
训练机器人方式对了吗?英伟达DreamZero双榜第一新反思
训练机器人方式对了吗?英伟达DreamZero双榜第一新反思近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。
来自主题: AI技术研报
10217 点击 2026-03-04 14:32
 搜索
搜索
近日,NVIDIA 发布的世界 - 动作模型 DreamZero,在两项颇具代表性的机器人基准测试 RoboArena 、MolmoSpaces 上双双登顶。
新模型对标Nano Banana Pro,能免费体验。Seedance 2.0的热度还没下去,字节新模型又来了!今日,字节图像生成模型Seedream 5.0 Preview在视频编辑应用剪映、剪映海外版Capcut、字节AI创作平台小云雀均已上线,在即梦AI平台开启灰度测试,图片生成可限时免费体验。

驱动具身智能进入通用领域最大的问题在哪里?

中山大学等机构推出SpatialDreamer,通过主动心理想象和空间推理,显著提升了复杂空间任务的性能。模拟人类主动探索、想象和推理的过程,解决了现有模型在视角变换等任务中的局限,为人工智能的空间智能发展开辟了新路径。
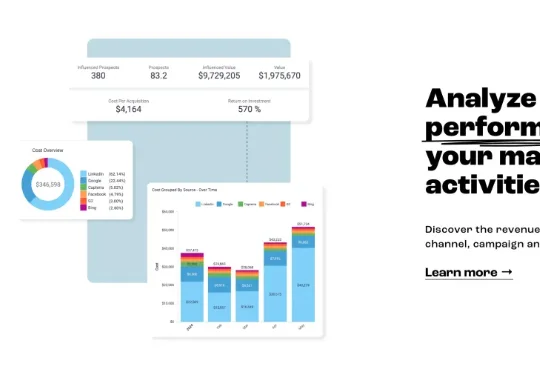
最近,这家总部位于哥本哈根和纽约的公司宣布完成了 5500 万美元的 B 轮融资。这轮融资让 Dreamdata 的总融资额达到了 6700 万美元。在 AI 时代,营销人员需要一个真正属于自己的操作系统,而 Dreamdata 正在构建这样一个平台。

就在最近,豆包上新了图像创作模型 Doubao-Seedream-4.5(以下简称 Seedream 4.5)。 猜猜下面两张图片,哪张是 Seedream 4.5 生成的?哪张是最近风头正盛的 Nano Banana Pro 生成的?

豆包升级上新,火山引擎带着图像创作模型Doubao-Seedream-4.5来了。新模型有三个主打点。一是强化了原图保持能力,最大化保持原图的人脸、光影与色调、画面细节,可以用来P图。例如“只保留绿线中的人物,将其他角色都删掉”:

华为在世界模型上又有新动作:投了一家物理AI公司。

谷歌世界模型大牛Danijar Hafner宣布离任!他自2016年起开始在Google Brain实习,后又在DeepMind、Brain Team工作。他的经历颇具传奇色彩,曾获辛顿指导,还与Łukasz Kaiser、Ashish Vaswani等Transformer大佬有过交集。

你永远无法精确描述出梵高的笔触或王家卫的光影。AI创作的未来,是让AI直接「看懂」你的灵感,而不是去揣摩你的指令。