Florence-VL来了!使用生成式视觉编码器,重新定义多模态大语言模型视觉信息
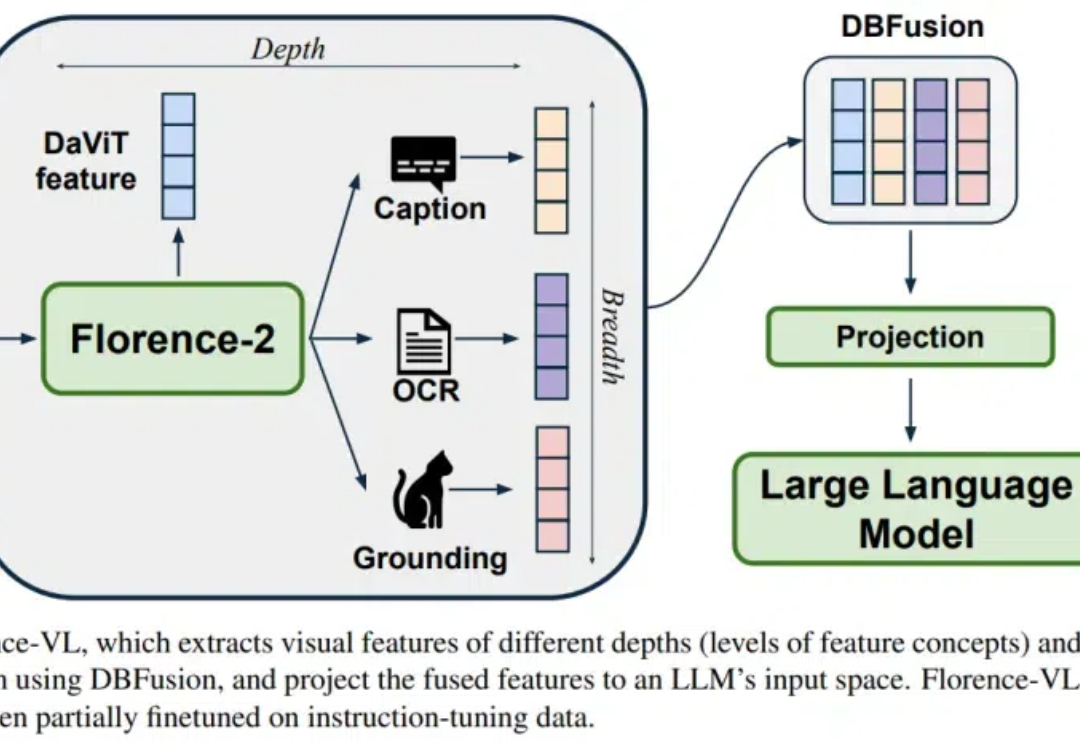
Florence-VL来了!使用生成式视觉编码器,重新定义多模态大语言模型视觉信息Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。
来自主题: AI技术研报
9281 点击 2024-12-18 14:21
 搜索
搜索
Florence-VL 提出了使用生成式视觉编码器 Florence-2 作为多模态模型的视觉信息输入,克服了传统视觉编码器(如 CLIP)仅提供单一视觉表征而往往忽略图片中关键的局部信息。