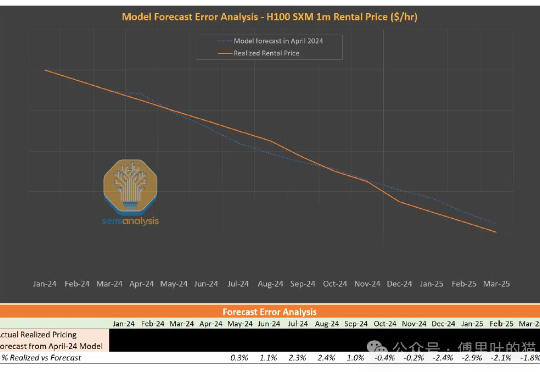
GPU租赁市场调研
GPU租赁市场调研前几天有朋友还在问我GPU租赁市场的情况,正好SemiAnalysis出了这篇文章:GPU云ClusterMA评级系统 | GPU租用指南。
来自主题: AI技术研报
8968 点击 2025-04-04 16:23
 搜索
搜索
前几天有朋友还在问我GPU租赁市场的情况,正好SemiAnalysis出了这篇文章:GPU云ClusterMA评级系统 | GPU租用指南。

通过完全启用并发多块执行,支持任意专家数量(MAX_EXPERT_NUMBER==256),并积极利用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE Align & Sort逻辑被精心设计,实现了显著的性能提升:A100提升3倍,H200提升3倍,MI100提升10倍,MI300X/MI300A提升7倍...

在算力投资激增的当下,GPU卡回收与维修行业逐渐成为一条隐秘的暴利赛道。特别是一些众所周知的原因,串串资源的货源和魔改卡的维保是重灾区! 现状:运营一年以上的算力中心运营商手里一定有坏掉的A100和H100服务得不到及时维修,放在那吃灰,无法对外出租算力产生收入。
「看到人们喜欢 ChatGPT 中的图片功能真是太有趣了,但是我们的 GPU 正在融化。」

蚂蚁开源大模型的低成本训练细节,疑似曝光!

有25万块GPU的CoreWeave,已提交上市文件,计划IPO。虽然有英伟达等支持,但CoreWeave估值350亿美元,并不被媒体看好。而科技媒体初创Edward Zitron,更是直言CoreWeave财务糟糕,就是定时炸弹,而GenAI炒作泡沫即将破裂!

老黄在GTC 2025大会上,再次亮出了英伟达未来GPU路线图。随着推理token的暴增,AI计算需要全新的范式,下一代BlackWell Ultra、Vera Rubin就是最强的回应。

皮衣老黄,带着最强AI芯片GB300闪亮登场“AI超级碗”GTC,燃爆全场!

超低成本图像生成预训练方案来了——仅需8张GPU训练,就能实现近SOTA的高质量图像生成效果。
第一家全面拥抱DeepSeek的“六小虎”,出现了! 不卖关子,它就是李开复亲任CEO的零一万物。 今日正式上线万智企业大模型一站式平台,宣布提供企业级DeepSeek部署定制解决方案。