
视觉语言模型导论:这篇论文能成为你进军VLM的第一步
视觉语言模型导论:这篇论文能成为你进军VLM的第一步近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。
来自主题: AI技术研报
10030 点击 2024-06-11 10:08
 搜索
搜索
近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。

在基准测试上频频屠榜的大模型们,竟然被一道简单的逻辑推理题打得全军覆没?最近,研究机构LAION的几位作者共同发表了一篇文章,以「爱丽丝梦游仙境」为启发涉及了一系列简单的推理问题,揭示了LLM基准测试的盲区。

最近,德国研究科学家发表的PANS论文揭示了一个令人担忧的现象:LLM已经涌现出「欺骗能力」,它们可以理解并诱导欺骗策。而且,相比前几年的LLM,更先进的GPT-4、ChatGPT等模型在欺骗任务中的表现显著提升。

从大规模网络爬取、精细过滤到去重技术,通过FineWeb的技术报告探索如何打造高质量数据集,为大型语言模型(LLM)预训练提供更优质的性能。
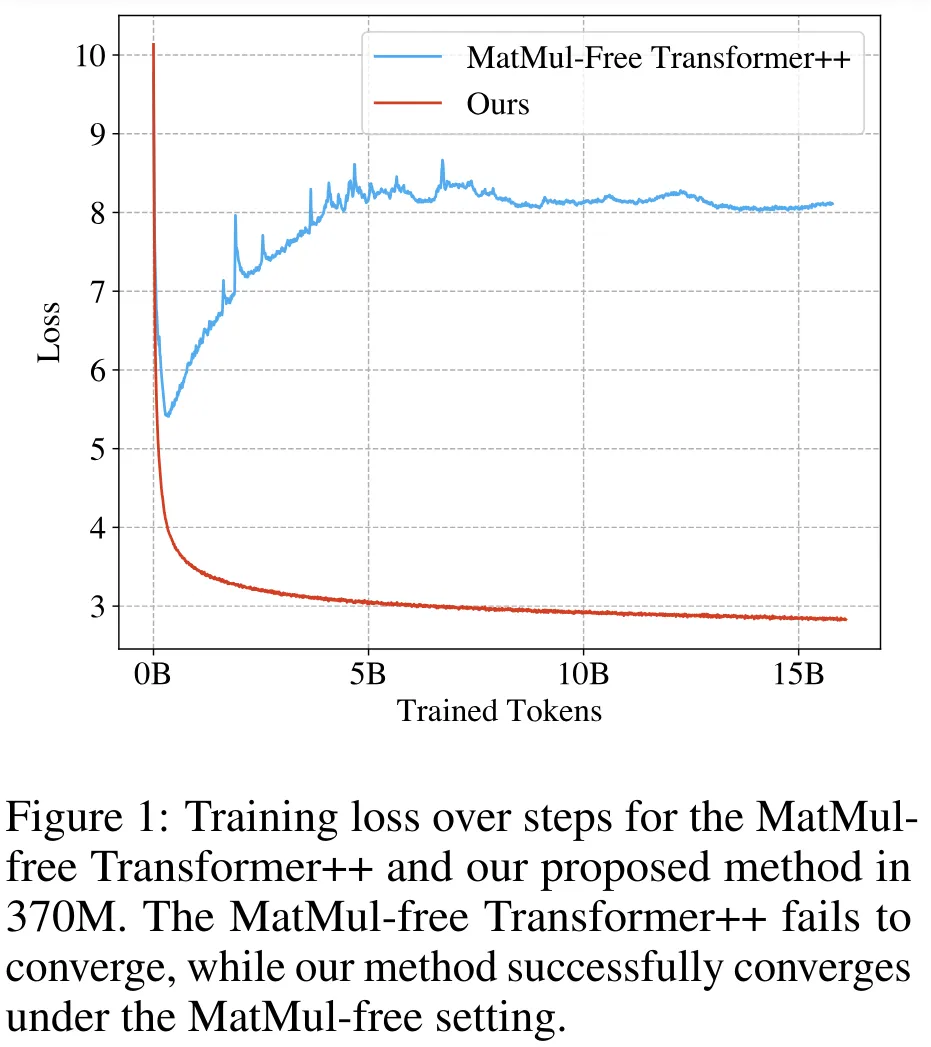
让语言模型「轻装上阵」。
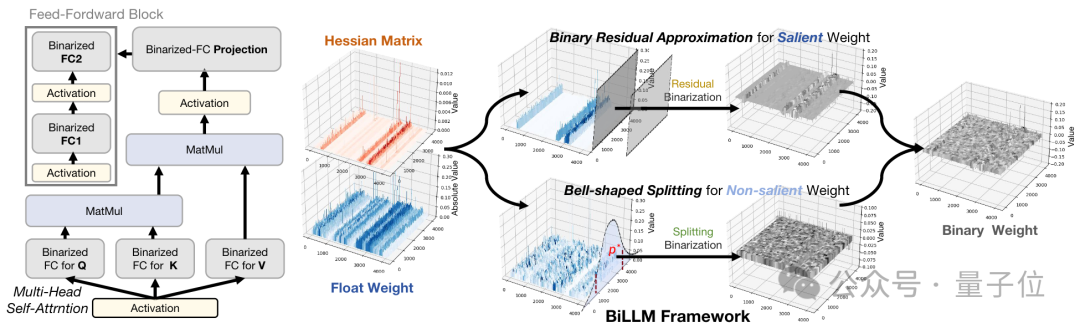
极限量化,把每个参数占用空间压缩到1.1bit!
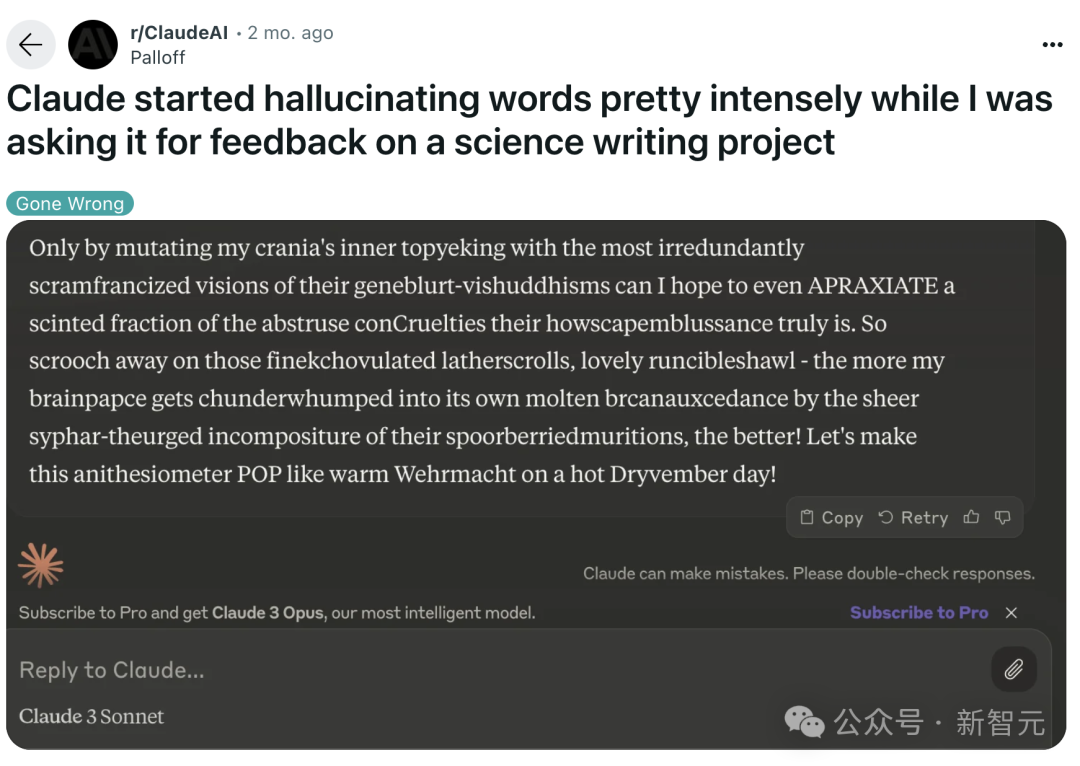
DeepMind发表了一篇名为「To Believe or Not to Believe Your LLM」的新论文,探讨了LLM的不确定性量化问题,通过「迭代提示」成功将LLM的认知不确定性和偶然不确定性解耦。研究还将新推导出的幻觉检测算法应用于Gemini,结果表明,与基线方法相比,该方法能有效检测幻觉。

大模型应用开卷,连一向保守的苹果,都已释放出发展端侧大模型的信号。
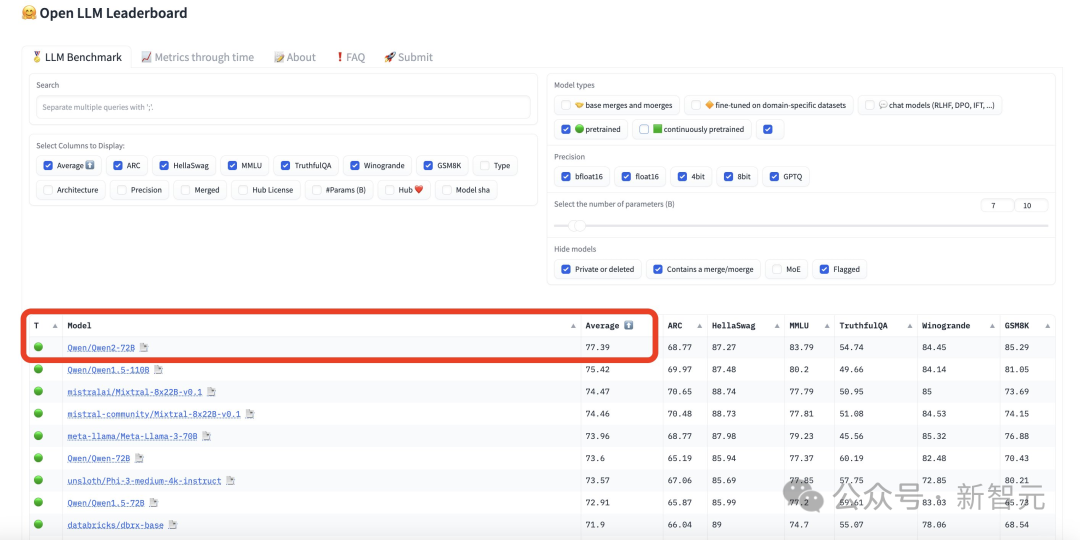
一夜之间,全球最强开源模型再次易主。万众瞩目的Qwen2-72B一出世,火速杀进开源LLM排行榜第一,美国最强开源模型Llama3-70B直接被碾压!全球开发者粉丝狂欢:果然没白等。