
GPT-4.5功臣遭驱逐!奥特曼盛赞工作出色,美国深陷AI人才危机
GPT-4.5功臣遭驱逐!奥特曼盛赞工作出色,美国深陷AI人才危机近日,GPT-4.5核心开发者之一的Kai Chen因绿卡申请被拒,面临被迫离开美国的困境。与此同时,1700多名国际学生和研究人员因签证审查受阻,Nature调查显示75%的美国科学家正考虑逃离。这种人才流失或将影响美国在全球AI领域的领先地位。
来自主题: AI资讯
9890 点击 2025-04-26 17:24
近日,GPT-4.5核心开发者之一的Kai Chen因绿卡申请被拒,面临被迫离开美国的困境。与此同时,1700多名国际学生和研究人员因签证审查受阻,Nature调查显示75%的美国科学家正考虑逃离。这种人才流失或将影响美国在全球AI领域的领先地位。
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。

人工生命的革命来临!帝国理工的研究人员,开源了名为CAX的硬件加速工具。只需几行代码,就能复刻人工生命实验,模拟速度可提升2000倍,部分表现甚至超过了GPT-4!

GPT-4o带火的漫画风角色生成,现在有了开源版啦!

一句话看懂:o3以深度推理与工具调用能力领跑复杂任务,GPT-4.1超长上下文与精准指令执行适合API开发,而o4-mini则堪称日常任务的「性价比之王」。

GPT-4o更新的端到端多模态模型,让创意端获得前所未有的自由度。

不止GPT-4o可以制作吉卜力风格图像!更多工具都可以制作吉卜力风图像。甚至2分钟之内,还能用照片生成吉卜力风格动画:蒙娜丽莎给你说Hello。

港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。
两个月后就号称要淘汰GPT-4.5的GPT-4.1,实力究竟如何?在众多实测中,它的表现的确可圈可点,但却依然打不过Gemini 2.5 Pro和Claude 3.7 Sonnet。那么问题来了,OpenAI为何要发布一个远远落后于谷歌的模型?
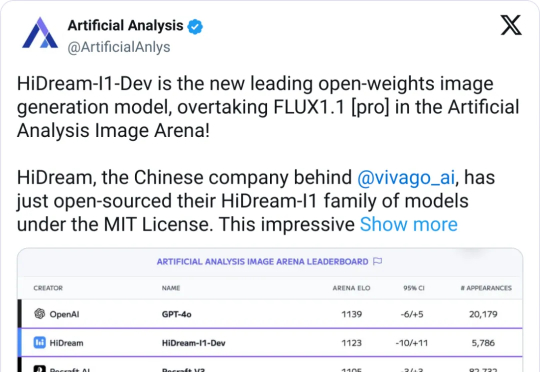
刚出道的 HiDream-I1,拿下了 Hugging Face 趋势榜第二(图像榜第一),Artificial Analysis 文生图第二,排在Midjourney、Google Imagen、FLUX、SDXL 之前,仅次于 GPT-4o 。