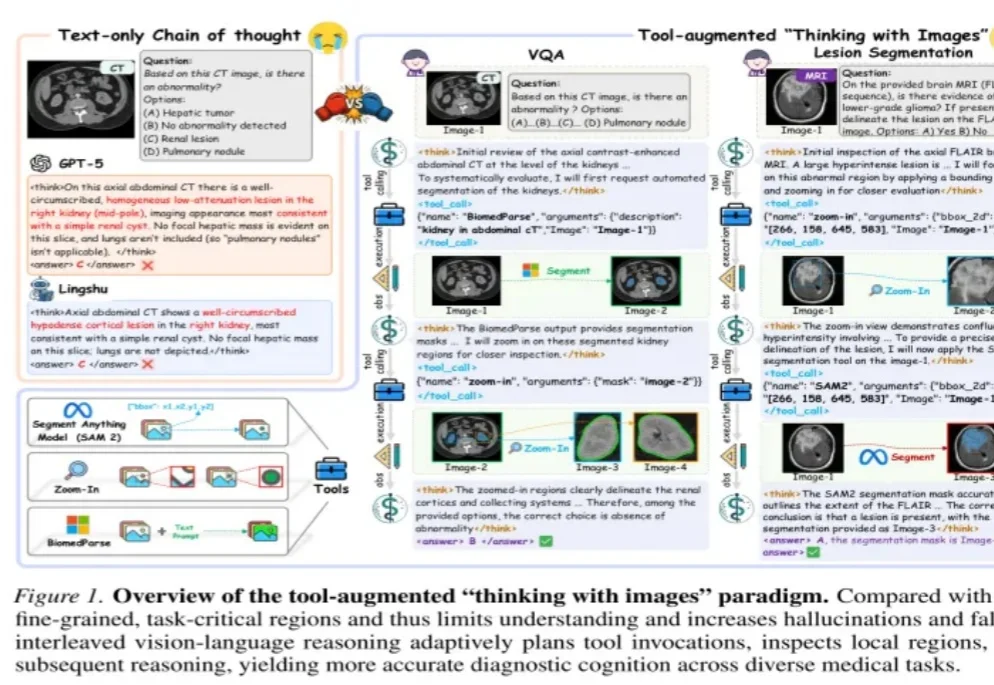
7B打败o3、GPT-5!医学AI智能体让模型学会“看哪里、怎么看”
7B打败o3、GPT-5!医学AI智能体让模型学会“看哪里、怎么看”医学AI会写解释,但不代表它真的“看到”了关键证据。
来自主题: AI技术研报
10202 点击 2026-05-28 14:51
 搜索
搜索
医学AI会写解释,但不代表它真的“看到”了关键证据。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

一个号称「零污染」的新基准 DeepSWE,用113道原创题撕开了旧编程榜单的遮羞布。

GPT-5.5被扒出「假思考」,用两小时就被偷偷换成mini,200美元月费买了个「薛定谔的脑子」。Trace命令实锤,官方文档亲自认领。往后有纷纷吐槽:OpenAI,你糊弄谁呢?
最近,GPT-5.6泄露了!150万Token+神级极简UI,下月紧急上线,奥特曼的「超级智能体」要掀翻整个硅谷?6月AI大战,已经提前爆发了。
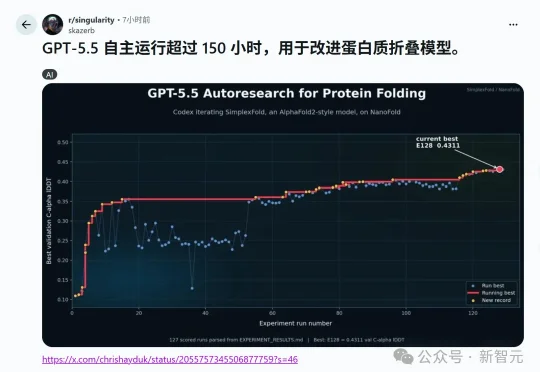
有人晒出开源项目:GPT-5.5连续狂飙150小时,自主挑战诺奖级AlphaFold2!它用拓扑「单纯形」重构蛋白质折叠逻辑,虽然性能暂未登顶,却展示了AI科学家的恐怖潜力:秒回滚、零情绪、全自动进化。科研范式,真要变天了。

Mechanize 发布了一项硬核测试:给前沿 AI coding agents 24 小时,用 Rust 从零写一个完整的 Game Boy Advance 模拟器,再和顶级开源模拟器 Mesen2 逐帧对比打分。
就在刚刚,被Anthropic视为「太危险」的绝密大模型Mythos,竟在谷歌云悄悄解禁。CMU最新实测爆出,它在真实漏洞攻防中,断层碾压GPT-5.5。
今天,蚂蚁百灵开源旗舰级思考模型Ring-2.6-1T,该模型于5月9日发布,引入了可调节的Reasoning Effort机制,支持high与xhigh两种推理强度,开发者可以根据任务特性动态分配推理资源。
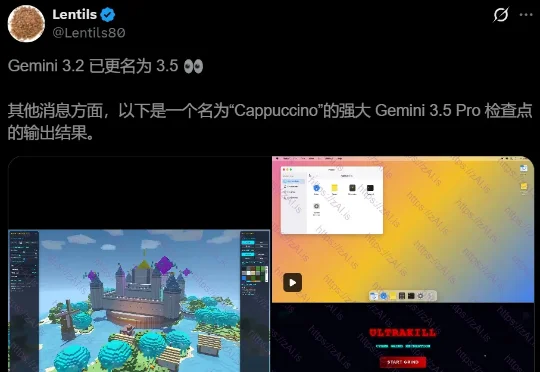
就在刚刚,Gemini 3.5提前曝光了! 网友Lentils放出最新消息,代号「Cappuccino」的Gemini 3.5 Pro检查点已经开始产出。而就在几个小时前,传闻还是Gemini 3.2,没想到一下子就替换成了Gemini 3.5。