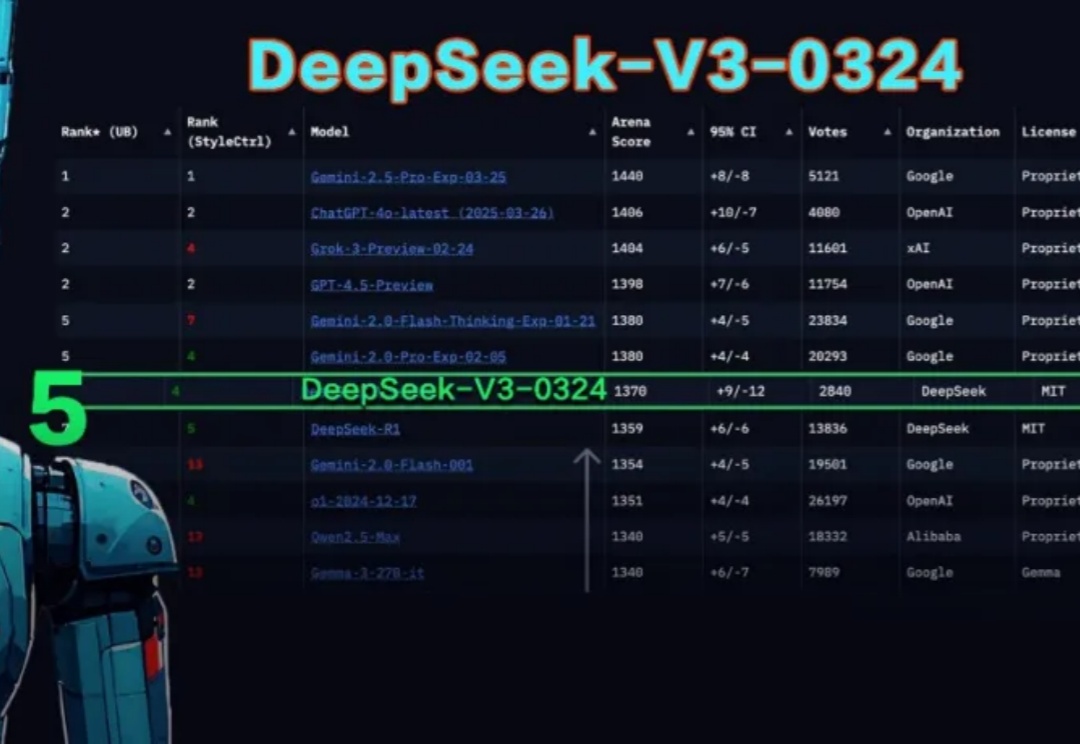
DeepSeek又卷起来了!上周刚出的DeepSeek-V3-0324在大模型竞技场排名中,打败了自己的DeepSeek-R1,成为开源AI至尊。
最近超火的氛围编程(Vibe coding)你听说了吗?
这项来自约翰霍普金斯与ETH Zurich的自主科研智能体框架AgentRxiv的确可以显著提高研究效率。我在测试了多次之后用Deepseek-V3-0324实现了它。

刚刚,DeepSeek官方发布DeepSeek-V3模型更新技术报告。V3新版本在数学、代码类相关评测集成绩超过GPT-4.5!而且这只是通过改进后训练方法实现。DeepSeek-V3-0324和之前的DeepSeek-V3使用同样的base模型。

685B的DeepSeek-V3新版本,就在昨夜悄悄上线了。参数量685B的V3,代码数学推理再次显著提升,甚至代码追平Claude 3.7,网友们实测后大呼强到离谱!有人预测说,按照此前的节奏,DeepSeek-R2大概率几周内就将上线。