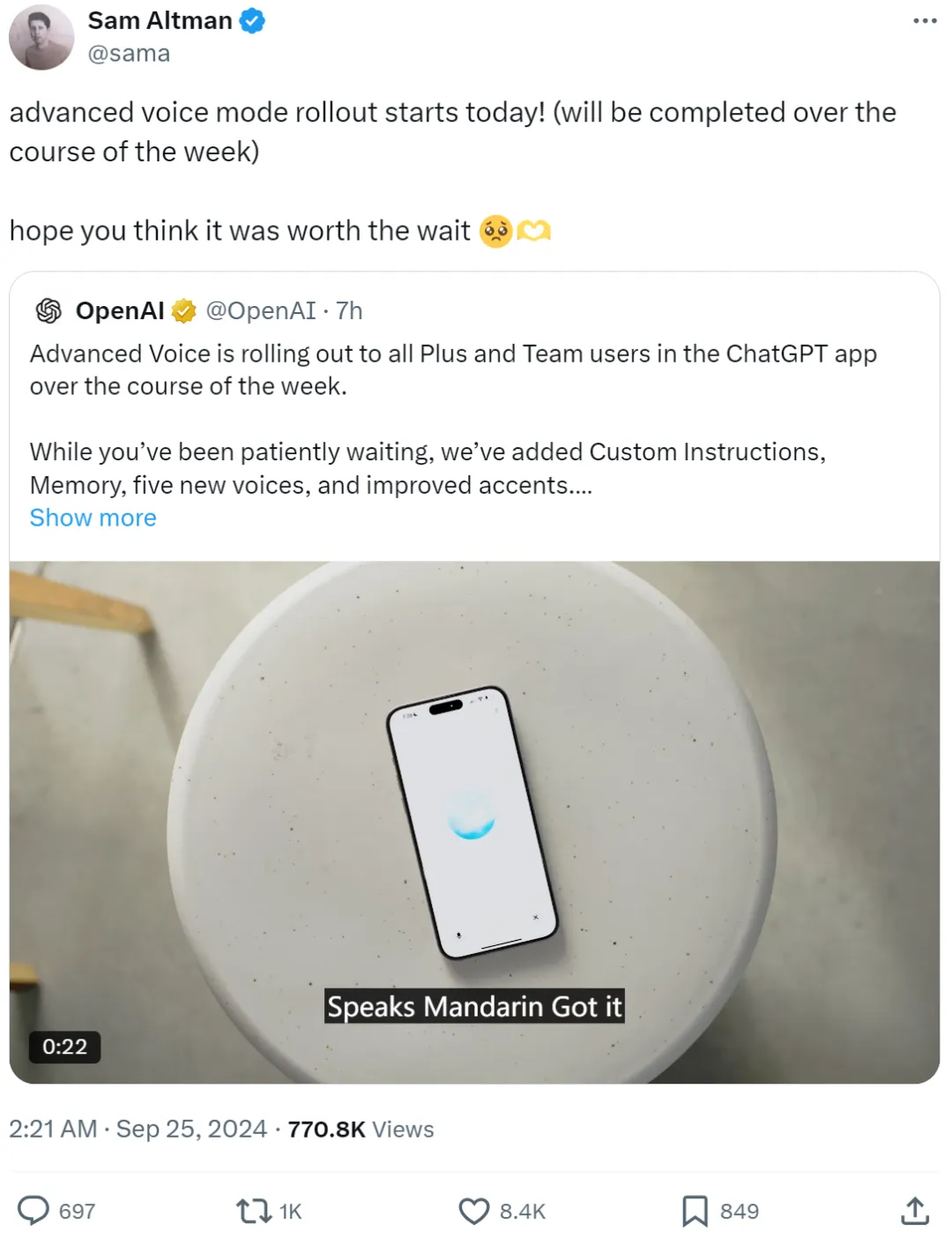
终于来了!OpenAI开放GPT-4o高级语音,还用中文说「对不起」
终于来了!OpenAI开放GPT-4o高级语音,还用中文说「对不起」这项高级语音功能,大家可是等了好久。
来自主题: AI资讯
8929 点击 2024-09-25 20:17
 搜索
搜索
这项高级语音功能,大家可是等了好久。
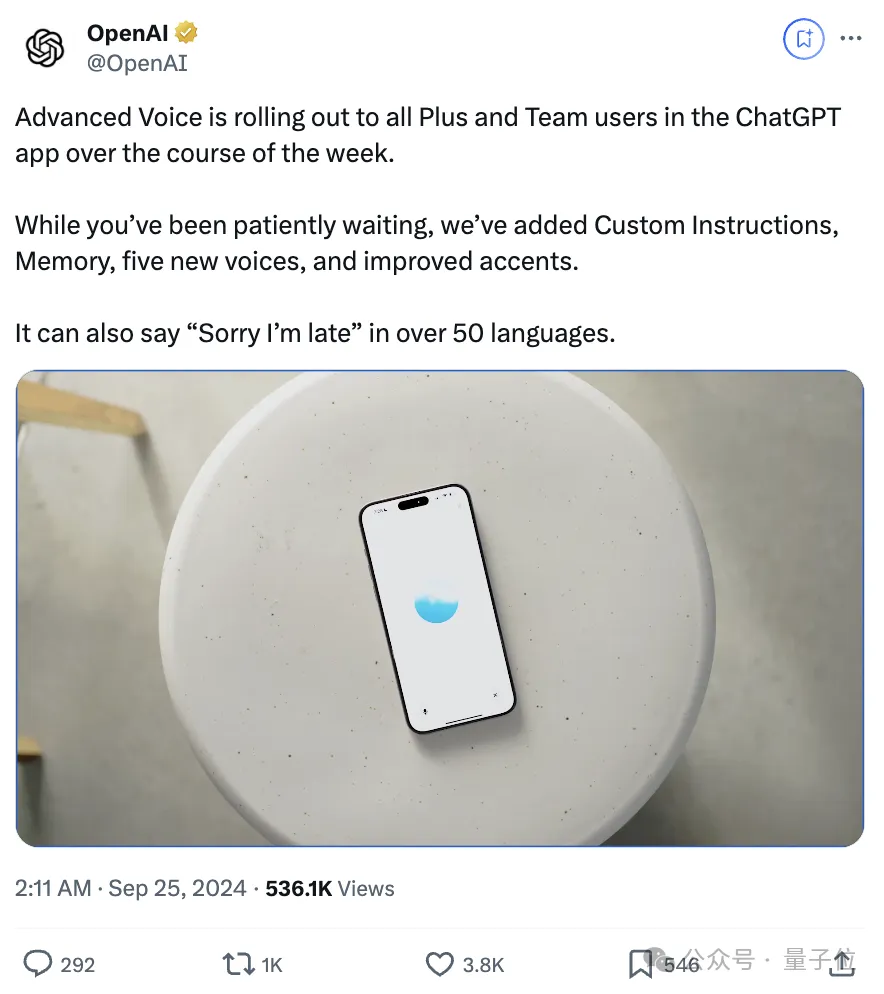
千呼万唤,GPT-4o高级语音终于开始全量推出,Plus用户一周内都能用了!

NVLM 1.0系列多模态大型语言模型在视觉语言任务上达到了与GPT-4o和其他开源模型相媲美的水平,其在纯文本性能甚至超过了LLM骨干模型,特别是在文本数学和编码基准测试中,平均准确率提高了4.3个百分点。
两个多月前那个对标GPT-4o的端到端语音模型,终于开源了。大神Karpathy体验之后表示:nice!

GPT-4o 读万卷书,「o1」行万里路。

AI玩黑神话,第一个精英怪牯护院轻松拿捏啊。

LLaMA-Omni能够接收语音指令,同步生成文本和语音响应,响应延迟低至 226ms,低于 GPT-4o 的平均音频响应延迟 320ms。
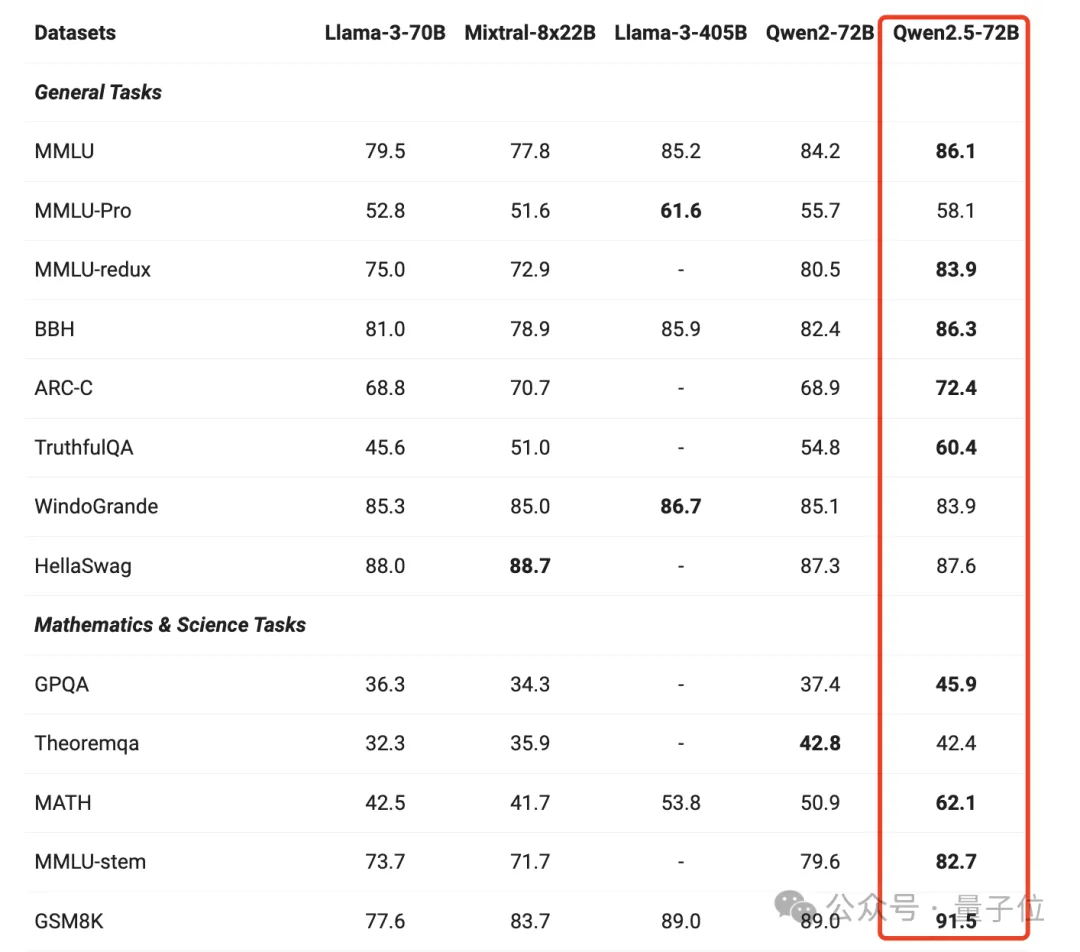
击败LIama3!Qwen2.5登上全球开源王座。 而后者仅以五分之一的参数规模,就在多任务中超越LIama3 405B。

MMMU-Pro通过三步构建过程(筛选问题、增加候选选项、引入纯视觉输入设置)更严格地评估模型的多模态理解能力;模型在新基准上的性能下降明显,表明MMMU-Pro能有效避免模型依赖捷径和猜测策略的情况。

鹅厂新一代旗舰大模型混元Turbo技术报告首次曝光。模型采用全新分层异构的MoE架构,总参数达万亿级别,性能仅次于GPT-4o,位列国内第一梯队。