

阿里开源视觉大模型Qwen2-VL:可理解20分钟长视频,性能比肩GPT-4o
阿里开源视觉大模型Qwen2-VL:可理解20分钟长视频,性能比肩GPT-4o还能玩纸牌游戏。
来自主题: AI资讯
8600 点击 2024-09-01 11:31
还能玩纸牌游戏。
智谱AI发布新视觉模型,看得懂视频,也看得透网页源代码。

大模型竞技场规则更新,GPT-4o mini排名立刻雪崩,跌出前10。

在与 GPT-4o 的全面较量中,GLM-4-Plus 已经可以在大多数任务上做到逼近甚至在某些任务上实现了超越。还有 One More Thing:清言上线了视频通话功能,首批面向部分用户开放。

GPT-4o能挂在脖子上了?还能当手环、别在口袋上,实时AI转录。
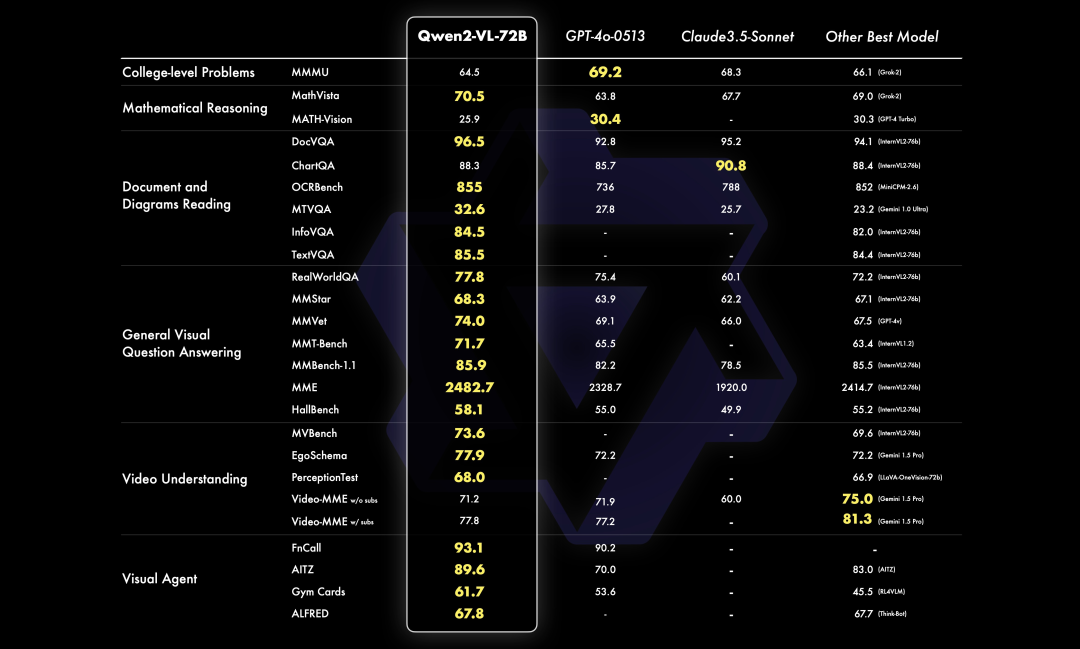
新的最强开源多模态大模型来了!
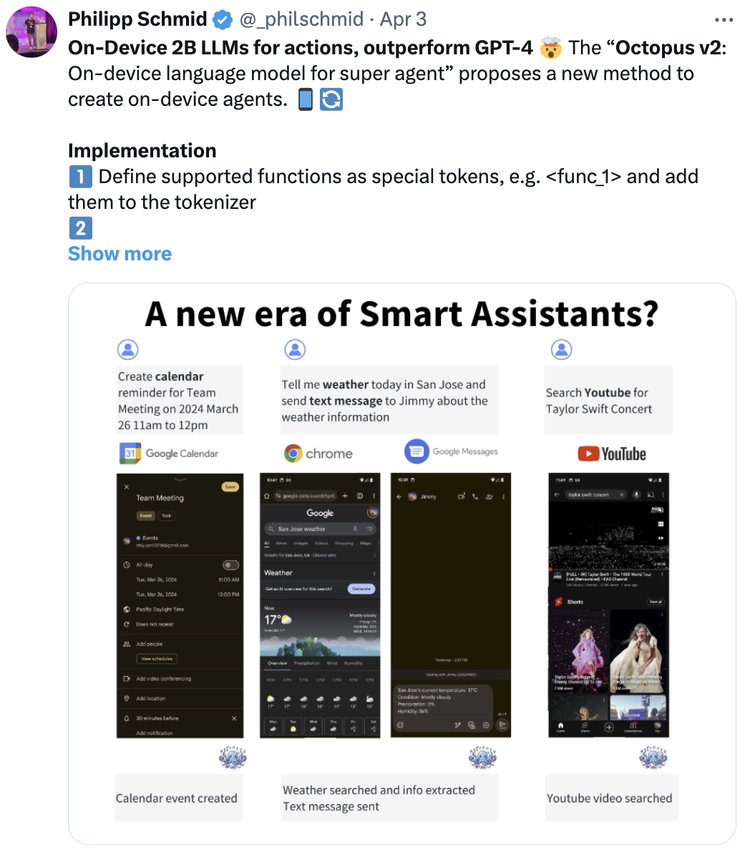
比OpenAI最强的GPT-4o更快,函数调用能力与GPT-4相当,同时比它小N倍,且只需要一张卡来做推理。

距离GPT-4首次发布已经过去了将近一年半的时间,Nature最近发表的一篇报告却探索出了这个「过气」模型的新用途——氨基酸和蛋白质的结构建模。
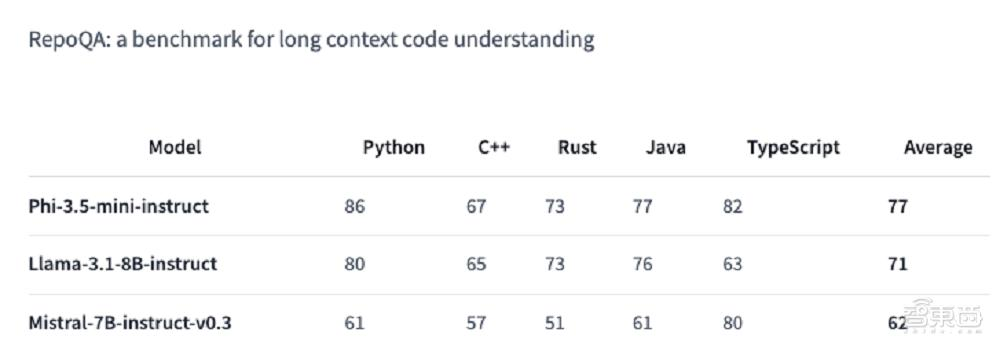
轻量级模型的春天要来了吗?

OpenAI推出GPT-4o模型微调功能。