
有了AI,终身教育真的有望了吗?
有了AI,终身教育真的有望了吗?5月中旬,OpenAI发布了全新的ChatGPT-4o,并邀请初代在线教育顶流可汗教育(Khan Academy)创始人Sal Khan出题、出提示词,让这款全新的4o来教他儿子做几何题。
来自主题: AI资讯
8339 点击 2024-06-24 15:39
 搜索
搜索
5月中旬,OpenAI发布了全新的ChatGPT-4o,并邀请初代在线教育顶流可汗教育(Khan Academy)创始人Sal Khan出题、出提示词,让这款全新的4o来教他儿子做几何题。

“从横向来看,我们显然仍与国际顶尖工作如Sora和GPT-4o有显著差距;同时,从纵向来看,我们已经从十几年的nobody,快速成长为人工智能科技创新的关键推动者。面向即将到来的AGI时代,我们应该更加自信积极地投身其中。”

OpenAI劲敌出手,追击GPT-4o。
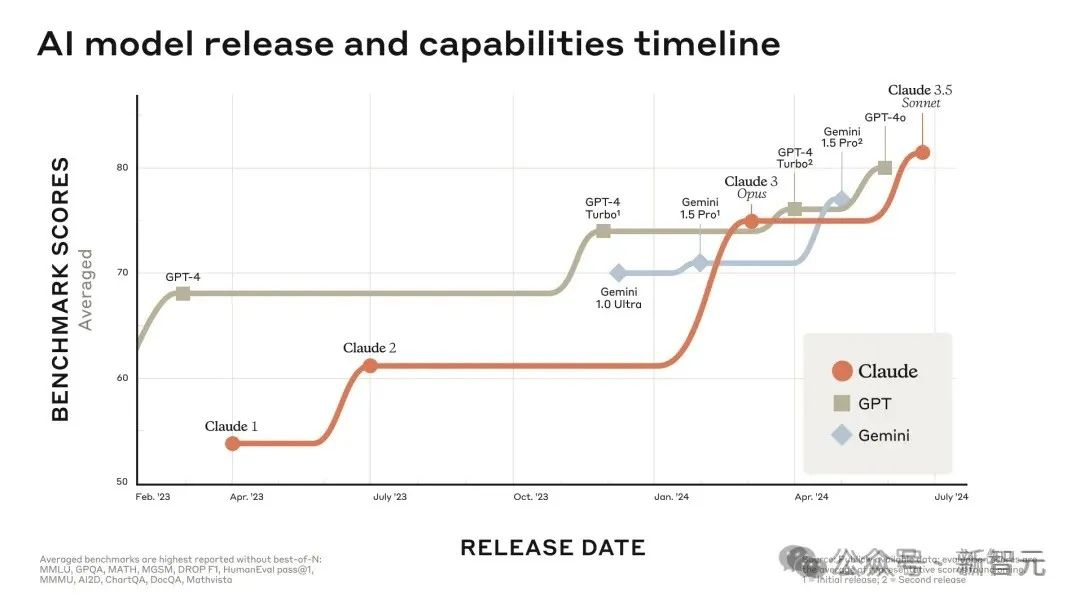
昨夜上线的Claude 3.5 Sonnet,性能直接吊打了GPT-4o,甚至价格还更便宜。网友们纷纷展开实测,有人表示自己一半的工作已经可以由它替代了!而最让人惊喜的新功能,莫过于Artifacts了。

难度大升级的多任务长视频理解评测基准MLVU来了!
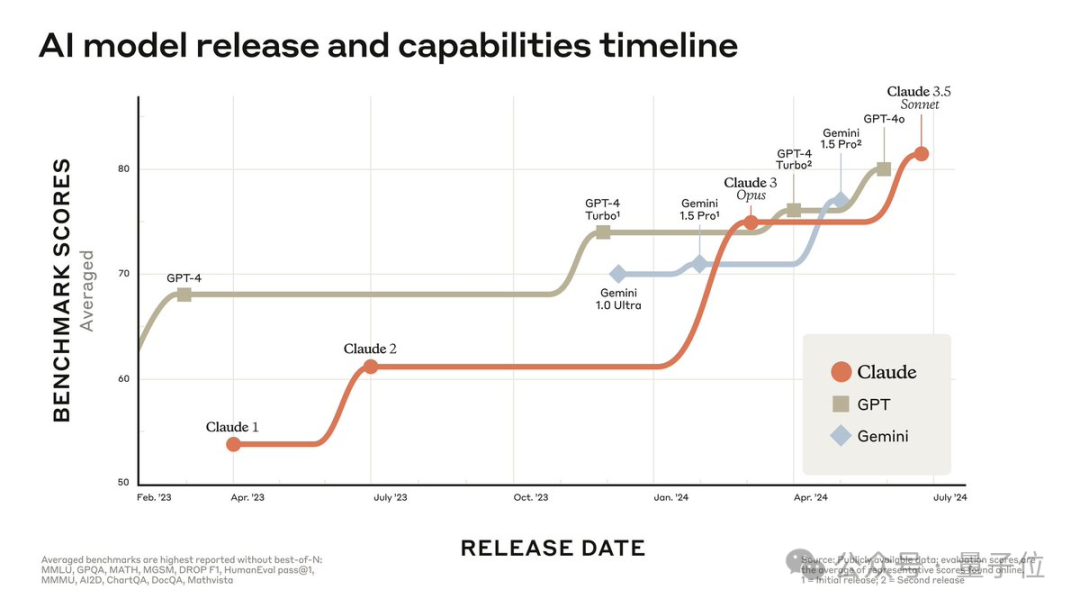
新鲜出炉的Claude 3.5 Sonnet,更快、更便宜,还是全球最强。
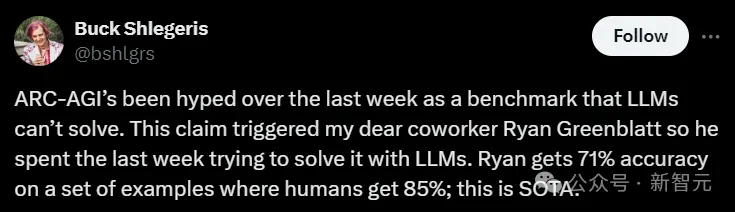
号称不可能轻易被击败的AGI基准ARC-AGI被GPT-4o撼动,GPT-4o以在公共测试集50%、在训练集71%的准确率成为了新的SOTA!

Claude大模型又双叒叕更新升级了!

今天, OpenAI劲敌Anthropic忽然丢炸弹,发布下一代旗舰大模型Claude 3.5 Sonnet。
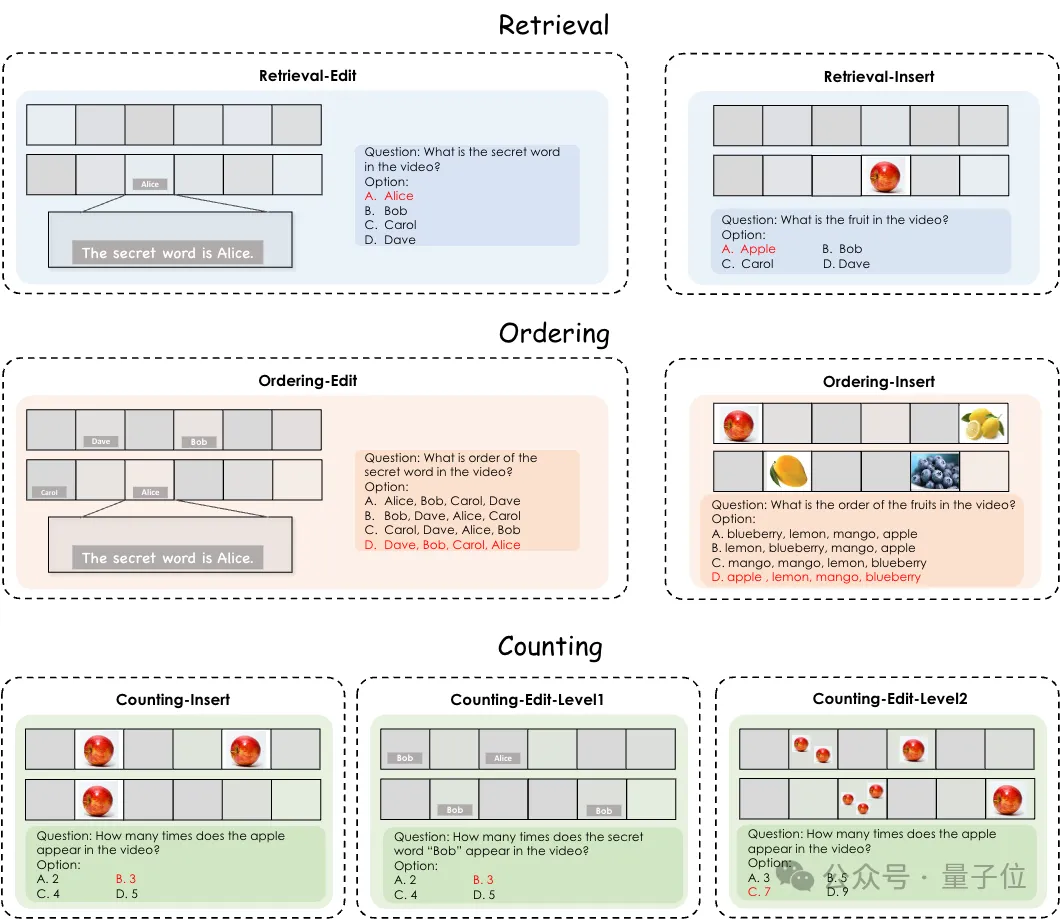
测试Gemini1.5 Pro、GPT-4o等多模态大模型的新基准来了,针对视频理解能力的那种。