
龙虾GPU来了!老黄杀入OpenClaw战场,全新Rubin算力狂飙35倍
龙虾GPU来了!老黄杀入OpenClaw战场,全新Rubin算力狂飙35倍太燃了!老黄GTC再次掏出核弹,新一代Vera Rubin炸场,七颗芯片首次合体,推理性能狂飙35倍。最重磅的是,英伟达版「龙虾」NemoClaw终于现身。
来自主题: AI资讯
10628 点击 2026-03-17 10:11
 搜索
搜索
太燃了!老黄GTC再次掏出核弹,新一代Vera Rubin炸场,七颗芯片首次合体,推理性能狂飙35倍。最重磅的是,英伟达版「龙虾」NemoClaw终于现身。

简单讲,Violoop 是一款巴掌大小的硬件,有一块触屏屏幕,用来显示它当前正在处理的任务。这是一款即插即用的产品,不挤占电脑的 CPU/GPU资源,无需安装任何软件,一台普通电脑通过一根 HDMI 线连上 Violoop,就能秒变「AI 电脑」,成为升级版「龙虾」。
让OpenClaw帮干活还不够,现在,程序员们正想方设法让🦞自己变强。

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!
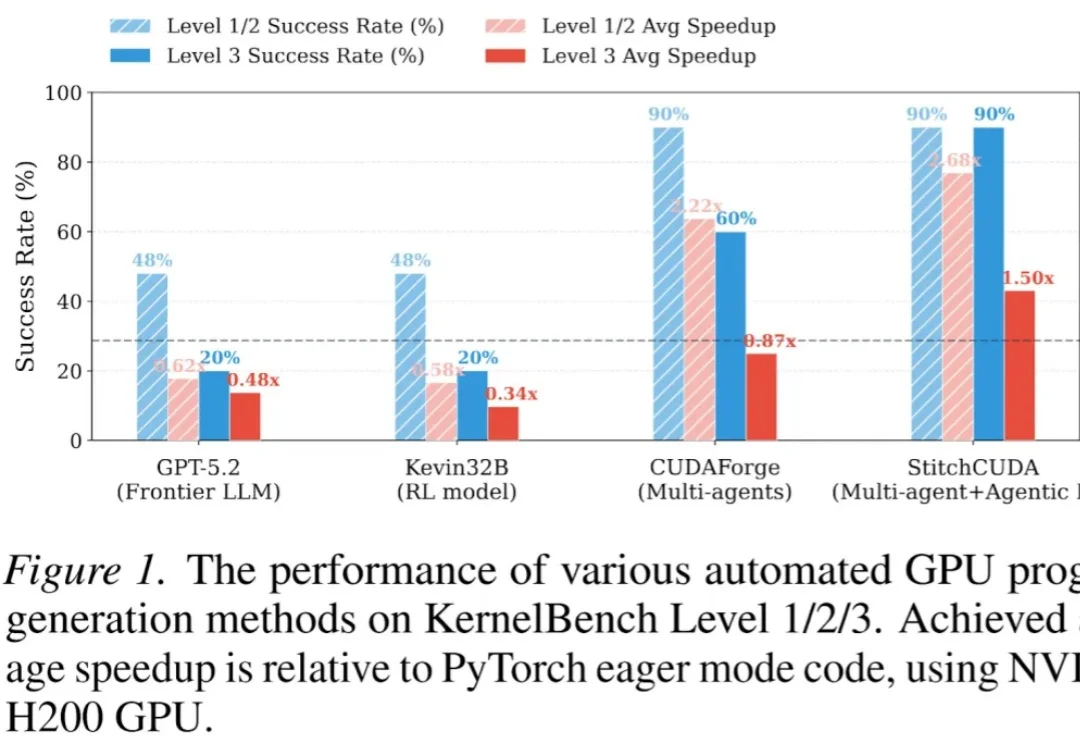
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。

让AI自己写高性能GPU代码,字节Seed与清华AIR团队做到了。

据悉,在即将开幕的3月圣何塞GTC大会上,黄仁勋将发布一套全新的AI推理系统—— 核心是一颗专为推理优化的新芯片。而且芯片的首位大客户已经敲定,就是刚刚完成1100亿美元巨额融资的OpenAI。
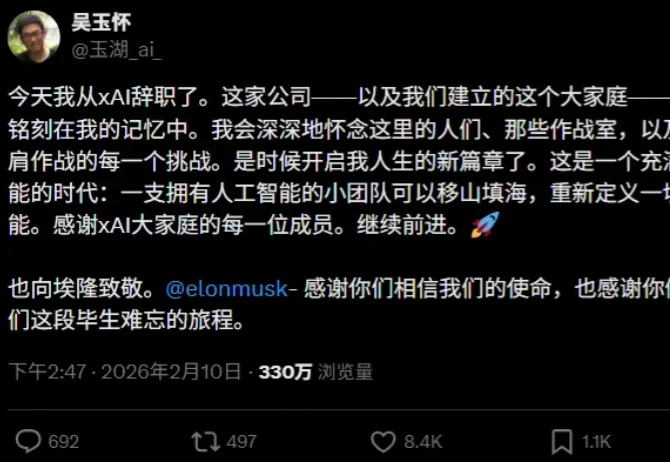
当地时间 2 月 10 日和 11 日,xAI 的联合创始人 Tony Wu 和 Jimmy Ba 先后在社交平台 X 上宣布离职,这是继 Igor Babuschkin、Christian Szegedy 等人之后,xAI 创始团队在不到三年内的又一次核心人员变动。截至目前,xAI 最初 12 人的创始团队中已有六位成员离开。

首个统一系统:将物理机器人提升为与 GPU 同等的计算资源,打破硬件隔阂。

对于国产 GPU 行业来说,没有哪个时间节点比当下更宝贵。在政策支持硬科技企业上市的背景下,国产 GPU 迎来了难得的上市黄金窗口期。但上市并非终点,在敲钟的那一刻,下一战场大幕已经拉开——GPU 厂商的技术路线、产品能力和长期判断,被放到了更公开也更严苛的舞台上,谁能撑起资本市场和大众期待,谁就能撑起市值。