
这些VLM竟都是盲人?GPT-4o、Sonnet-3.5相继败于「视力」测试
这些VLM竟都是盲人?GPT-4o、Sonnet-3.5相继败于「视力」测试四大 VLM,竟都在盲人摸象?
来自主题: AI技术研报
11005 点击 2024-07-11 20:26
 搜索
搜索
四大 VLM,竟都在盲人摸象?

Anthropic首席执行官表示,当前AI模型训练成本是10亿美元,未来三年,这个数字可能会上升到100亿美元甚至1000亿美元。要知道,GPT-4o这个曾经最大的模型也只用了1亿美元。千亿美刀,究竟花在了哪里?

GPT-4o的“AI视频通话”一鸽再鸽,但网友却是急不可耐想要体验。

基于 ChatGPT、LLAMA、Vicuna [1, 2, 3] 等大语言模型(Large Language Models,LLMs)的强大理解、生成和推理能力
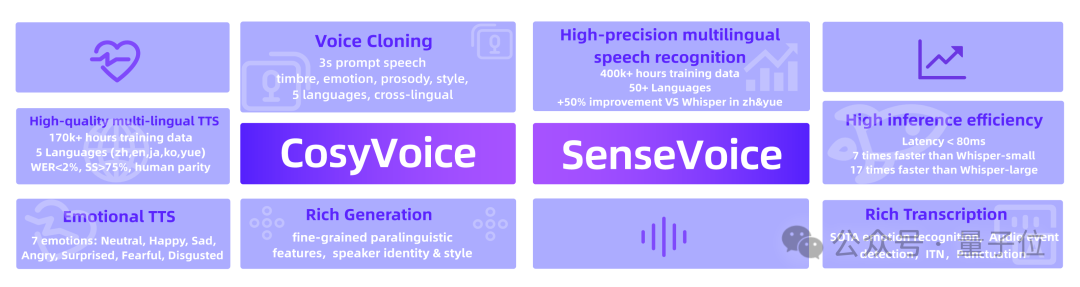
OpenAI迟迟不上线GPT-4o语音助手,其它音频生成大模型成果倒是一波接着一波发布,关键还是开源的。

没等到GPT-4o,商汤先把《Her》给发布出来了!
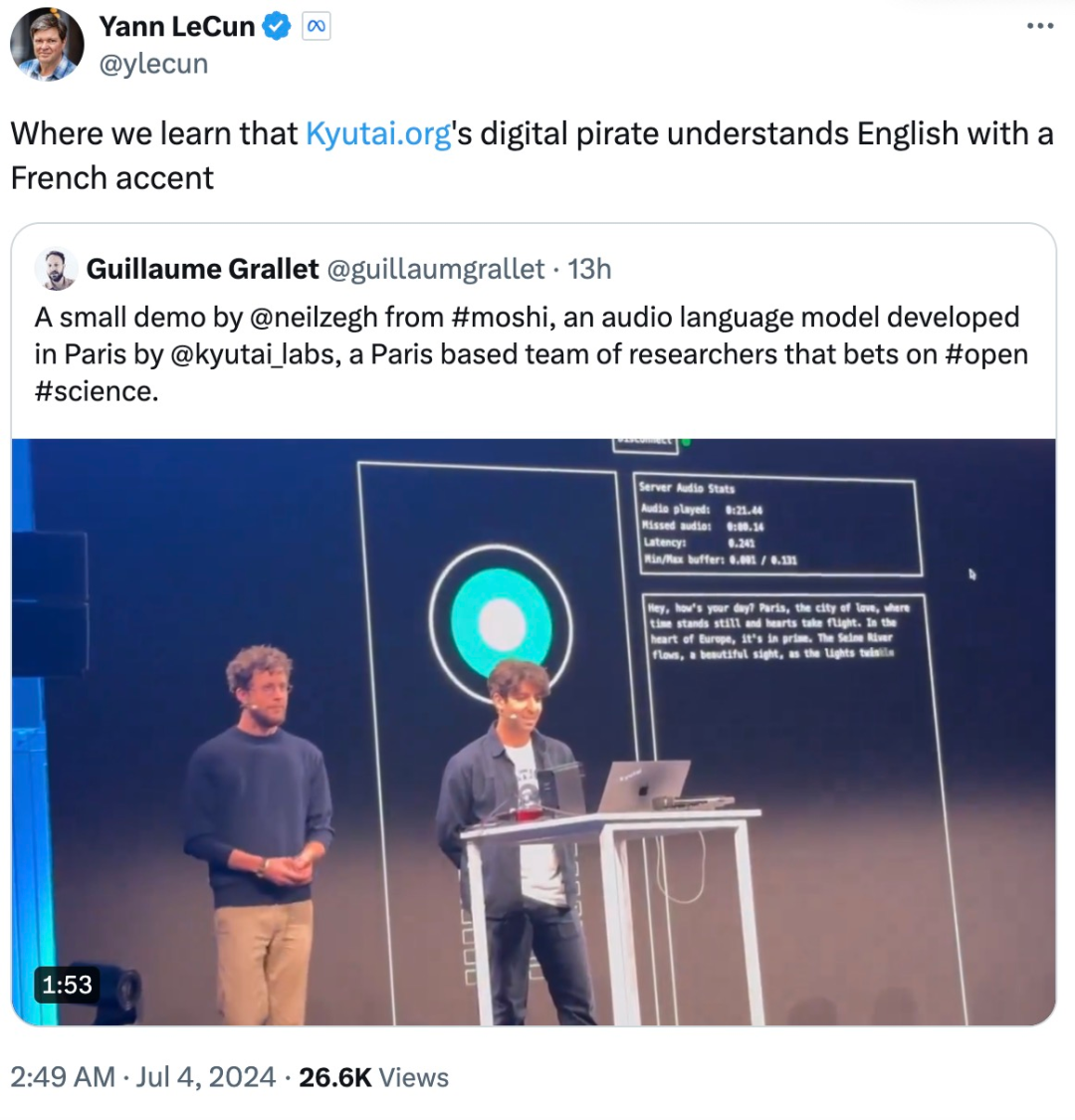
最近,一个对标 GPT-4o 的开源实时语音多模态模型火了。

“一天到晚就是跑分,刷榜,谁谁谁又超越GPT4了,OpenAI又出来sora了,又出来GPT-4o了等等。今天这个震撼发布,明天那个史诗级更新,但是我要问,应用在哪里?谁从中获益了?”

谷歌的Gemma 2刚刚发布,清华和北航的两名博士生就已经成功推出了指令微调版本,显著增强了Gemma 2 9B/27B模型的中文通用对话、角色扮演、数学、工具使用等能力。

Moshi 具有彻底改变人机通信的潜力。