首个真正“能用”的LLM游戏Agent诞生!可实时高频决策,思维链还全程可见
首个真正“能用”的LLM游戏Agent诞生!可实时高频决策,思维链还全程可见不讲武德!游戏圈这回真是被AI抄家了。(doge)
来自主题: AI技术研报
10272 点击 2026-01-21 10:41
 搜索
搜索
不讲武德!游戏圈这回真是被AI抄家了。(doge)
2025 年 1 月 20 日,DeepSeek(深度求索)正式发布了 DeepSeek-R1 模型,并由此开启了新的开源 LLM 时代。在 Hugging Face 刚刚发布的《「DeepSeek 时刻」一周年记》博客中,DeepSeek-R1 也是该平台上获赞最多的模型。

最新综述首次系统探讨LLM控制机器人的安全威胁、防御机制与未来挑战,指出LLM的具身鸿沟导致其在物理空间可能执行危险动作,而现有防御体系存在逻辑与物理脱节等问题。
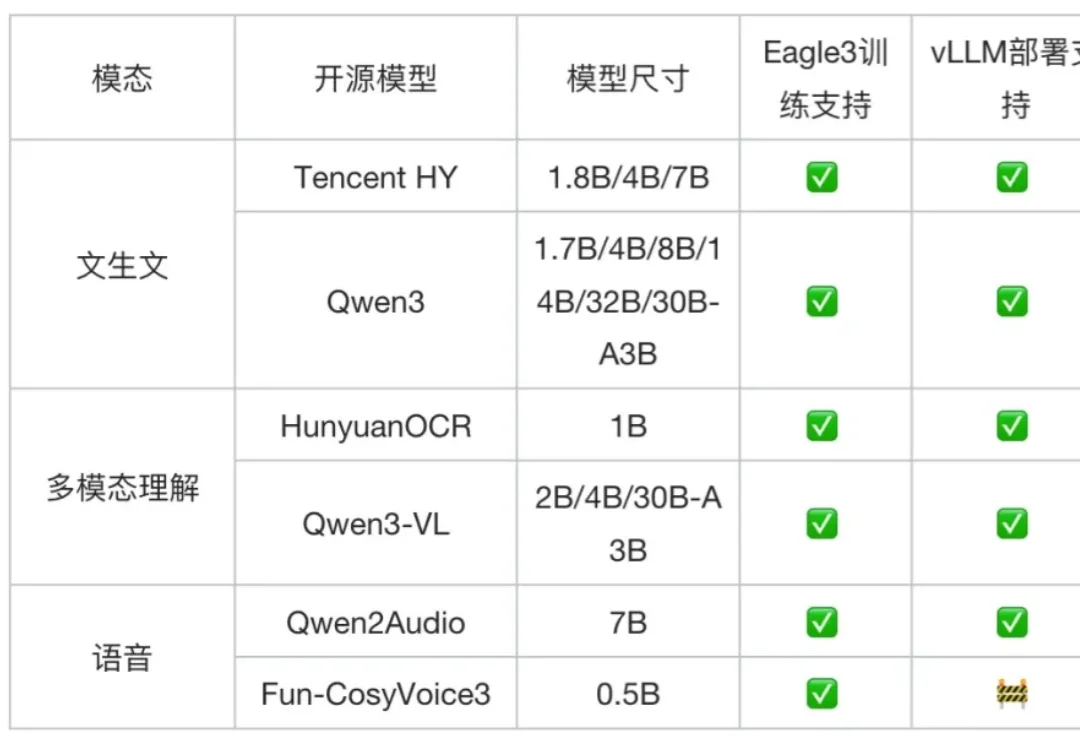
随着大模型步入规模化应用深水区,日益高昂的推理成本与延迟已成为掣肘产业落地的核心瓶颈。在 “降本增效” 的行业共识下,从量化、剪枝到模型蒸馏,各类压缩技术竞相涌现,但往往难以兼顾性能损耗与通用性。

简单到难以置信!近日,Google Research一项新研究发现:想让大模型在不启用推理设置时更准确,只需要把问题复制粘贴再说一遍,就能把准确率从21.33%提升到97.33%!
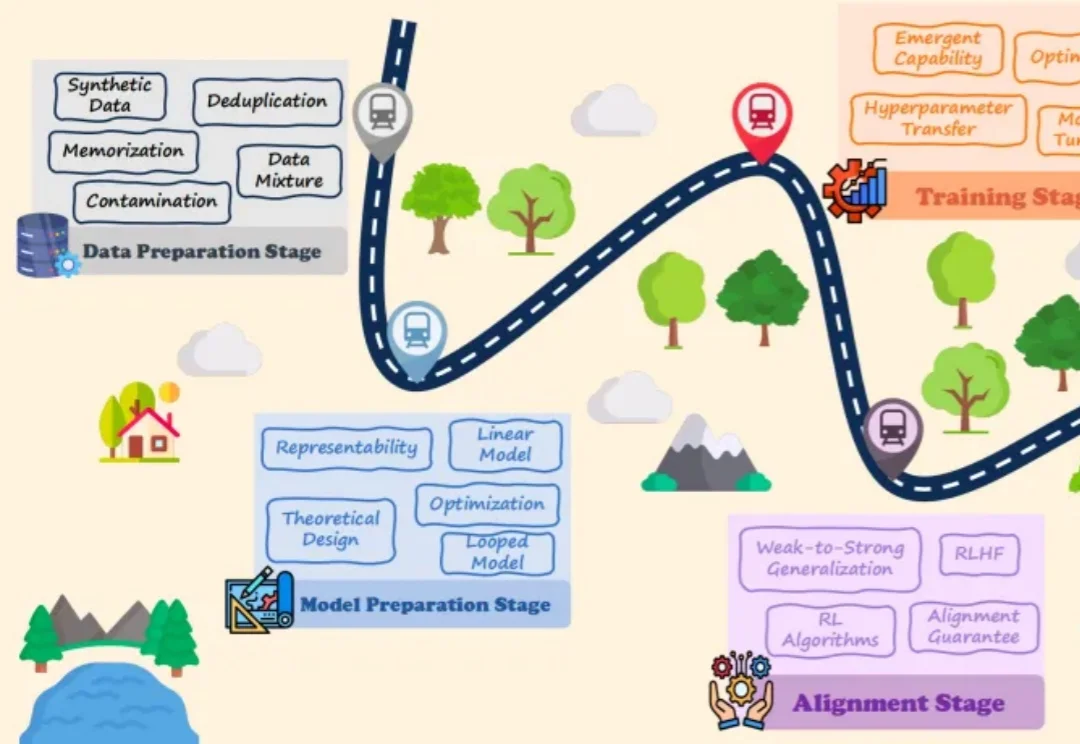
大语言模型(LLMs)的爆发式增长引领了人工智能领域的范式转移,取得了巨大的工程成功。然而,一个关键的悖论依然存在:尽管 LLMs 在实践中表现卓越,但其理论研究仍处于起步阶段,导致这些系统在很大程度上被视为难以捉摸的「黑盒」。

最近,一篇由中国团队领衔全球24所TOP高校机构发布,用于评测LLMs for Science能力高低的论文,在外网炸了!当晚,Keras (最高效易用的深度学习框架之一)缔造者François Chollet转发论文链接,并喊出:「我们迫切需要新思路来推动人工智能走向科学创新。」
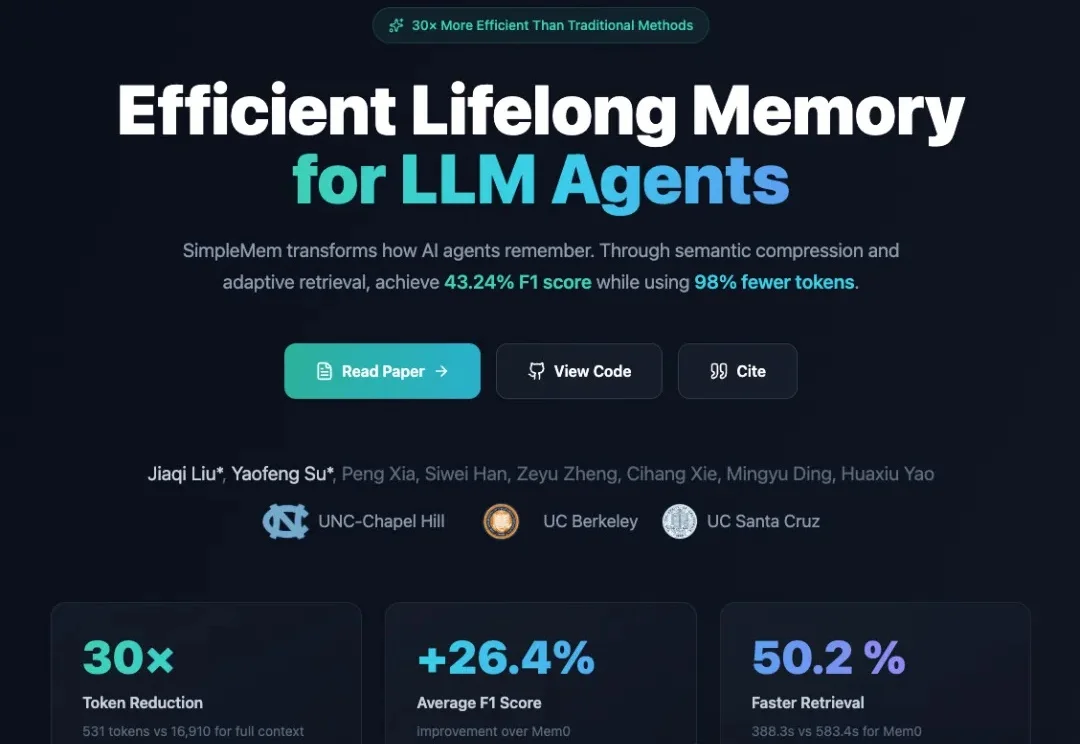
如果人类的大脑像现在的LLM Agent一样工作,记住每一句今天明天的废话,我们在五岁时就会因为内存溢出而宕机。真正的智能,核心不在于“存储”,而在于高效的“遗忘”与“重组”。
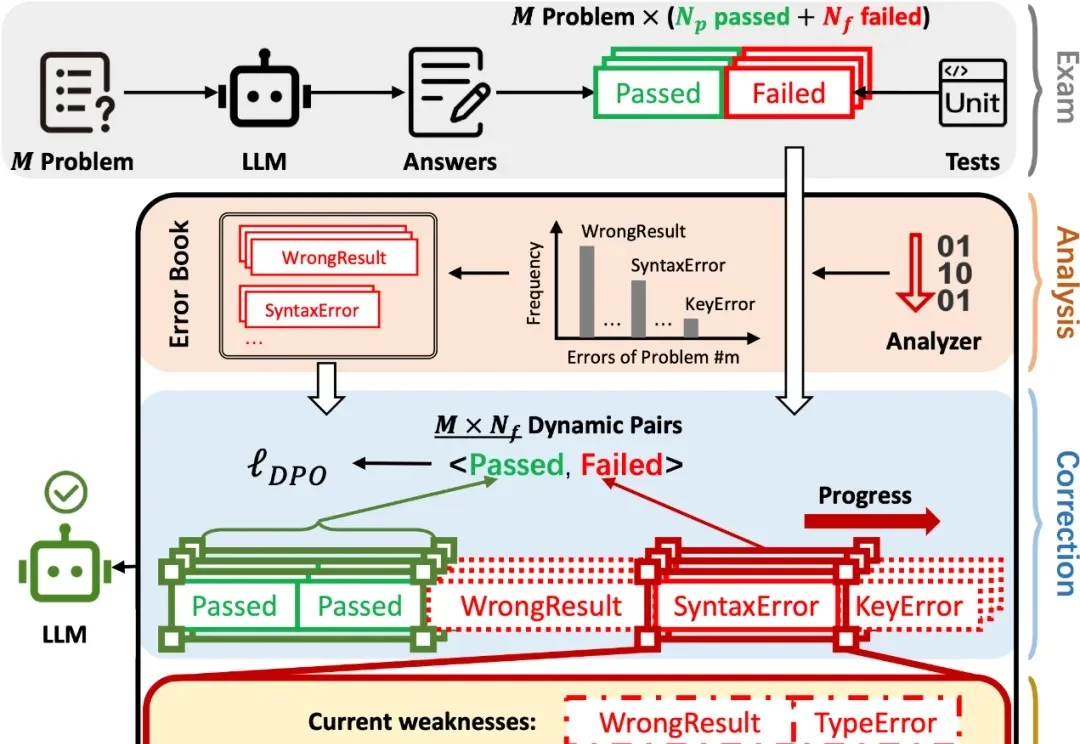
在 AI 辅助 Coding 技术快速发展的背景下,大语言模型(LLMs)虽显著提升了软件开发效率,但开源的 LLMs 生成的代码依旧存在运行时错误,增加了开发者调试成本。
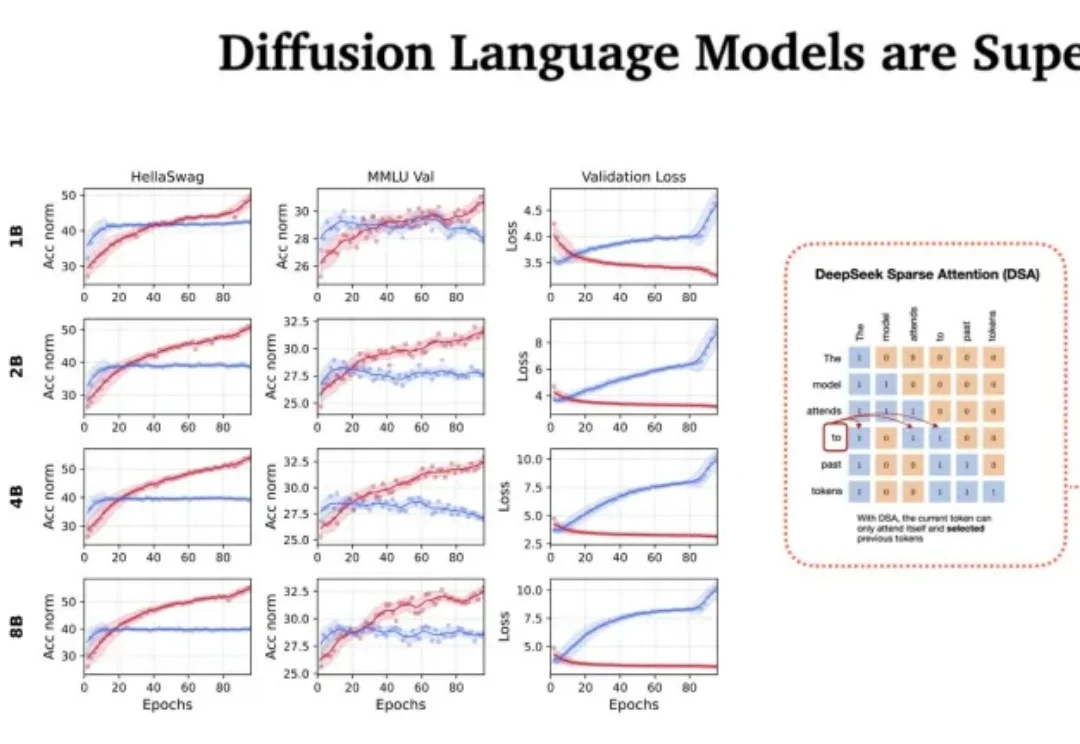
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。