

OpenAI,又要放大招了
OpenAI,又要放大招了智东西5月11日消息,今天凌晨,OpenAI宣布将于美国时间13日上午10点(北京时间14日凌晨1点)在官网直播,演示ChatGPT、GPT-4的更新内容。
来自主题: AI资讯
5811 点击 2024-05-11 15:05
智东西5月11日消息,今天凌晨,OpenAI宣布将于美国时间13日上午10点(北京时间14日凌晨1点)在官网直播,演示ChatGPT、GPT-4的更新内容。
在将近一年的时间里,他环游了无数国家,泰国、印尼、马来西亚、日本......陈云飞似乎在以“报复性旅游”的方式,告别自己十年的互联网工作。

2023-2024年,以 GPT-4V、Gemini、Claude、LLaVA 为代表的多模态大模型(Multimodal LLMs)已经在文本和图像等多模态内容处理方面表现出了空前的能力,成为技术新浪潮。
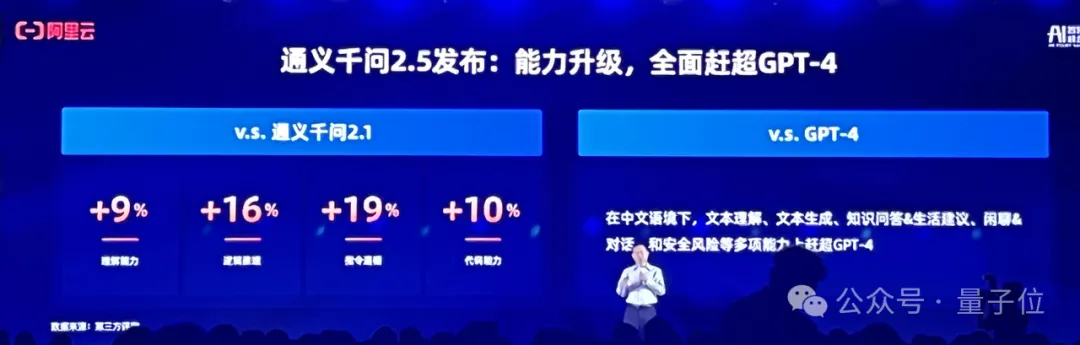
阿里云正式发布通义千问2.5大模型,同时宣布性能全面赶超GPT-4 Turbo。

芝麻粒大小的人脑组织,突触规模就相当于一个GPT-4!
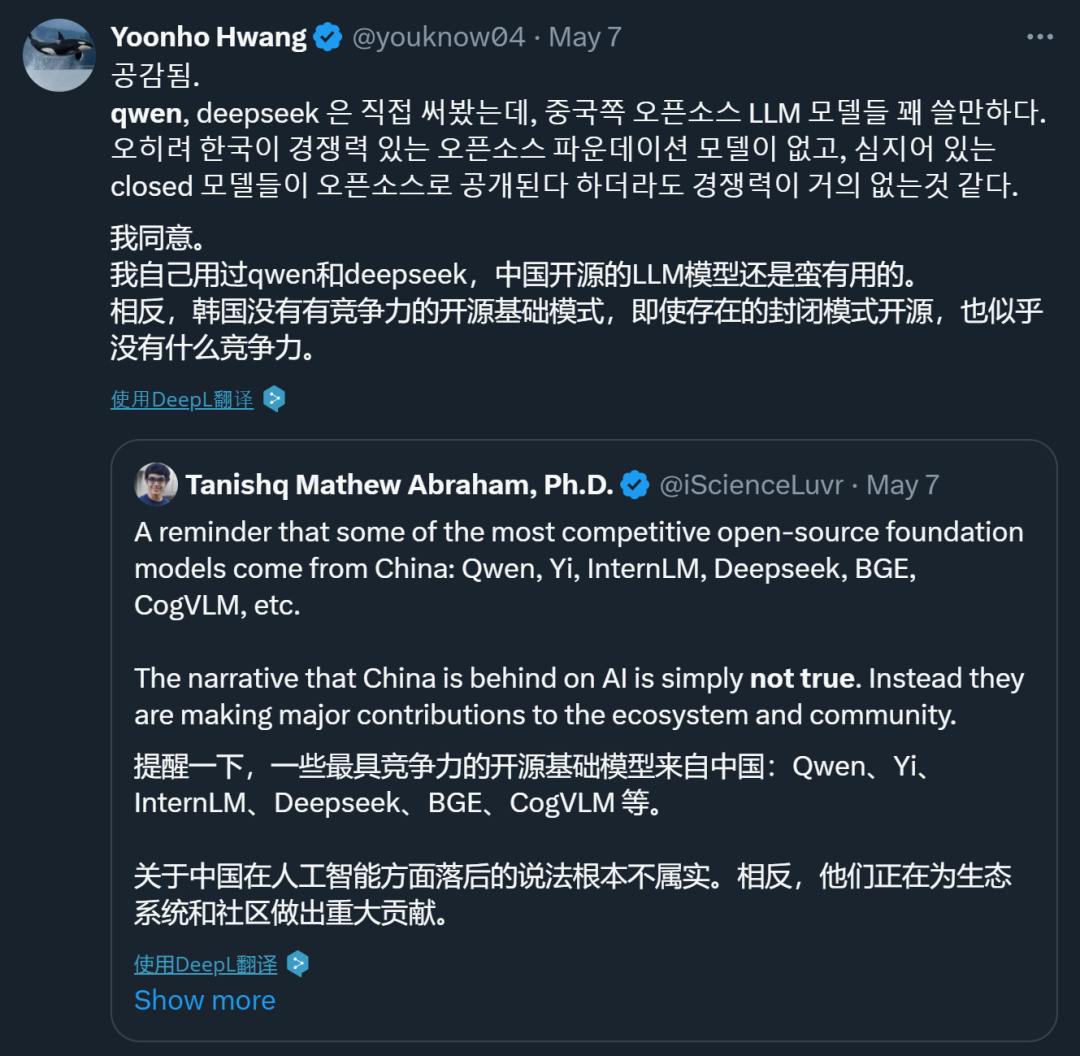
在发布一周年之际,阿里云通义千问大模型在闭源和开源领域都交上了一份满意的答卷。 国内的开发者们或许没有想到,有朝一日,他们开发的 AI 大模型会像出海的网文、短剧一样,让世界各地的网友坐等更新。甚至,来自韩国的网友已经开始反思:为什么我们就没有这样的模型?
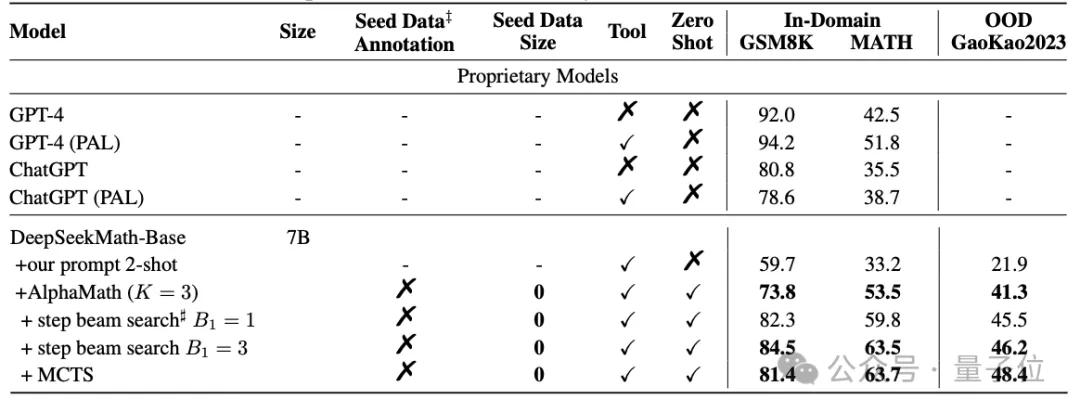
把AlphaGo的核心算法用在大模型上,“高考”成绩直接提升了20多分。

OpenAI正在秘密A/B测试下一代模型,实力超强被怀疑是GPT-4.5或GPT-5。

如今,AI进步的速度,已经超出了我们对它用途的理解。

开源大模型领域,又迎来一位强有力的竞争者。