

ChatGPT版「Her」被玩疯:哭着读诗,中文表现也很亮
ChatGPT版「Her」被玩疯:哭着读诗,中文表现也很亮上线仅仅一天,GPT-4o的高级语音功能(Advanced Voice Mode)简直要被玩疯了。无数网友脑洞大开的疯狂测试,GPT-4o这边呢,不仅各种奇葩任务全盘接收,表现好到更是让不少人连连惊呼“Blow my mind”。
来自主题: AI资讯
9430 点击 2024-08-01 15:43
上线仅仅一天,GPT-4o的高级语音功能(Advanced Voice Mode)简直要被玩疯了。无数网友脑洞大开的疯狂测试,GPT-4o这边呢,不仅各种奇葩任务全盘接收,表现好到更是让不少人连连惊呼“Blow my mind”。

赶在 7 月结束前,GPT-4o 语音功能终于开启。现开启灰度测试,一小部分 ChatGPT Plus 用户已经可以试用。

Meta、UC伯克利、NYU共同提出元奖励语言模型,给「超级对齐」指条明路:让AI自己当裁判,自我改进对齐,效果秒杀自我奖励模型。

苹果AI首登iPhone!47页论文曝自研模型,多项测评超GPT-4。

大型语言模型(LLM)展现出了令人印象深刻的智能水平。因此,确保其安全性显得至关重要。已有研究提出了各种策略,以使 LLM 与人类伦理道德对齐。然而,当前的先进模型例如 GPT-4 和 LLaMA3-70b-Instruct 仍然容易受到越狱攻击,并被用于恶意用途。
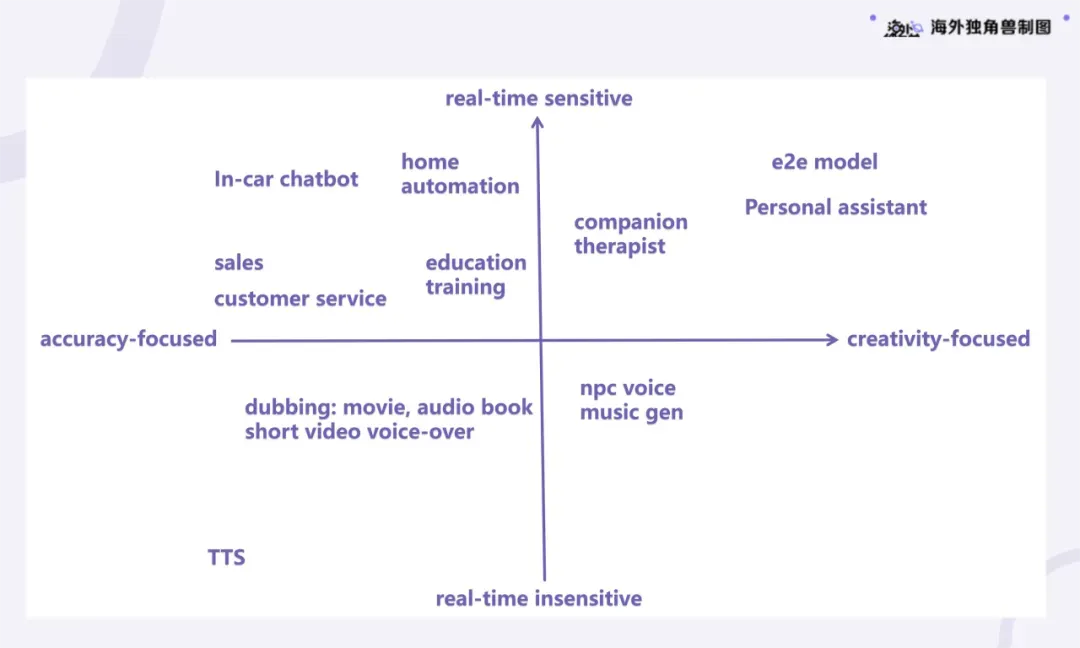
Voice Agent 是与人类进行对话沟通的 AI,是下一代人机交互界面。和文本相比,声音交互的优势主要体现在:
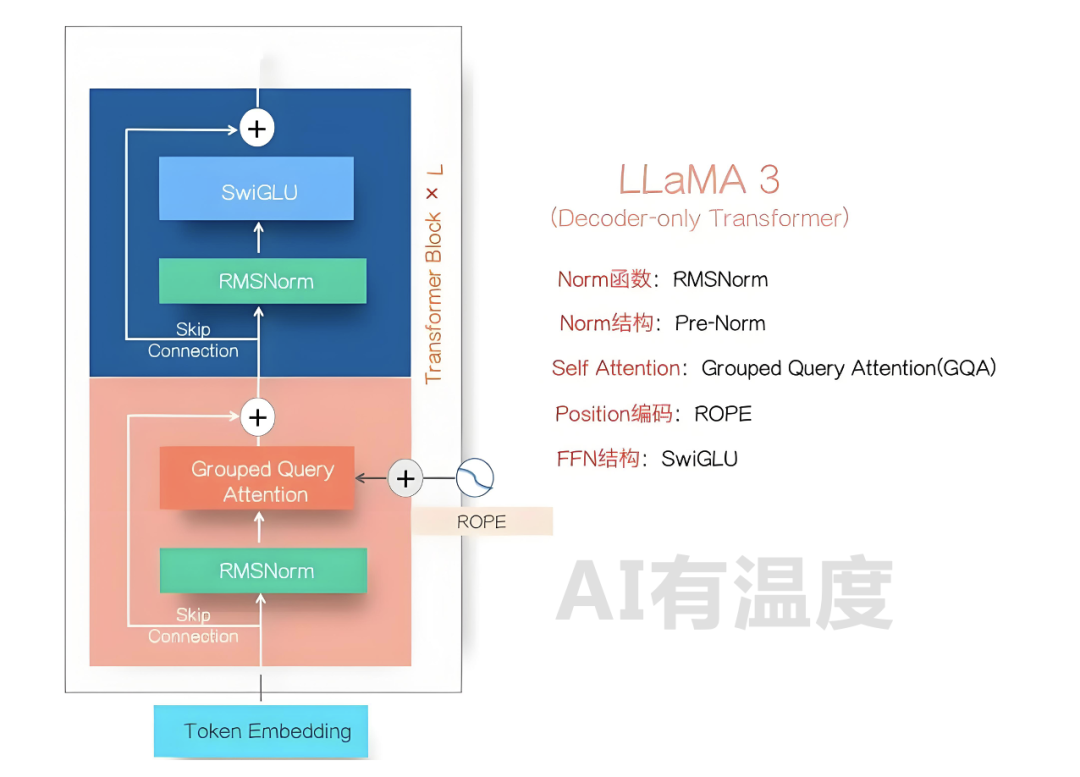
LLaMA3-405B的模型效果已经赶上目前最好的闭源模型GPT-4o和Claude-3.5,这可能是未来大模型开源与闭源的拐点,这里就LLaMA3的模型结构、训练过程与未来影响等方面说说我的看法。
随着人工智能(AI)技术的迅猛发展,特别是大语言模型(LLMs)如 GPT-4 和视觉语言模型(VLMs)如 CLIP 和 DALL-E,这些模型在多个技术领域取得了显著的进展。
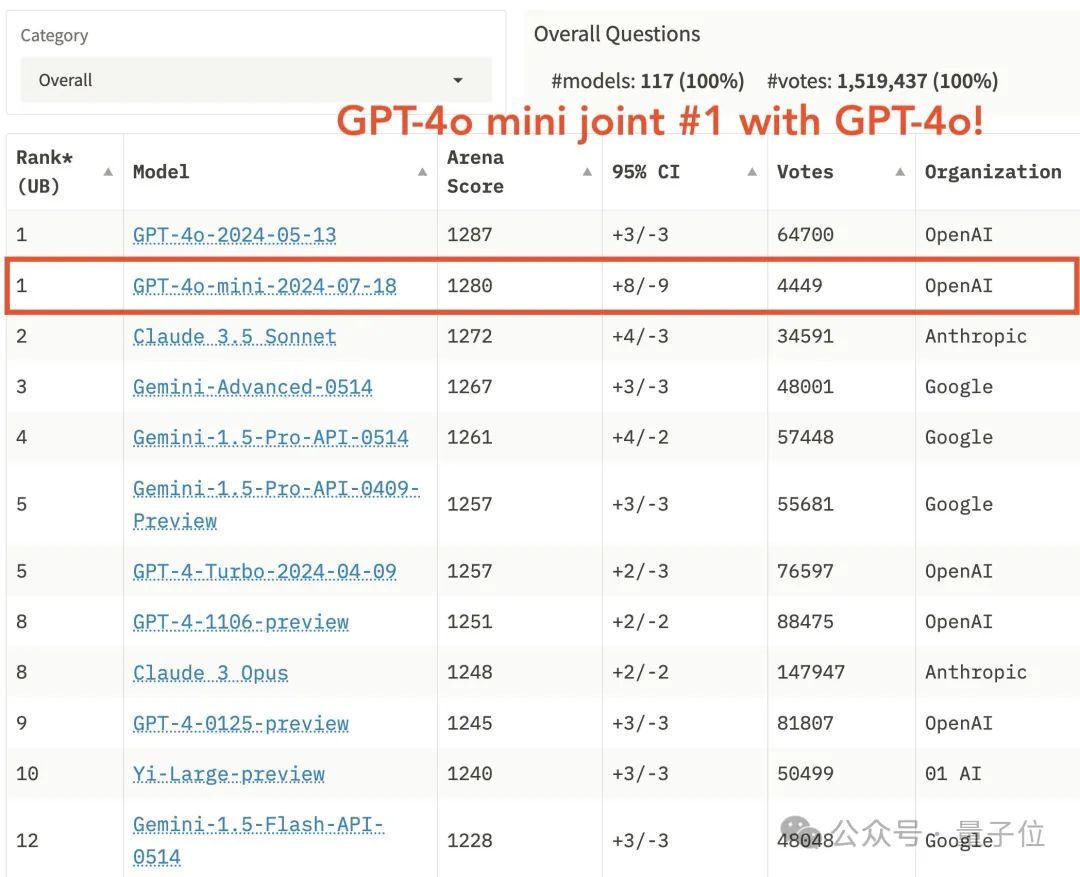
为啥GPT-4o mini能登顶大模型竞技场??

不是大模型用不起,而是小模型更有性价比。