
大模型价格战:大厂烧钱狂飙,小厂如何抉择
大模型价格战:大厂烧钱狂飙,小厂如何抉择经济观察报注意到,目前降低的只是调用大模型应用程序编程接口(API)的费用。与这一费用相比,客户使用云服务后,付费环节更多、付费额度更高。
来自主题: AI资讯
7979 点击 2024-05-27 22:29
 搜索
搜索
经济观察报注意到,目前降低的只是调用大模型应用程序编程接口(API)的费用。与这一费用相比,客户使用云服务后,付费环节更多、付费额度更高。

当前,多模态大模型 (MLLM)在多项视觉任务上展现出了强大的认知理解能力。 然而大部分多模态大模型局限于单向的图像理解,难以将理解的内容映射回图像上。 比如,模型能轻易说出图中有哪些物体,但无法将物体在图中准确标识出来。 定位能力的缺失直接限制了多模态大模型在图像编辑,自动驾驶,机器人控制等下游领域的应用。针对这一问题,港大和字节跳动商业化团队的研究人员提出了一种新范式Groma

Jason Wei 是思维链提出者,并和 Yi Tay、Jeff Dean 等人合著了关于大模型涌现能力的论文。目前他正在 OpenAI 进行工作。
ChemLLM系列模型是由上海人工智能实验室开发的首个兼备推理、对话等通用能力和化学专业能力的开源大模型。相比于现有的其他大模型,ChemLLM对化学空间进行了有效建模,在产物预测、名称转化和化学性质预测等核心化学任务上表现优异。ChemLLM系列模型已经发布到了始智AI wisemodel.cn开源社区,并且无需任何代码,两步即可完成模型的在线体验。

科学家们把Transformer模型应用到蛋白质序列数据中,试图在蛋白质组学领域复制LLM的成功。本篇文章能够带你了解蛋白质语言模型(pLM)的起源、发展,以及那些尚待解决的问题。

本文介绍了香港科技大学(广州)的一篇关于大模型高效微调(LLM PEFT Fine-tuning)的文章「Parameter-Efficient Fine-Tuning with Discrete Fourier Transform」

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
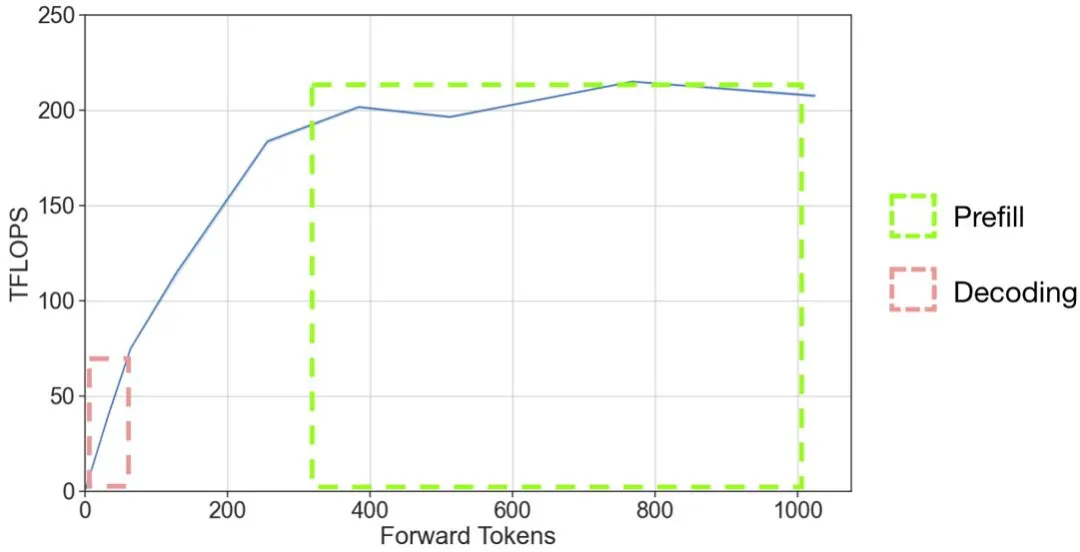
以 OpenAI 的 GPT 系列模型为代表的大语言模型(LLM)掀起了新一轮 AI 应用浪潮,但是 LLM 推理的高昂成本一直困扰着业务团队。
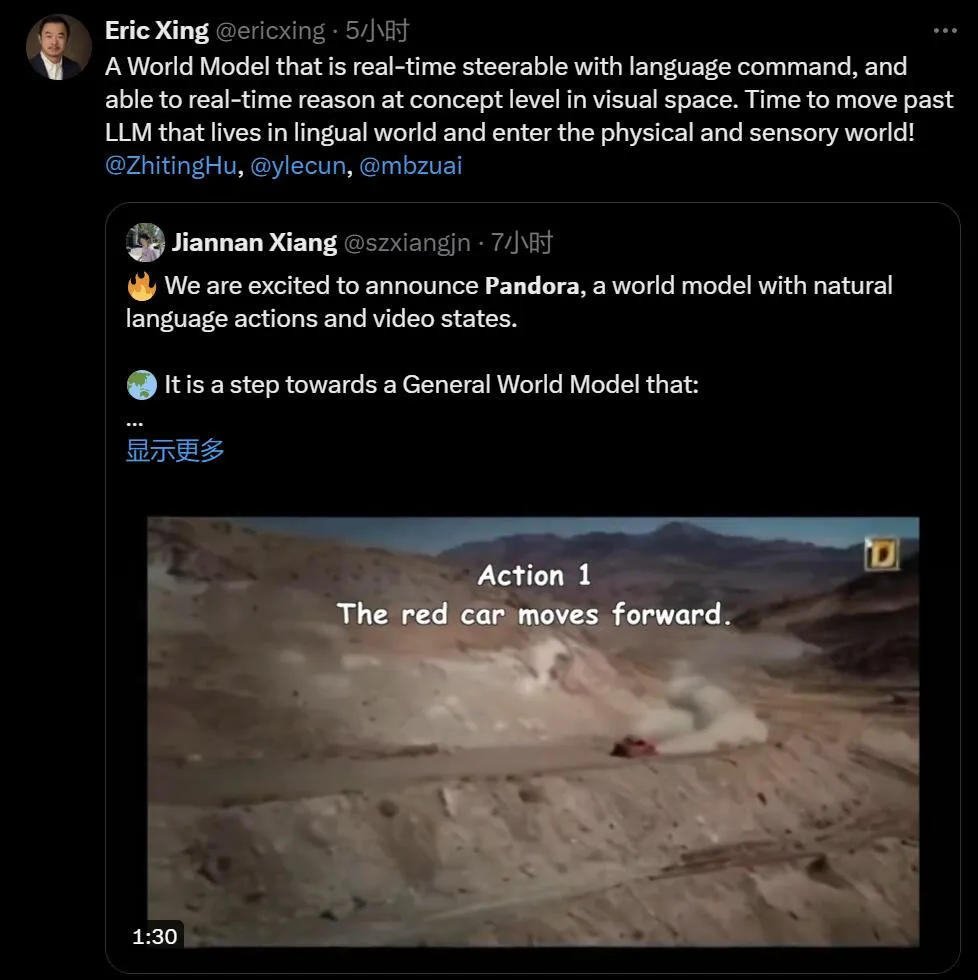
这才是 AI 视频生成的未来?

归根结底,大模型的方向还是走错了?