GPU挤爆了!Kimi K3暂停新用户订阅,月之暗面准备IPO
GPU挤爆了!Kimi K3暂停新用户订阅,月之暗面准备IPO不久前,Kimi 官方宣布,将暂停新会员订阅。月之暗面表示,公司正在增加算力,并将在容量允许后分批重新开放订阅。不过,官方目前尚未公布具体扩容规模,也没有说明新增订阅何时恢复。
来自主题: AI资讯
9725 点击 2026-07-20 17:11
 搜索
搜索
不久前,Kimi 官方宣布,将暂停新会员订阅。月之暗面表示,公司正在增加算力,并将在容量允许后分批重新开放订阅。不过,官方目前尚未公布具体扩容规模,也没有说明新增订阅何时恢复。

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个

发布之前,我在 X 上看到有人说,测 K3 的感觉就像在测 Fable 5。虽然离 Fable 5 还差一点点 🤏,但超过 Opus 4.8 和 GPT 5.5 基本没有问题。在前端能力,K3 的提升非常明显,我已经用它复刻了前段时间爆火的独立工作室 Abeto 推出的一款 3D 网页游戏 《 Messenger》(ps. 音乐手动配的,主角模型是 K3 自己判断、自主去游戏官网找的)

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。
外媒Axios称,K3定价远低于它所挑战的高端模型,美国AI公司的高价策略还能维持多久?巧的是,就在最近,两大巨头正在打客户争夺战。此前,特曼在X上发帖,不提新模型,开头就是一句认错:
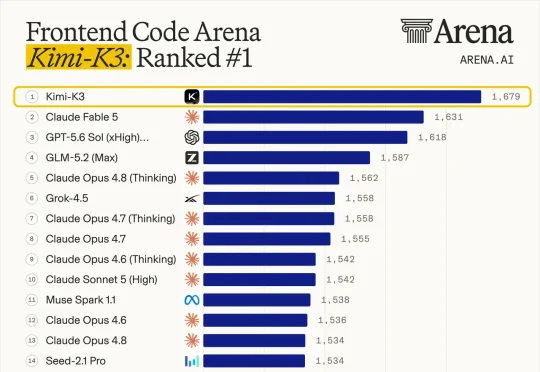
今天凌晨看到 Arena AI 更新 Code Arena 榜单时,我第一反应是有点意外。刚刚发布的 Kimi K3 拿到了 1679 分,排在全球第一,压过了 Claude Fable 5 的 1631 分和 GPT-5.6 Sol 的 1618 分。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。
这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。

当 Agent 走向生产,云与数据库需要被一起重新考虑。

葬AI身边的朋友常常有个疑问:为什么MiniMax M3做的不够好(问了很多在做模型测评的朋友,也是类似看法),但市场仍然觉得他们是第一梯队?我朋友@朱亦辉的解释是,MiniMax M3的核心科技是叙事能力,让外界觉得他们和Kimi是一个级别,达到一个强行双骄的效果。