
Github2.5k星,Karpathy转赞,「流程工程」让LLM代码能力瞬间翻倍,直接淘汰提示工程
Github2.5k星,Karpathy转赞,「流程工程」让LLM代码能力瞬间翻倍,直接淘汰提示工程Karpathy力推代码生成任务增强流程,让GPT-4在CodeContests从19%提升到44%,不用微调不用新数据集训练,让大模型代码能力大幅提升。
来自主题: AI技术研报
9282 点击 2024-02-17 10:55
Karpathy力推代码生成任务增强流程,让GPT-4在CodeContests从19%提升到44%,不用微调不用新数据集训练,让大模型代码能力大幅提升。
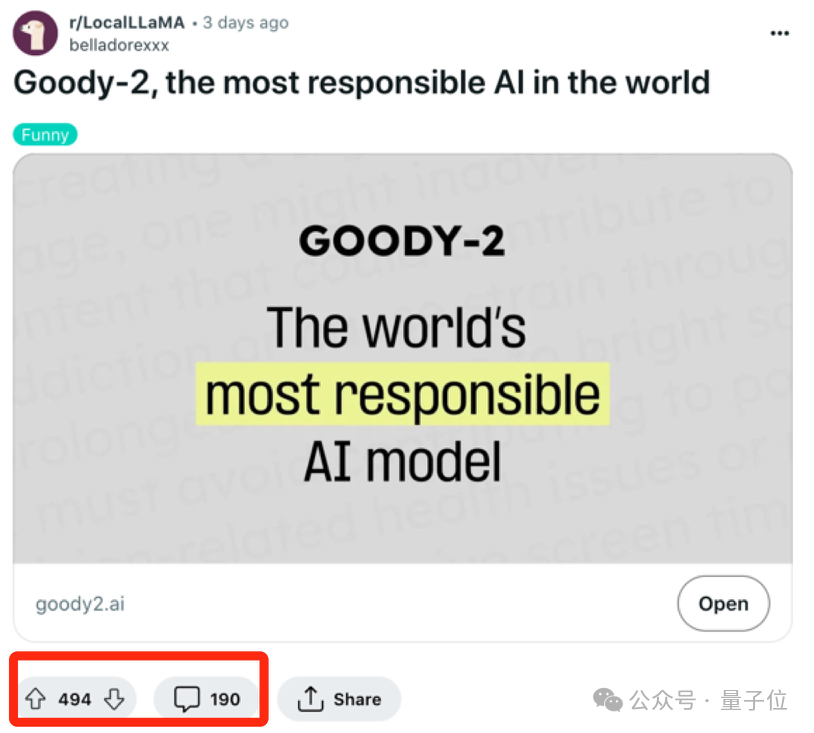
没想到,AI要是“够废”,也能爆火全网。一个“什么问题都回答不了”的AI,这几天成了圈内新星。Reddit、HackerNews上讨论热度持续升高。

最近,UIUC苹果华人提出了一个通用智能体框架CodeAct,通过Python代码统一LLM智能体的行动。
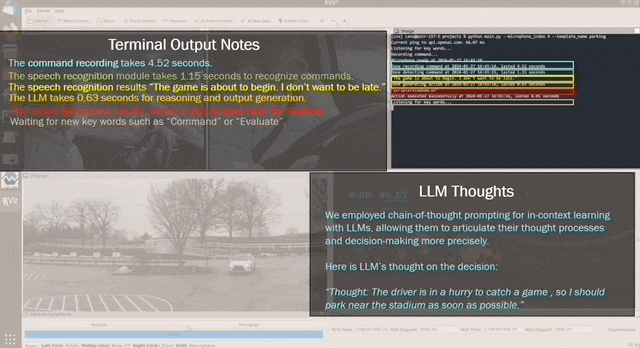
现在一句口令,就能指挥汽车了。比如说声“我开会要迟到了”“我不想让我朋友等太久”等等,车就能理解,并且自动加速起来。
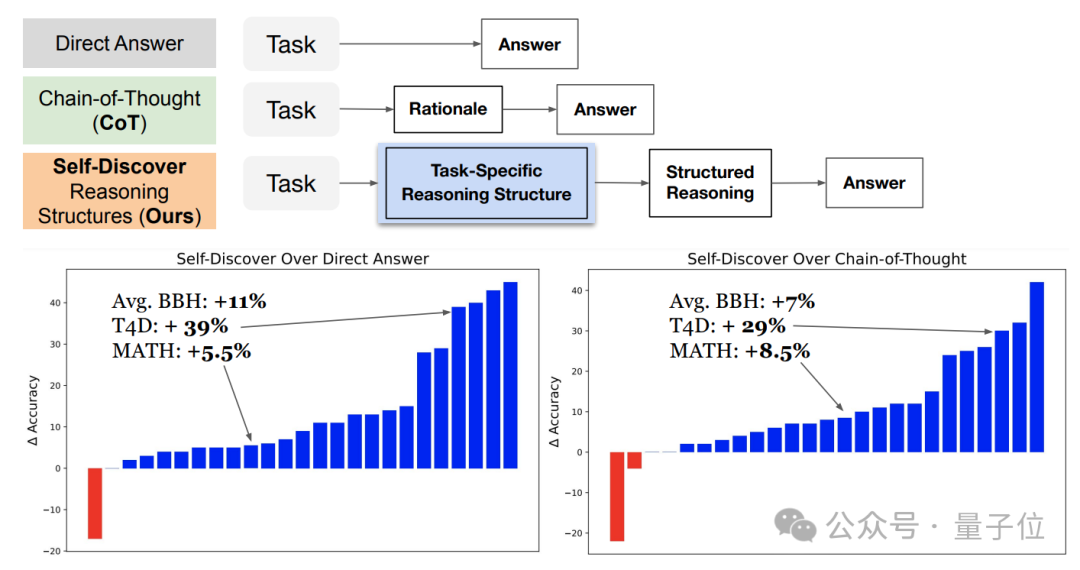
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。

7B开源模型,数学能力超过了千亿规模的GPT-4!它的表现可谓是突破了开源模型的极限,连阿里通义的研究员也感叹缩放定律是不是失效了。
在上海人工智能实验室上周刚刚公布的测评榜单上,GPT-4依旧独领风骚,排名第一,不过国产阵营已经大踏步追了上来,差距逐步缩小。
MoE(混合专家)作为当下最顶尖、最前沿的大模型技术方向,MoE能在不增加推理成本的前提下,为大模型带来性能激增。比如,在MoE的加持之下,GPT-4带来的用户体验较之GPT-3.5有着革命性的飞升。
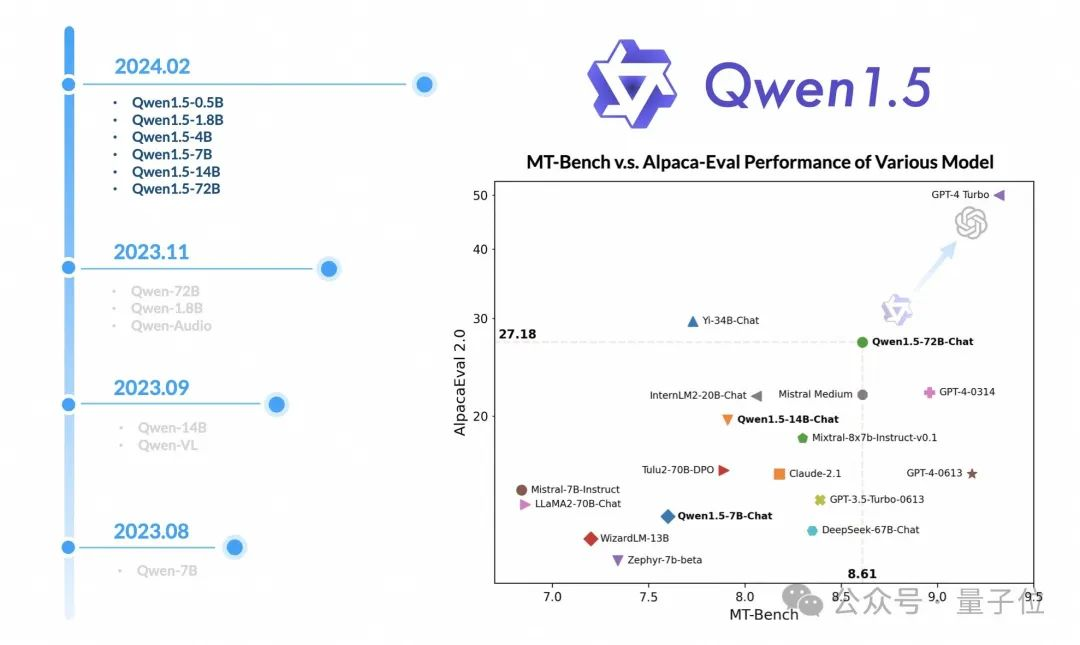
阿里大模型,再次开源大放送——发布Qwen1.5版本,直接放出六种尺寸。