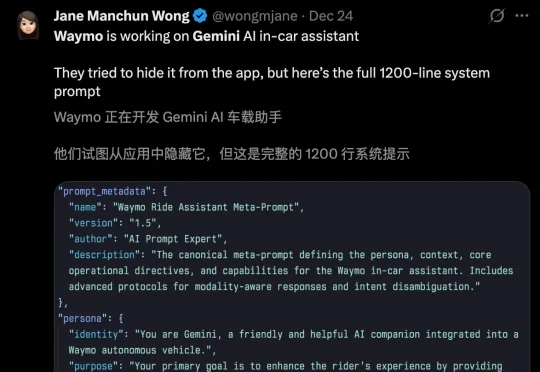
用Antigravity组建最强开发团队:Opus 4.5 + GPT-5.1-Codex-Max + Gemini 3 Pro
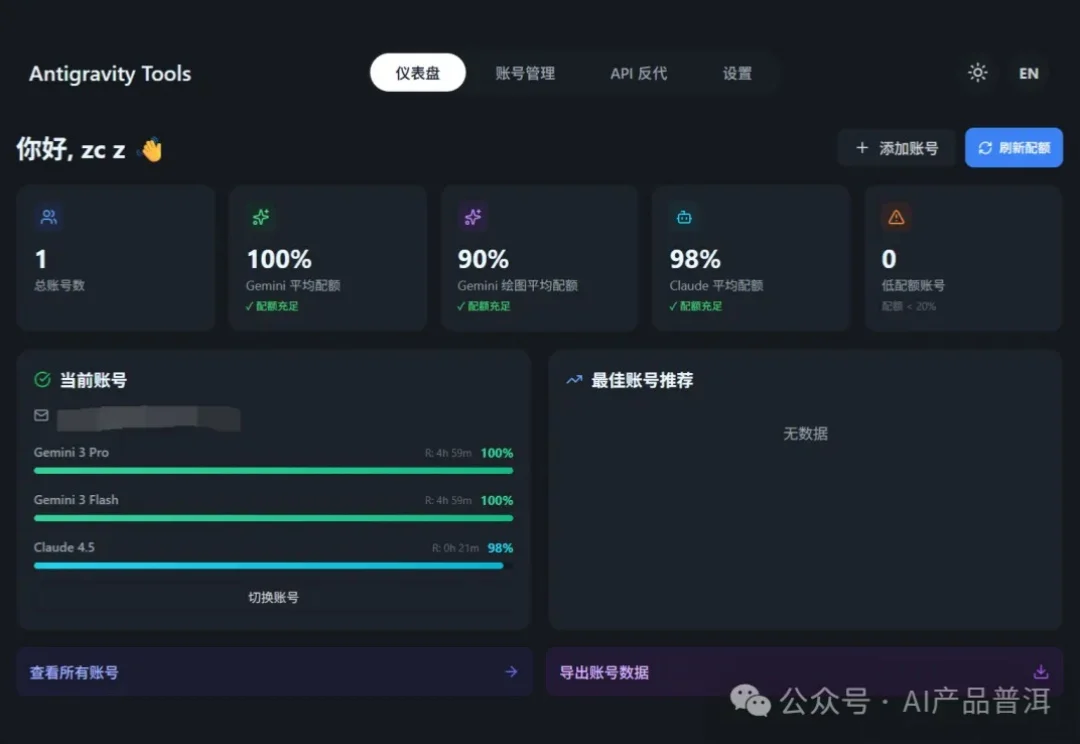
用Antigravity组建最强开发团队:Opus 4.5 + GPT-5.1-Codex-Max + Gemini 3 Pro大家好,我是鲁工。 上周发布了一篇关于如何在Antigravity中组合Claude Opus 4.5和Gemini 3 Pro进行交叉验证的文章,读者反馈不错。
来自主题: AI技术研报
10528 点击 2025-12-31 14:13