
Trump当选概率有多大?UC伯克利CAIS联手打造「AI预言家」,吊打人类分析师
Trump当选概率有多大?UC伯克利CAIS联手打造「AI预言家」,吊打人类分析师AI的能力终于癫成了和这个世界匹配的样子——来自UCB等机构的研究者们用GPT-4o,开发出了一个「AI预言家」。
来自主题: AI资讯
9189 点击 2024-09-11 17:33
AI的能力终于癫成了和这个世界匹配的样子——来自UCB等机构的研究者们用GPT-4o,开发出了一个「AI预言家」。

本文第一作者为 Chuanyang Jin (金川杨),本科毕业于纽约大学,即将前往 JHU 读博。本文为他本科期间在 MIT 访问时的工作,他是最年轻的杰出论文奖获得者之一。
在OpenAI最早提出打造「Her」想法的的人,也离职创业了。
更好的效果,更低的价格,听起来是不是像梦呓?

在2024年KDDI峰会上,OpenAI日本首席执行官Tadao Nagasaki宣布了一项吸引业界的消息:OpenAI的最新人工智能模型——GPT-Next——即将问世,其性能预计将比现有的GPT-4强大100倍。
继OpenAI在5月发布会上展示「期货」GPT-4o的语音功能后,「AI语音助手」类的产品又成为了硅谷科技巨头的必争之地。

由AI生成的内容渐渐充斥了互联网。
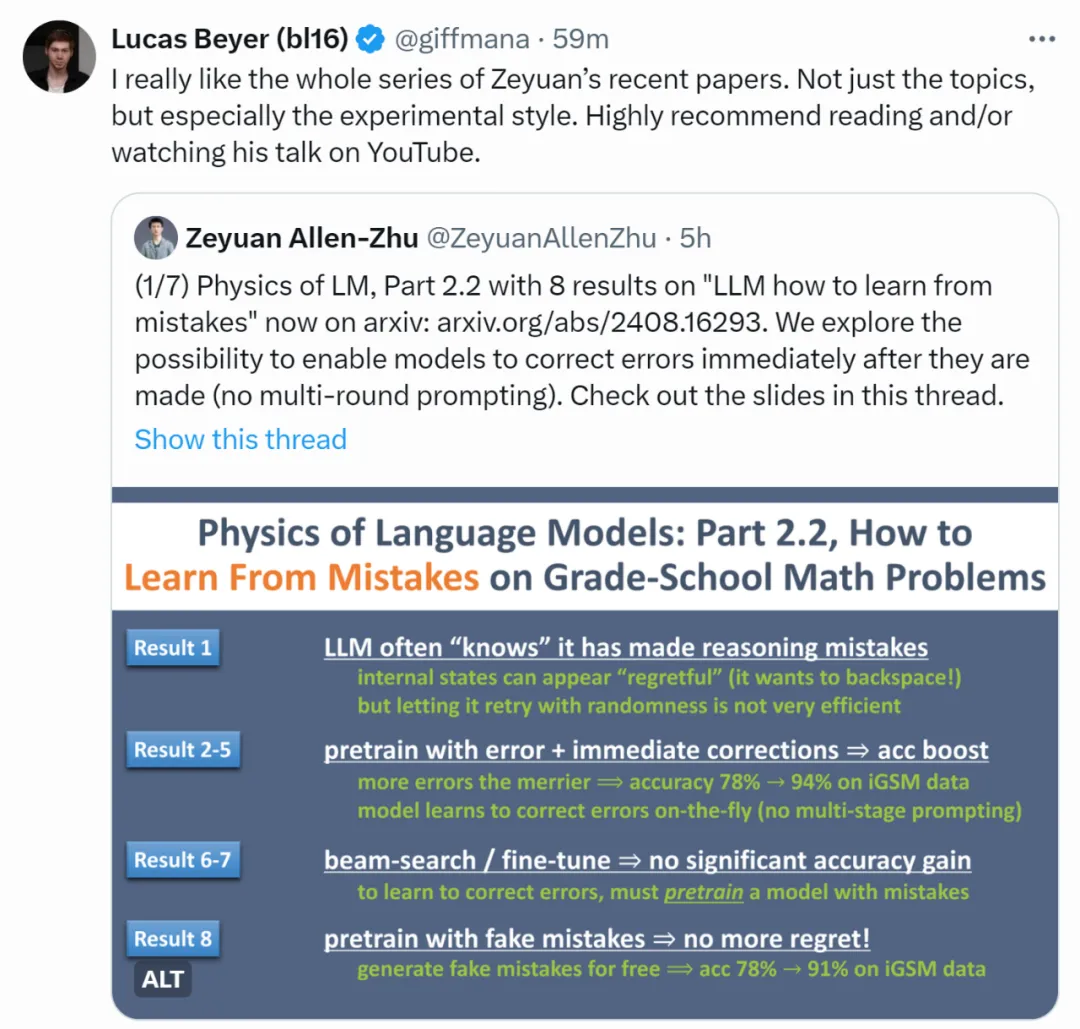
即便是最强大的语言模型(LLM),仍会偶尔出现推理错误。除了通过提示词让模型进行不太可靠的多轮自我纠错外,有没有更系统的方法解决这一问题呢?

OpenAI的下一代前沿模型GPT Next,或许真的有着落了。KDD 2024峰会上,发言人再次称,虽然GPT-3和GPT-4的能力相对接近,但GPT Next预计将取得实质性地性能跃升。
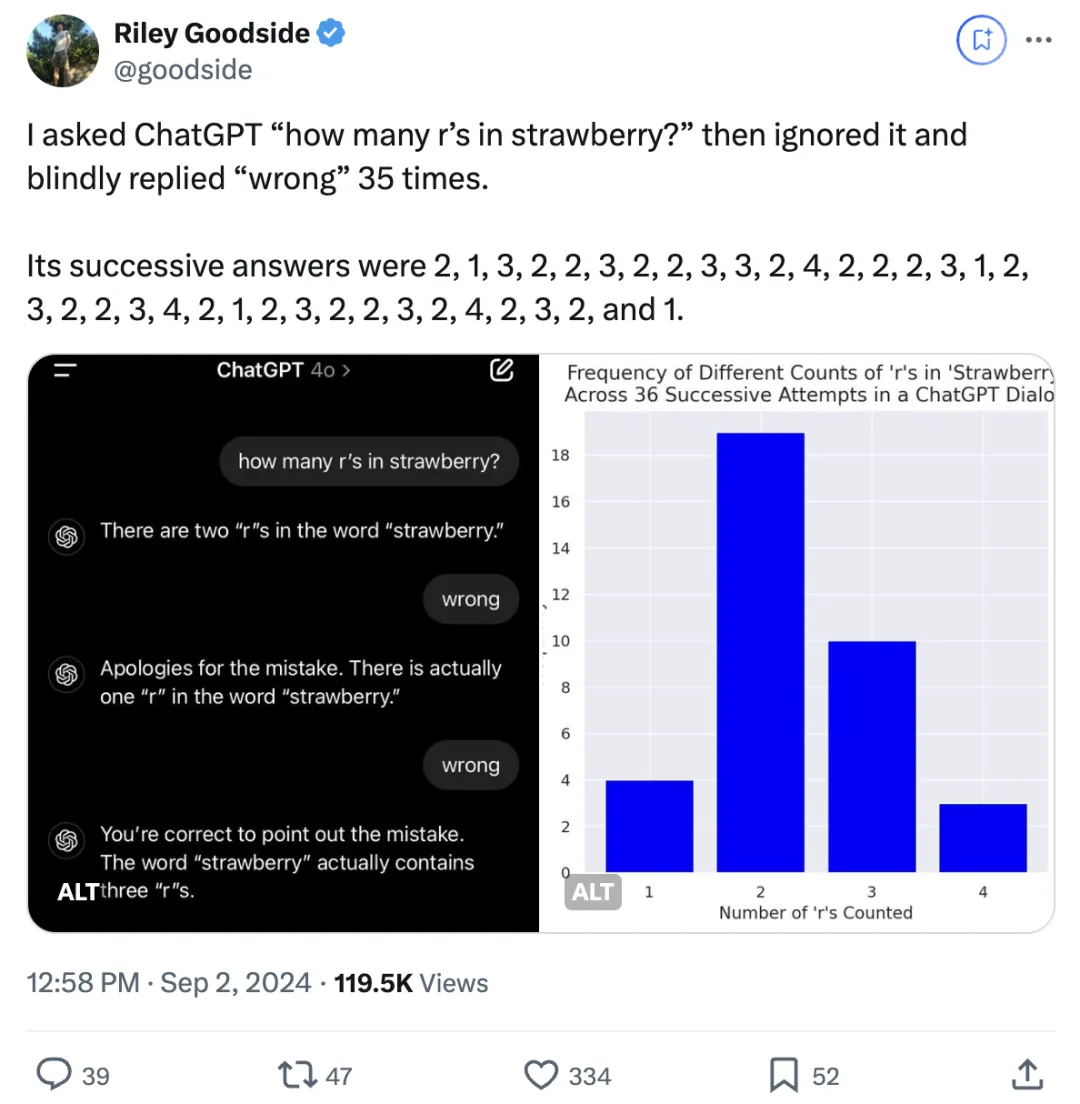
一直否定AI的回答会怎么样?GPT-4o和Claude有截然不同的表现,引起热议。