
给6个AI各发10万美元炒股半年,大部分跑赢了大盘
给6个AI各发10万美元炒股半年,大部分跑赢了大盘一家叫 Rallies Arena 的团队,6 个月前干了一件事:给 6 个主流大模型各发了 10 万美元,让它们在真实股票市场上自己做研究、自己下单、自己管仓位。
来自主题: AI资讯
8965 点击 2026-04-07 11:04
 搜索
搜索
一家叫 Rallies Arena 的团队,6 个月前干了一件事:给 6 个主流大模型各发了 10 万美元,让它们在真实股票市场上自己做研究、自己下单、自己管仓位。
2 个人,年入 4 亿美元,每天进账 300 万美元。Matthew Gallagher 和他弟弟搭起了一家卖减肥药的公司 Medvi,2025 年营收 4.01 亿美元。今年生意爆了,日均收入超过 300 万美元,全年目标 18 亿。

《读佳》获悉,腾讯近期正在开发一款AI助手产品“Vedas AI”,定位是聪明可靠的AI助手,帮用户做数据分析,写PPT,搭网页,出调研报告,还能自动跑任务。不过该产品还未对外公开使用。 从产品的描述
不过,最近有个好用的破局工具。LibTV终于接入了万众瞩目的Seedance 2.0!最关键的是,在LibTV里跑Seedance 2.0,速度非常快,几分钟就能出一条高质量的视频,彻底治好了我的排队焦虑。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。

生物医学AI智能体正从「能不能做组学分析」快速进入下一阶段的检验:做出来的结果,能不能撑得住真实的治疗决策?哈佛医学院Zitnik团队的MEDEA 给出了一条明确的技术路线:与其追求更强的骨干大模型,不如在分析流程的每一步嵌入验证机制。
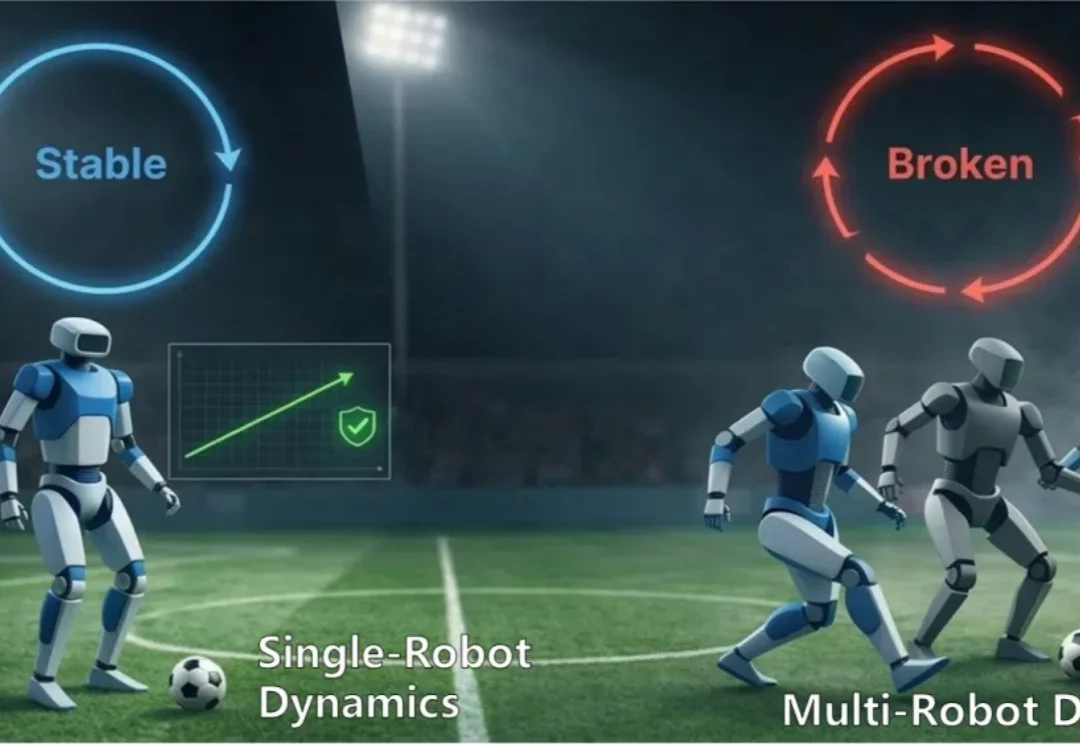
近年来,Decision-Coupled World Model 与 Model-based RL 在机器人领域取得了显著成功。通过学习环境动力学模型,智能体能够在内部模拟未来,从而进行规划与决策。但当系统从单机器人扩展到多机器人时,问题开始变得棘手。

相似度超越Seed-TTS、MiniMax-Speech等知名模型。昨晚,美团LongCat团队发布了文本转语音模型LongCat-AudioDiT,并开源1B、3.5B参数量的版本。这一模型的最大特点,是彻底抛弃了梅尔谱等中间表示,直接在波形潜空间进行基于扩散模型的文本转语音。通俗地说,这一模型直接根据声音本身的规律进行生成,“雕刻”出最原始的声音波形,从根源阻断数据转换的级联误差。

3月30日,阿里巴巴内部发布了 Wan2.7-Image 图像生成与编辑统一模型。根据官方公布的数据,在人类偏好盲测评分中,Wan2.7-Image 目前位列国内第一。从放出的评测雷达图来看,无论是文本生图(Text-to-Image)还是综合图像编辑(Image Editing),它的各项指标基本都盖过了市面上主流的几家头部模型。

全世界都在等ASI降临,OpenAI却在年初悄悄上线广告位。9亿用户撑不起数百亿美元的算力账单,智力正在贬值,神仙也得下凡赚钱!