
Llama 4万亿巨兽延期,80%核心元老集体辞职?
Llama 4万亿巨兽延期,80%核心元老集体辞职?2万亿Llama4巨兽一再推迟,又传出了80%团队辞职的惊人消息!目前,发言人已辟谣消息不准确,Meta或许迎来了至暗时刻。
来自主题: AI资讯
8841 点击 2025-05-19 09:34
 搜索
搜索
2万亿Llama4巨兽一再推迟,又传出了80%团队辞职的惊人消息!目前,发言人已辟谣消息不准确,Meta或许迎来了至暗时刻。
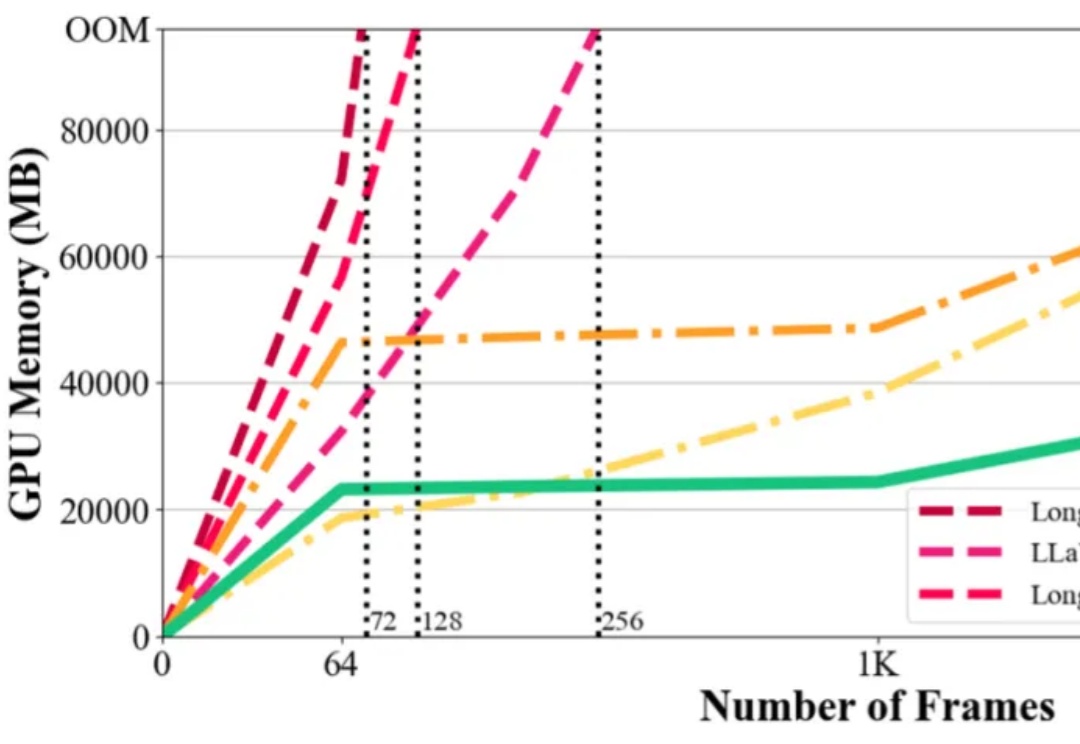
在视觉语言模型(Vision-Language Models,VLMs)取得突破性进展的当下,长视频理解的挑战显得愈发重要。以标准 24 帧率的标清视频为例,仅需数分钟即可产生逾百万的视觉 token,这已远超主流大语言模型 4K-128K 的上下文处理极限。

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!
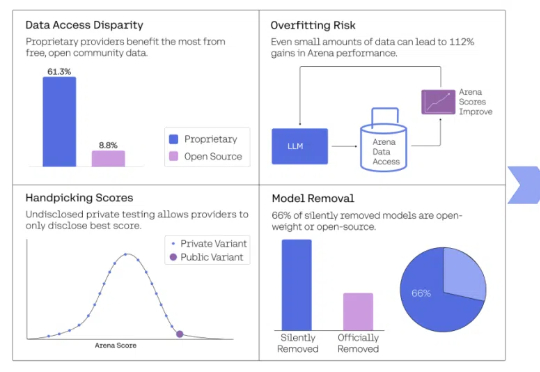
大模型竞技场的可信度,再次被锤。

来自英伟达和UIUC的华人团队提出一种高效训练方法,将LLM上下文长度从128K扩展至惊人的400万token SOTA纪录!基于Llama3.1-Instruct打造的UltraLong-8B模型,不仅在长上下文基准测试中表现卓越,还在标准任务中保持顶尖竞争力。

Meta首届LlamaCon开发者大会开幕,扎克伯格在期间接受采访,回应大模型相关的一切。包括Llama4在大模型竞技场表现不佳的问题:
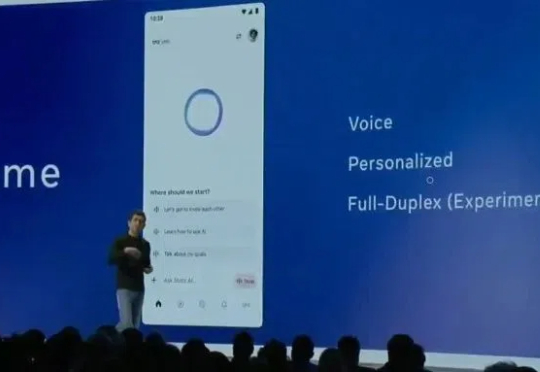
今天,在首届LlamaCon开发者大会上,Meta正式发布了对标ChatGPT的智能助手Meta AI App,并宣布面向开发者提供官方Llama API服务的预览版本。Meta AI App是一款智能助手,基于Llama模型打造,可通过社交媒体账号了解用户偏好、记住上下文。与ChatGPT一样,Meta AI App支持语音和文本交互,并额外支持了全双工语音交互(Full-duplex,

香港英文媒体《南华早报》29日援引两名知情人士的话报道称,微软研究院纽约实验室的高级研究员兰姆(Alex Lamb)将于即将到来的秋季学期加入新成立的清华大学人工智能学院(College of AI),担任助理教授。兰姆在一封电子邮件中证实了这一消息。
在DeepSeek R1-V3、GPT-4o、Claude-3.7的强势围攻下,Meta坐不住了。曾作为开源之光的Llama在一年的竞争内连连失利,并没有研发出让公众惊艳的功能。创始人扎克伯格下达死命令,今年4月一定要更新。

「一位顶尖科学家,有数千亿美元的资源,却仍然能把Meta搞砸了!」最近,圈内对LeCun的埋怨和批评,似乎越来越压不住了。有人批评说,Meta之所以溃败,LeCun的教条主义就是罪魁祸首。但LeCun却表示,自己尝试了20年自回归预测,彻底失败了,所以如今才给LLM判死刑!