谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
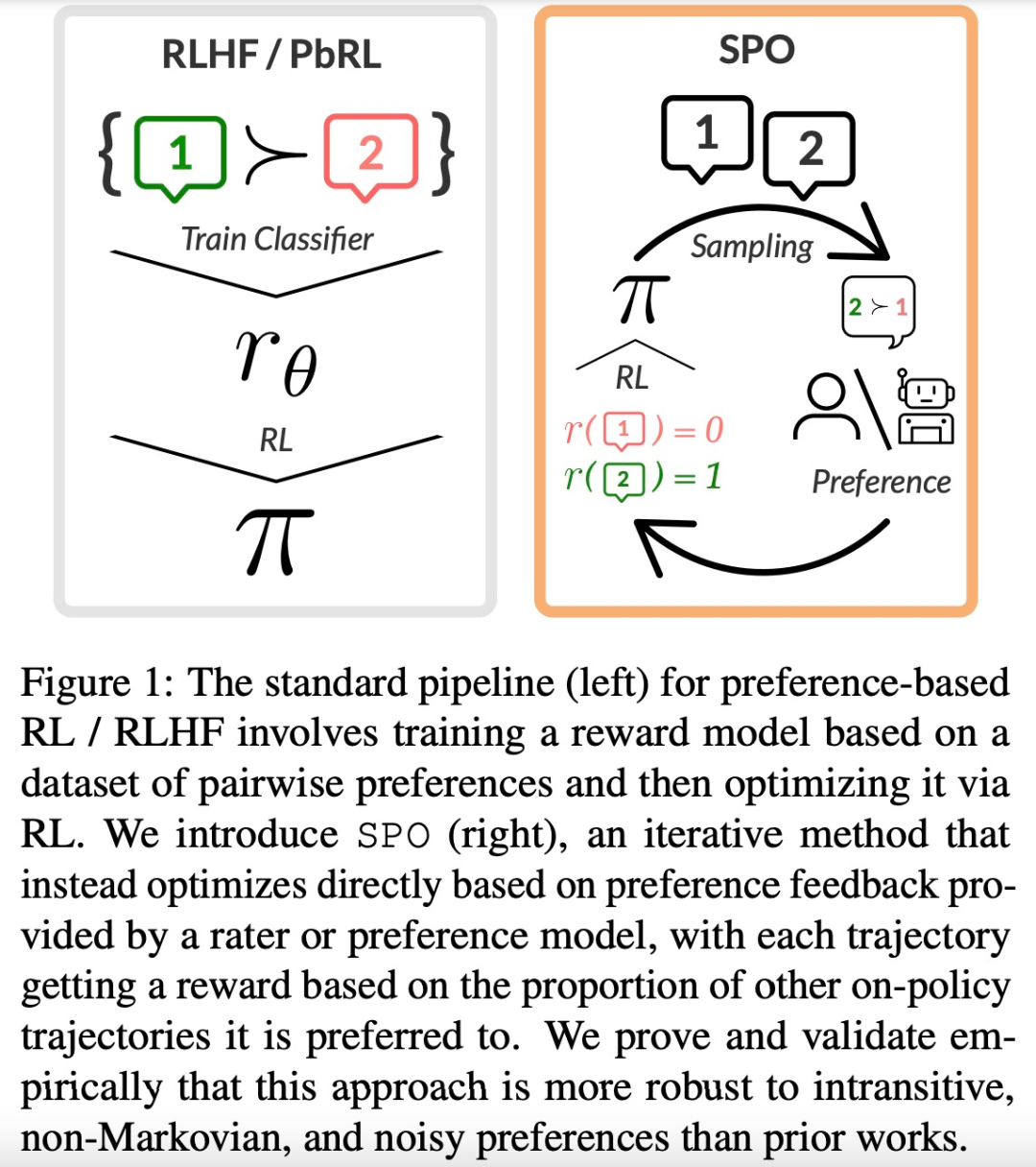
谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
来自主题: AI技术研报
5874 点击 2024-02-10 13:02
 搜索
搜索
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。

2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。

生成式AI的诞生,为芯片设计开启了另一条路。现在不论是英伟达等科技公司,还是学术界,都在试图研发出能够完全自主设计芯片的AI系统。
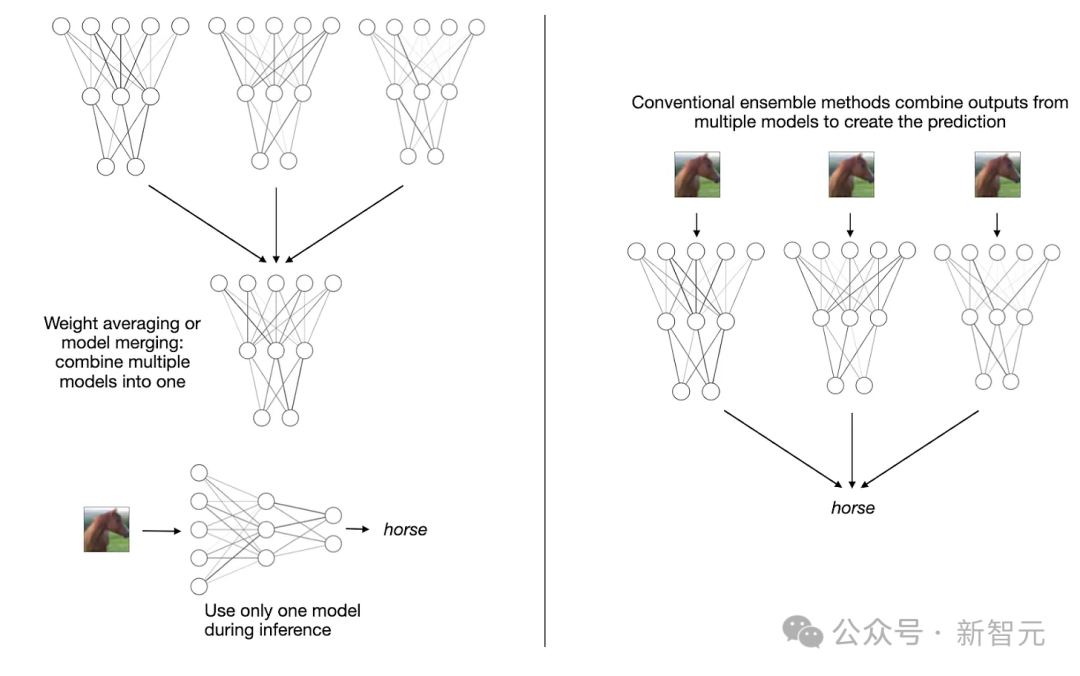
AI大模型并非越大越好?过去一个月,关于大模型变小的研究成为亮点,通过模型合并,采用MoE架构都能实现小模型高性能。

高水平国际科技杂志《New Scientist》报道称,“兵棋推演”重复模拟的结果显示,OpenAI最强的人工智能(AI)模型会选择发动核打击。

去年 6 月,JetBrains 宣布所有基于 IntelliJ 的 IDE 和 .NET 工具都将集成一个新功能:AI 助手(AI Assistant)——该功能由 JetBrains AI 服务提供支持,可连接不同的大语言模型(LLM),并表示会将它整合到 IDE 的核心工作流中。
上月初,Perplexity 完成了 B 轮融资,最新估值为 5.2 亿美元,这轮融资由 IVP 领投,NVIDIA 和 Jeff Bezos、NEA、Elad Gil、Nat Friedman 等跟投,Perplexity 的累计融资额超过了 1 亿美元,创下了近年搜索领域初创公司的融资金额纪录。

今天,穆罕默德・本・扎耶德人工智能大学 VILA Lab 带来了一项关于如何更好地为不同规模的大模型书写提示词(prompt)的研究,让大模型性能在不需要任何额外训练的前提下轻松提升 50% 以上。该工作在 X (Twitter)、Reddit 和 LinkedIn 等平台上都引起了广泛的讨论和关注。
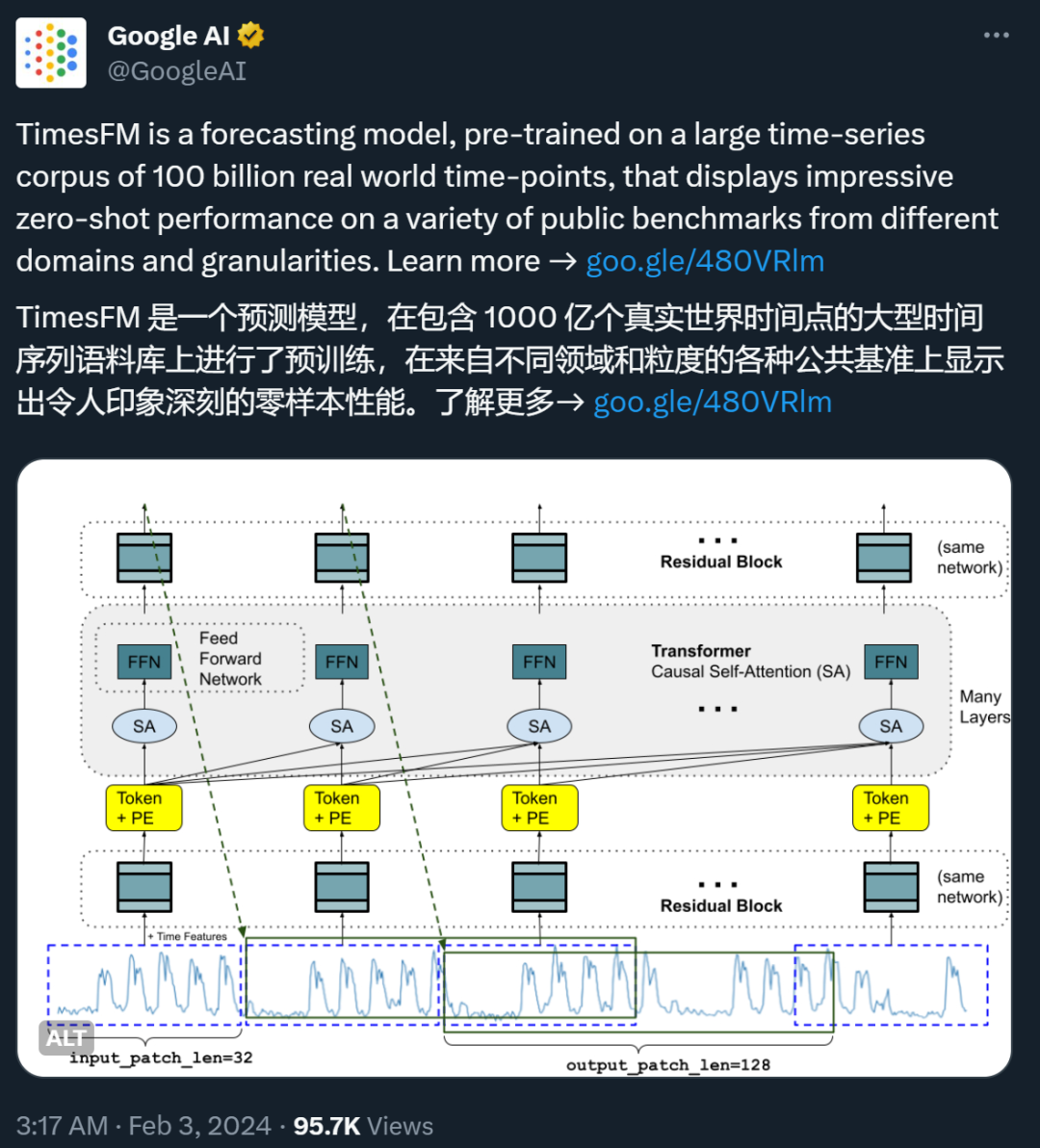
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。

分手8个月想挽回,女友却爱上了AI男友,怎么破?这位美国博士小哥选择用错误数据毒害模型,训成一个妥妥的负分男友,结果,女友果真来找他了……